 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Do You Listen with One or Two Microphones? A Unified ASR Model for Single and Multi-Channel Audio
Jun 28, 2021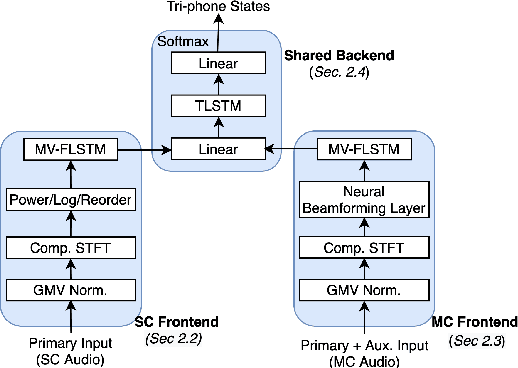
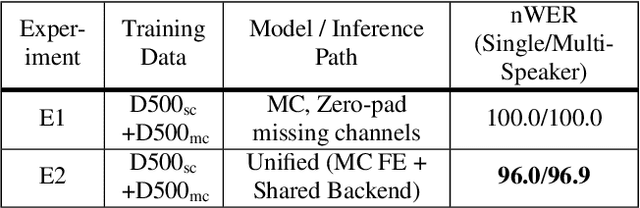
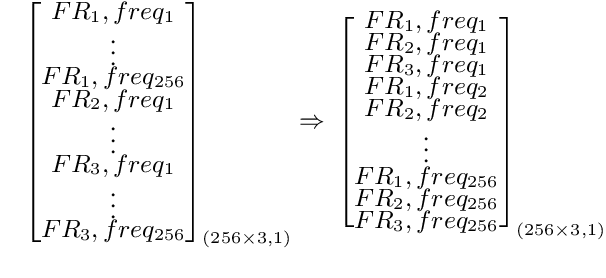
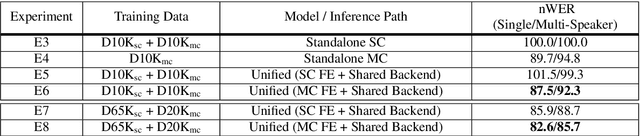
Automatic speech recognition (ASR) models are typically designed to operate on a single input data type, e.g. a single or multi-channel audio streamed from a device. This design decision assumes the primary input data source does not change and if an additional (auxiliary) data source is occasionally available, it cannot be used. An ASR model that operates on both primary and auxiliary data can achieve better accuracy compared to a primary-only solution; and a model that can serve both primary-only (PO) and primary-plus-auxiliary (PPA) modes is highly desirable. In this work, we propose a unified ASR model that can serve both modes. We demonstrate its efficacy in a realistic scenario where a set of devices typically stream a single primary audio channel, and two additional auxiliary channels only when upload bandwidth allows it. The architecture enables a unique methodology that uses both types of input audio during training time. Our proposed approach achieves up to 12.5% relative word-error-rate reduction (WERR) compared to a PO baseline, and up to 16.0% relative WERR in low-SNR conditions. The unique training methodology achieves up to 2.5% relative WERR compared to a PPA baseline.
Attention-based Neural Beamforming Layers for Multi-channel Speech Recognition
May 14, 2021

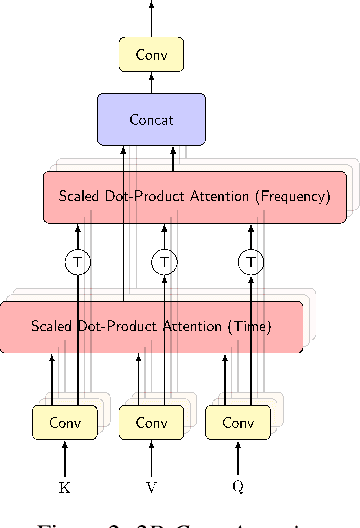

Attention-based beamformers have recently been shown to be effective for multi-channel speech recognition. However, they are less capable at capturing local information. In this work, we propose a 2D Conv-Attention module which combines convolution neural networks with attention for beamforming. We apply self- and cross-attention to explicitly model the correlations within and between the input channels. The end-to-end 2D Conv-Attention model is compared with a multi-head self-attention and superdirective-based neural beamformers. We train and evaluate on an in-house multi-channel dataset. The results show a relative improvement of 3.8% in WER by the proposed model over the baseline neural beamformer.
REDAT: Accent-Invariant Representation for End-to-End ASR by Domain Adversarial Training with Relabeling
Dec 14, 2020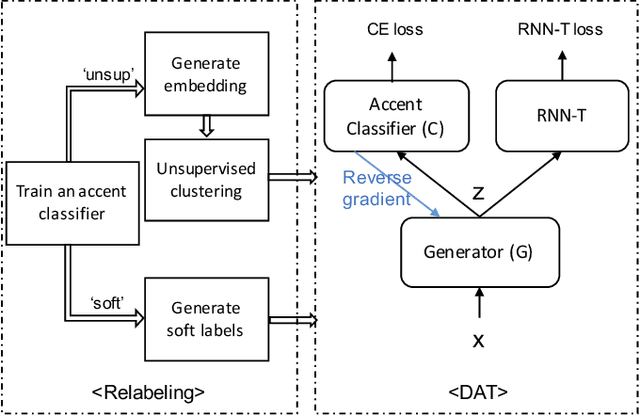
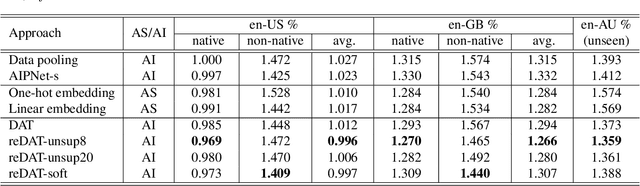
Accents mismatching is a critical problem for end-to-end ASR. This paper aims to address this problem by building an accent-robust RNN-T system with domain adversarial training (DAT). We unveil the magic behind DAT and provide, for the first time, a theoretical guarantee that DAT learns accent-invariant representations. We also prove that performing the gradient reversal in DAT is equivalent to minimizing the Jensen-Shannon divergence between domain output distributions. Motivated by the proof of equivalence, we introduce reDAT, a novel technique based on DAT, which relabels data using either unsupervised clustering or soft labels. Experiments on 23K hours of multi-accent data show that DAT achieves competitive results over accent-specific baselines on both native and non-native English accents but up to 13% relative WER reduction on unseen accents; our reDAT yields further improvements over DAT by 3% and 8% relatively on non-native accents of American and British English.
Semi-supervised voice conversion with amortized variational inference
Sep 30, 2019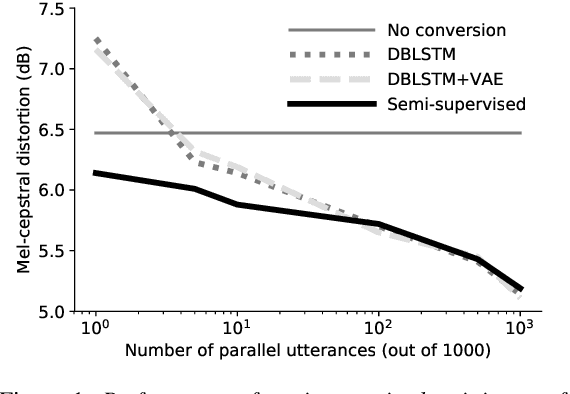

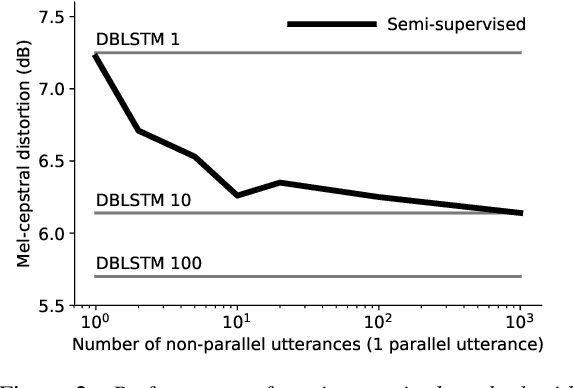
In this work we introduce a semi-supervised approach to the voice conversion problem, in which speech from a source speaker is converted into speech of a target speaker. The proposed method makes use of both parallel and non-parallel utterances from the source and target simultaneously during training. This approach can be used to extend existing parallel data voice conversion systems such that they can be trained with semi-supervision. We show that incorporating semi-supervision improves the voice conversion performance compared to fully supervised training when the number of parallel utterances is limited as in many practical applications. Additionally, we find that increasing the number non-parallel utterances used in training continues to improve performance when the amount of parallel training data is held constant.
* Accepted for publication at Interspeech 2019
Improving Branch Prediction By Modeling Global History with Convolutional Neural Networks
Jun 20, 2019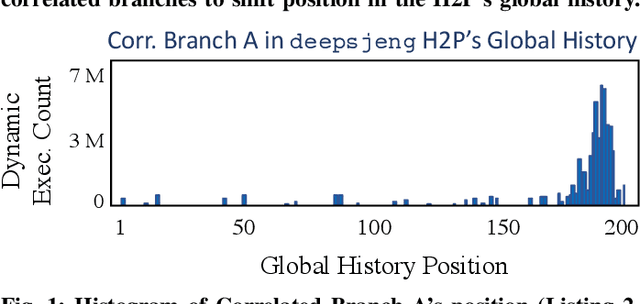

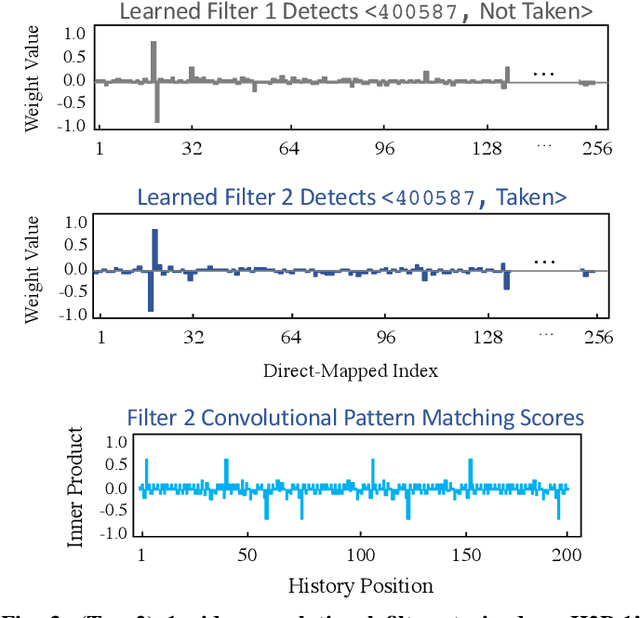
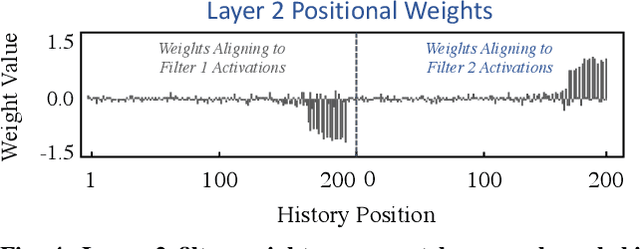
CPU branch prediction has hit a wall--existing techniques achieve near-perfect accuracy on 99% of static branches, and yet the mispredictions that remain hide major performance gains. In a companion report, we show that a primary source of mispredictions is a handful of systematically hard-to-predict branches (H2Ps), e.g. just 10 static instructions per SimPoint phase in SPECint 2017. The lost opportunity posed by these mispredictions is significant to the CPU: 14.0% in instructions-per-cycle (IPC) on Intel SkyLake and 37.4% IPC when the pipeline is scaled four-fold, on par with gains from process technology. However, up to 80% of this upside is unreachable by the best known branch predictors, even when afforded exponentially more resources. New approaches are needed, and machine learning (ML) provides a palette of powerful predictors. A growing body of work has shown that ML models are deployable within the microarchitecture to optimize hardware at runtime, and are one way to customize CPUs post-silicon by training to customer applications. We develop this scenario for branch prediction using convolutional neural networks (CNNs) to boost accuracy for H2Ps. Step-by-step, we (1) map CNNs to the global history data used by existing branch predictors; (2) show how CNNs improve H2P prediction in SPEC 2017; (3) adapt 2-bit CNN inference to the constraints of current branch prediction units; and (4) establish that CNN helper predictors are reusable across application executions on different inputs, enabling us to amortize offline training and deploy ML pattern matching to improve IPC.
Semi-supervised and Population Based Training for Voice Commands Recognition
May 10, 2019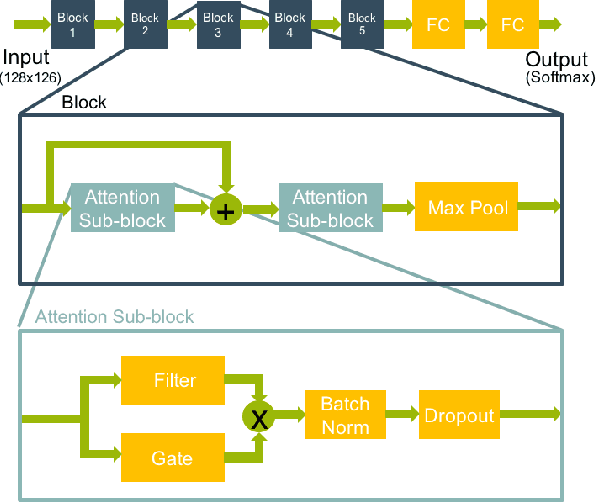
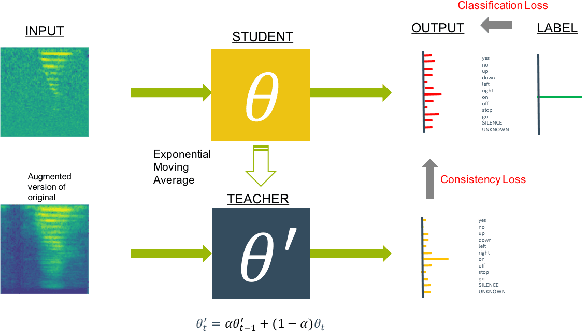
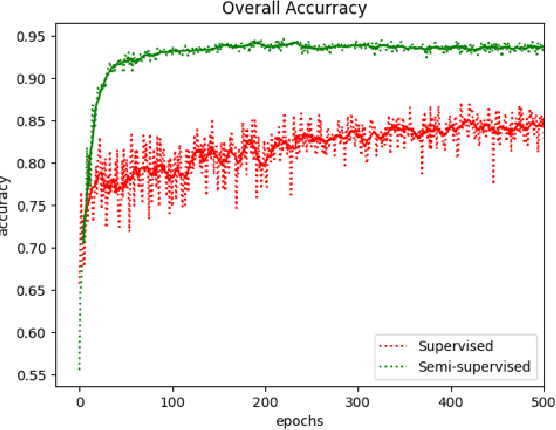
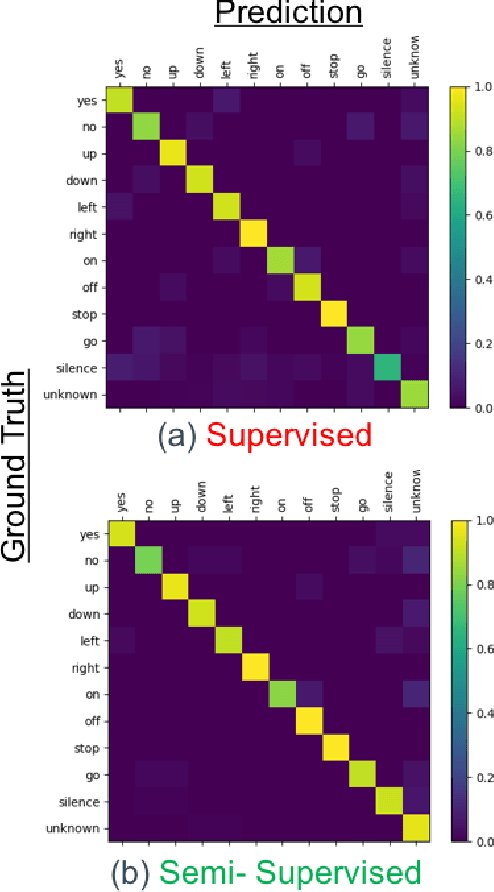
We present a rapid design methodology that combines automated hyper-parameter tuning with semi-supervised training to build highly accurate and robust models for voice commands classification. Proposed approach allows quick evaluation of network architectures to fit performance and power constraints of available hardware, while ensuring good hyper-parameter choices for each network in real-world scenarios. Leveraging the vast amount of unlabeled data with a student/teacher based semi-supervised method, classification accuracy is improved from 84% to 94% in the validation set. For model optimization, we explore the hyper-parameter space through population based training and obtain an optimized model in the same time frame as it takes to train a single model.
Adversarially Trained Autoencoders for Parallel-Data-Free Voice Conversion
May 09, 2019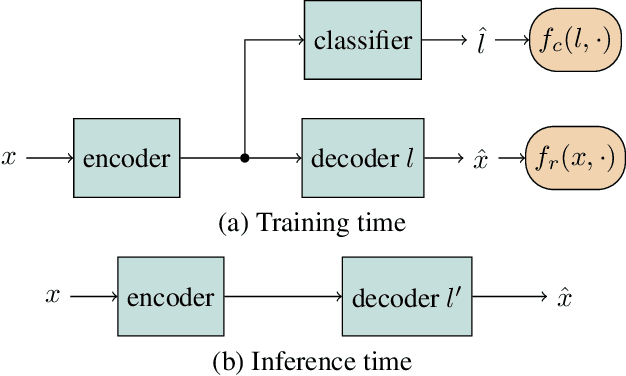
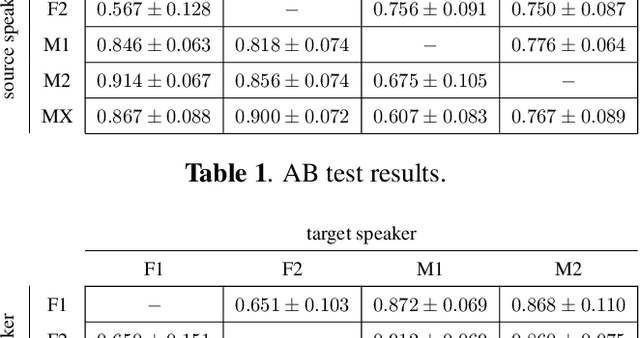
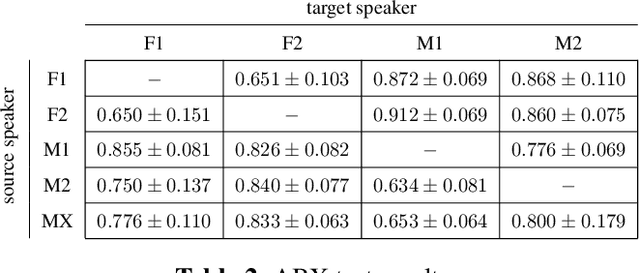
We present a method for converting the voices between a set of speakers. Our method is based on training multiple autoencoder paths, where there is a single speaker-independent encoder and multiple speaker-dependent decoders. The autoencoders are trained with an addition of an adversarial loss which is provided by an auxiliary classifier in order to guide the output of the encoder to be speaker independent. The training of the model is unsupervised in the sense that it does not require collecting the same utterances from the speakers nor does it require time aligning over phonemes. Due to the use of a single encoder, our method can generalize to converting the voice of out-of-training speakers to speakers in the training dataset. We present subjective tests corroborating the performance of our method.
Many-to-Many Voice Conversion with Out-of-Dataset Speaker Support
Apr 30, 2019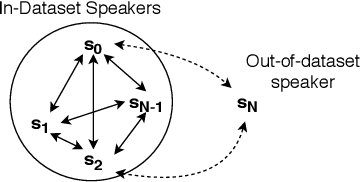
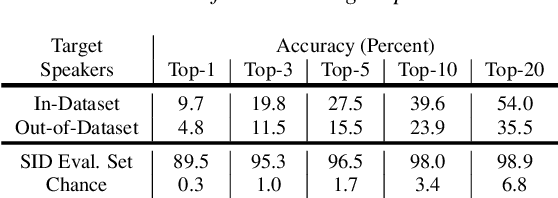
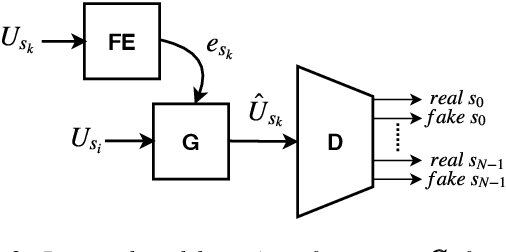

We present a Cycle-GAN based many-to-many voice conversion method that can convert between speakers that are not in the training set. This property is enabled through speaker embeddings generated by a neural network that is jointly trained with the Cycle-GAN. In contrast to prior work in this domain, our method enables conversion between an out-of-dataset speaker and a target speaker in either direction and does not require re-training. Out-of-dataset speaker conversion quality is evaluated using an independently trained speaker identification model, and shows good style conversion characteristics for previously unheard speakers. Subjective tests on human listeners show style conversion quality for in-dataset speakers is comparable to the state-of-the-art baseline model.