 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurn-taking and Backchannel Prediction with Acoustic and Large Language Model Fusion
Jan 26, 2024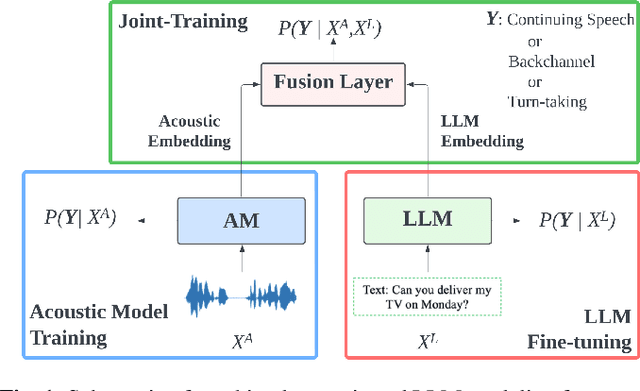
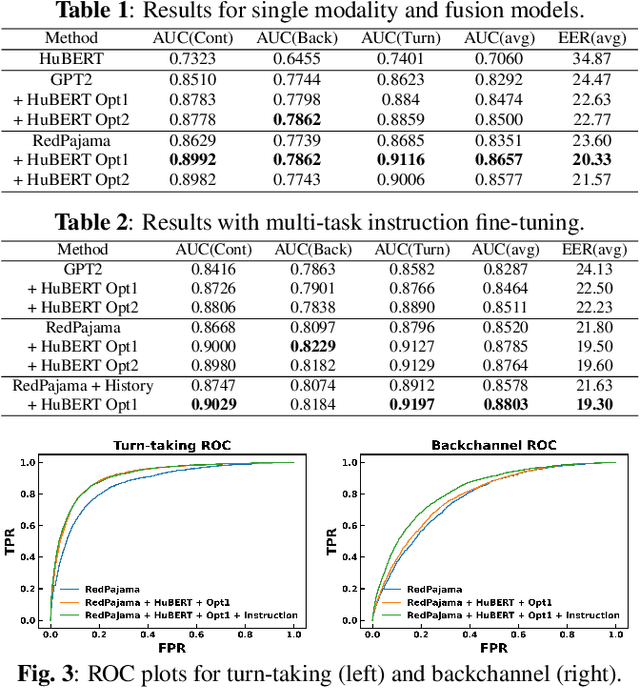
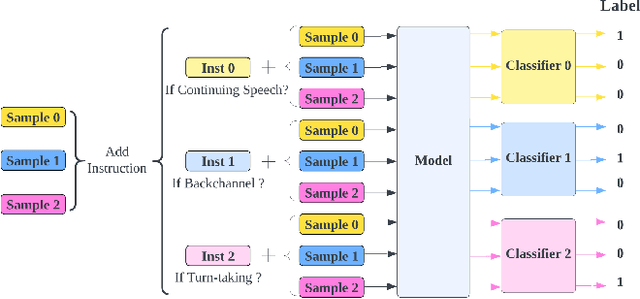
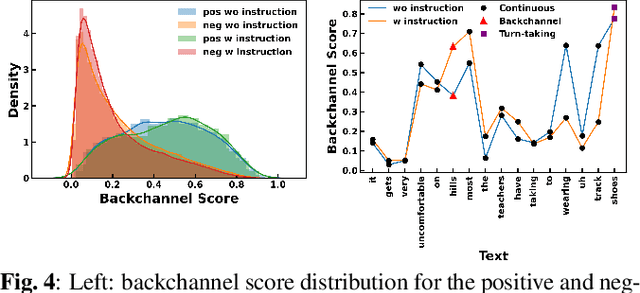
We propose an approach for continuous prediction of turn-taking and backchanneling locations in spoken dialogue by fusing a neural acoustic model with a large language model (LLM). Experiments on the Switchboard human-human conversation dataset demonstrate that our approach consistently outperforms the baseline models with single modality. We also develop a novel multi-task instruction fine-tuning strategy to further benefit from LLM-encoded knowledge for understanding the tasks and conversational contexts, leading to additional improvements. Our approach demonstrates the potential of combined LLMs and acoustic models for a more natural and conversational interaction between humans and speech-enabled AI agents.
Do You Listen with One or Two Microphones? A Unified ASR Model for Single and Multi-Channel Audio
Jun 28, 2021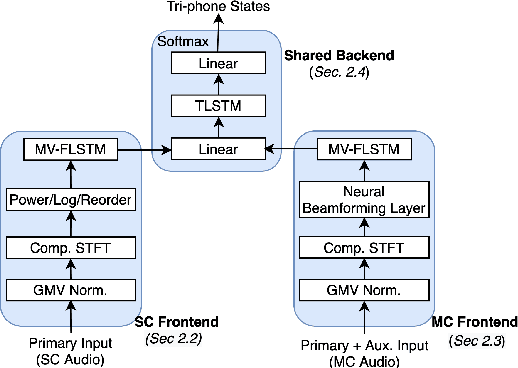
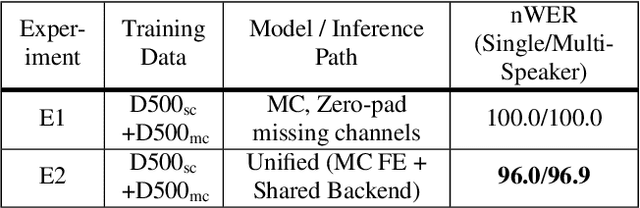
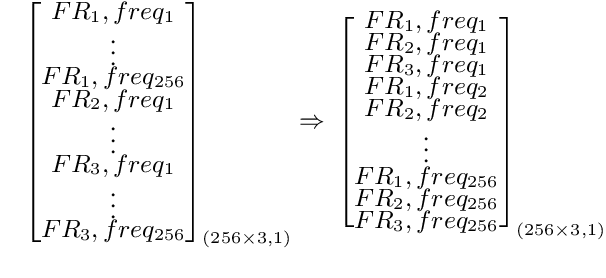
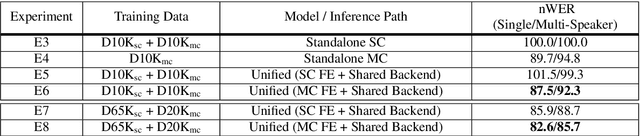
Automatic speech recognition (ASR) models are typically designed to operate on a single input data type, e.g. a single or multi-channel audio streamed from a device. This design decision assumes the primary input data source does not change and if an additional (auxiliary) data source is occasionally available, it cannot be used. An ASR model that operates on both primary and auxiliary data can achieve better accuracy compared to a primary-only solution; and a model that can serve both primary-only (PO) and primary-plus-auxiliary (PPA) modes is highly desirable. In this work, we propose a unified ASR model that can serve both modes. We demonstrate its efficacy in a realistic scenario where a set of devices typically stream a single primary audio channel, and two additional auxiliary channels only when upload bandwidth allows it. The architecture enables a unique methodology that uses both types of input audio during training time. Our proposed approach achieves up to 12.5% relative word-error-rate reduction (WERR) compared to a PO baseline, and up to 16.0% relative WERR in low-SNR conditions. The unique training methodology achieves up to 2.5% relative WERR compared to a PPA baseline.
Attention-based Neural Beamforming Layers for Multi-channel Speech Recognition
May 14, 2021

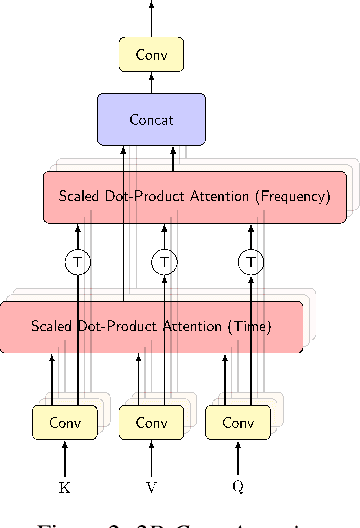

Attention-based beamformers have recently been shown to be effective for multi-channel speech recognition. However, they are less capable at capturing local information. In this work, we propose a 2D Conv-Attention module which combines convolution neural networks with attention for beamforming. We apply self- and cross-attention to explicitly model the correlations within and between the input channels. The end-to-end 2D Conv-Attention model is compared with a multi-head self-attention and superdirective-based neural beamformers. We train and evaluate on an in-house multi-channel dataset. The results show a relative improvement of 3.8% in WER by the proposed model over the baseline neural beamformer.
Listen with Intent: Improving Speech Recognition with Audio-to-Intent Front-End
May 14, 2021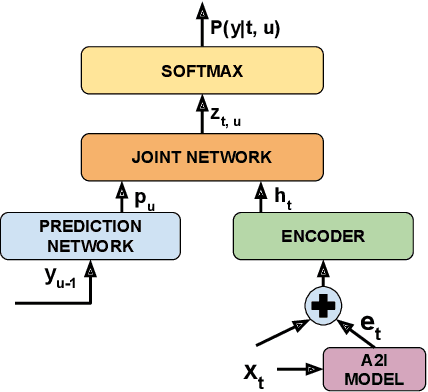
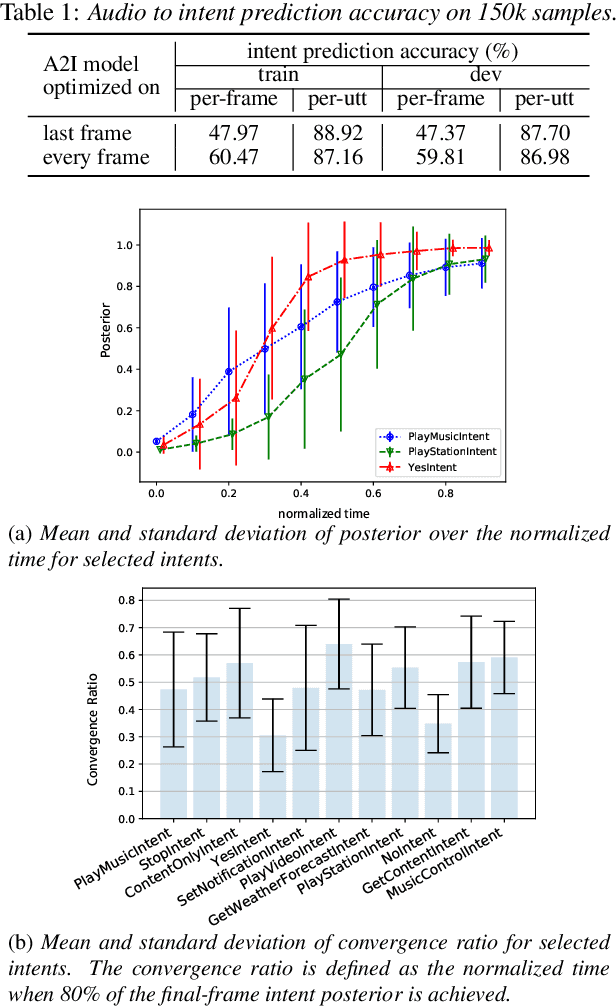
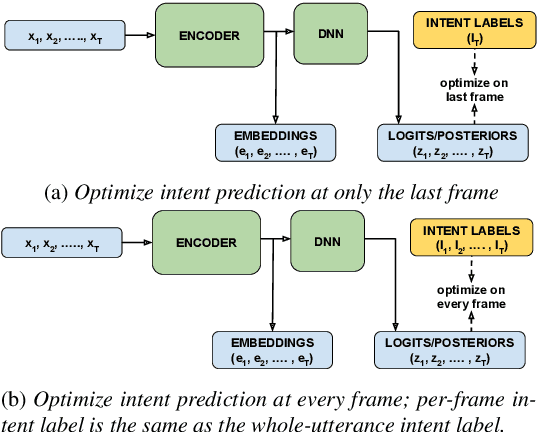
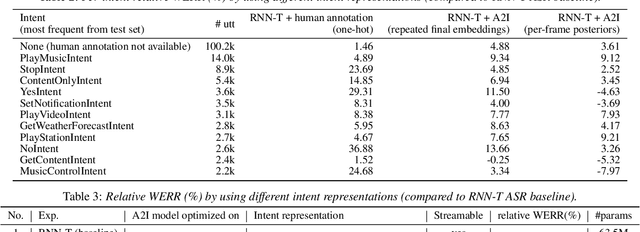
Comprehending the overall intent of an utterance helps a listener recognize the individual words spoken. Inspired by this fact, we perform a novel study of the impact of explicitly incorporating intent representations as additional information to improve a recurrent neural network-transducer (RNN-T) based automatic speech recognition (ASR) system. An audio-to-intent (A2I) model encodes the intent of the utterance in the form of embeddings or posteriors, and these are used as auxiliary inputs for RNN-T training and inference. Experimenting with a 50k-hour far-field English speech corpus, this study shows that when running the system in non-streaming mode, where intent representation is extracted from the entire utterance and then used to bias streaming RNN-T search from the start, it provides a 5.56% relative word error rate reduction (WERR). On the other hand, a streaming system using per-frame intent posteriors as extra inputs for the RNN-T ASR system yields a 3.33% relative WERR. A further detailed analysis of the streaming system indicates that our proposed method brings especially good gain on media-playing related intents (e.g. 9.12% relative WERR on PlayMusicIntent).
Wav2vec-C: A Self-supervised Model for Speech Representation Learning
Mar 09, 2021

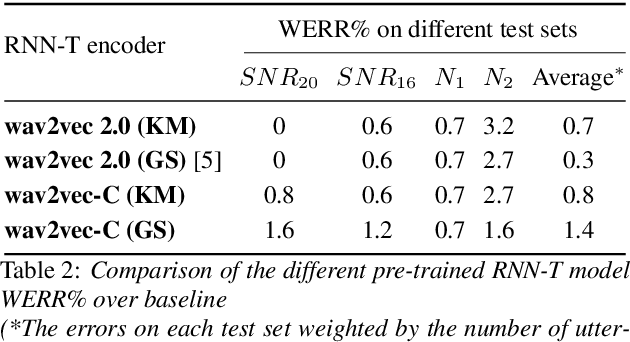
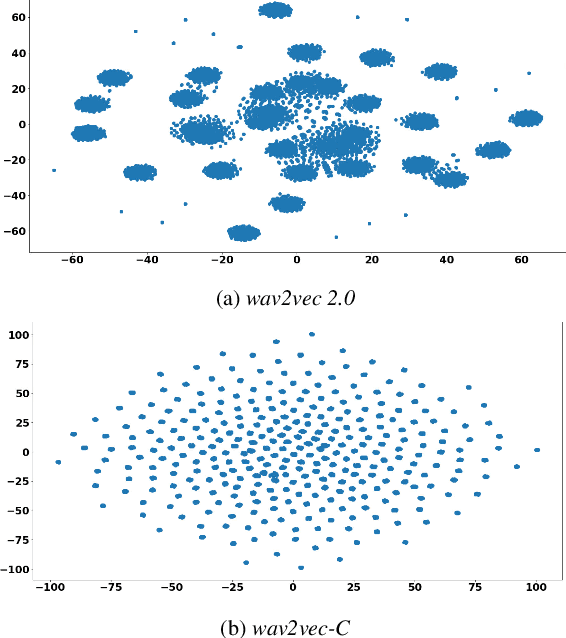
Wav2vec-C introduces a novel representation learning technique combining elements from wav2vec 2.0 and VQ-VAE. Our model learns to reproduce quantized representations from partially masked speech encoding using a contrastive loss in a way similar to Wav2vec 2.0. However, the quantization process is regularized by an additional consistency network that learns to reconstruct the input features to the wav2vec 2.0 network from the quantized representations in a way similar to a VQ-VAE model. The proposed self-supervised model is trained on 10k hours of unlabeled data and subsequently used as the speech encoder in a RNN-T ASR model and fine-tuned with 1k hours of labeled data. This work is one of only a few studies of self-supervised learning on speech tasks with a large volume of real far-field labeled data. The Wav2vec-C encoded representations achieves, on average, twice the error reduction over baseline and a higher codebook utilization in comparison to wav2vec 2.0
Robust Multi-channel Speech Recognition using Frequency Aligned Network
Feb 06, 2020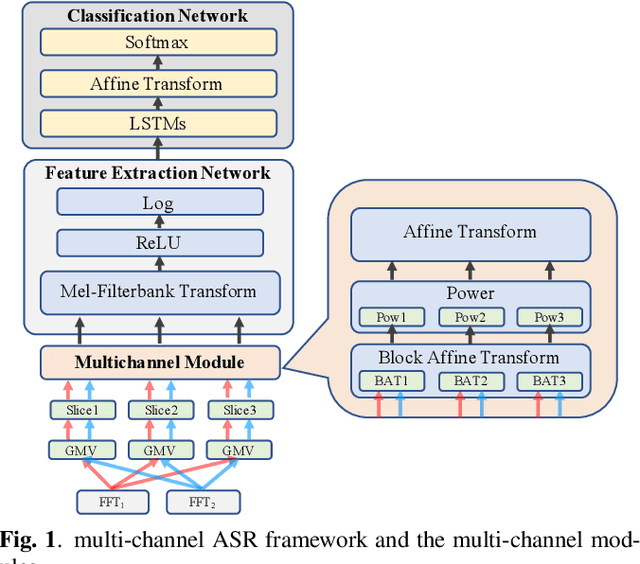
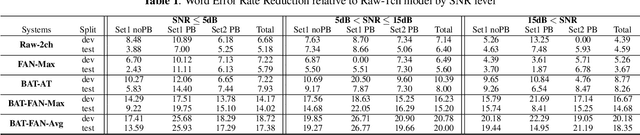
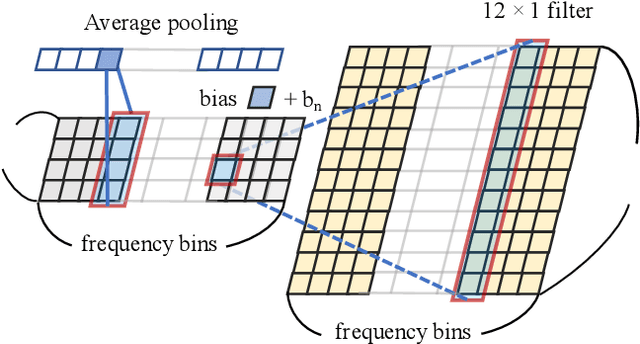

Conventional speech enhancement technique such as beamforming has known benefits for far-field speech recognition. Our own work in frequency-domain multi-channel acoustic modeling has shown additional improvements by training a spatial filtering layer jointly within an acoustic model. In this paper, we further develop this idea and use frequency aligned network for robust multi-channel automatic speech recognition (ASR). Unlike an affine layer in the frequency domain, the proposed frequency aligned component prevents one frequency bin influencing other frequency bins. We show that this modification not only reduces the number of parameters in the model but also significantly and improves the ASR performance. We investigate effects of frequency aligned network through ASR experiments on the real-world far-field data where users are interacting with an ASR system in uncontrolled acoustic environments. We show that our multi-channel acoustic model with a frequency aligned network shows up to 18% relative reduction in word error rate.
Fully Learnable Front-End for Multi-Channel Acoustic Modeling using Semi-Supervised Learning
Feb 01, 2020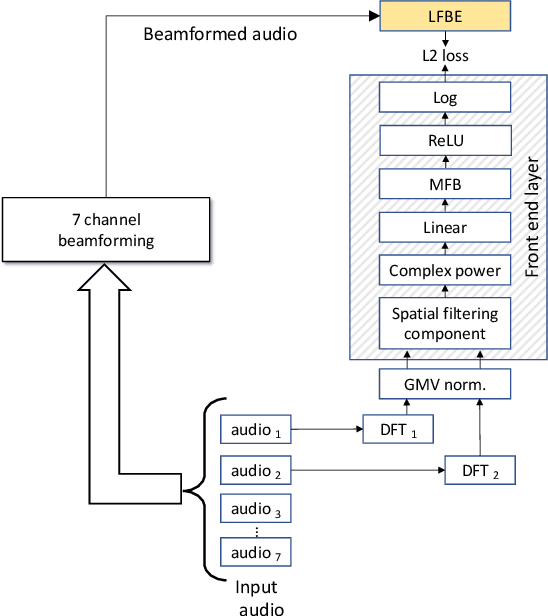
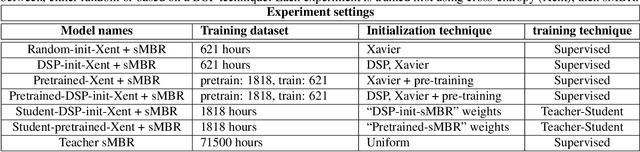
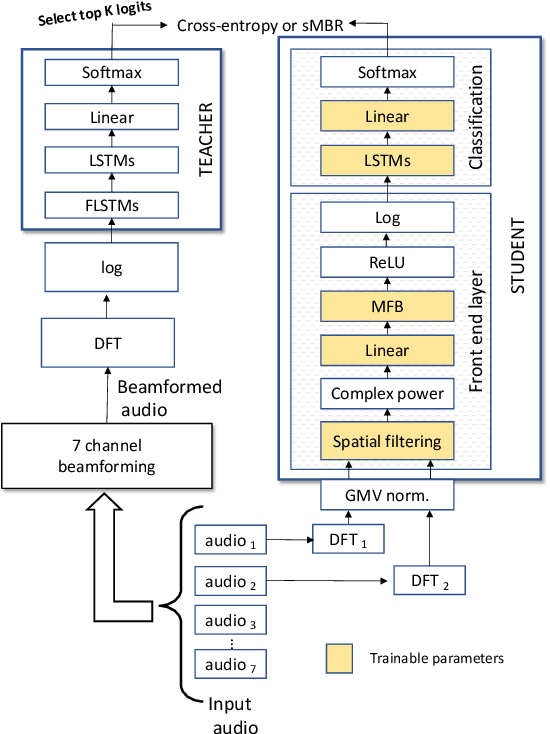

In this work, we investigated the teacher-student training paradigm to train a fully learnable multi-channel acoustic model for far-field automatic speech recognition (ASR). Using a large offline teacher model trained on beamformed audio, we trained a simpler multi-channel student acoustic model used in the speech recognition system. For the student, both multi-channel feature extraction layers and the higher classification layers were jointly trained using the logits from the teacher model. In our experiments, compared to a baseline model trained on about 600 hours of transcribed data, a relative word-error rate (WER) reduction of about 27.3% was achieved when using an additional 1800 hours of untranscribed data. We also investigated the benefit of pre-training the multi-channel front end to output the beamformed log-mel filter bank energies (LFBE) using L2 loss. We find that pre-training improves the word error rate by 10.7% when compared to a multi-channel model directly initialized with a beamformer and mel-filter bank coefficients for the front end. Finally, combining pre-training and teacher-student training produces a WER reduction of 31% compared to our baseline.
Improving noise robustness of automatic speech recognition via parallel data and teacher-student learning
Jan 11, 2019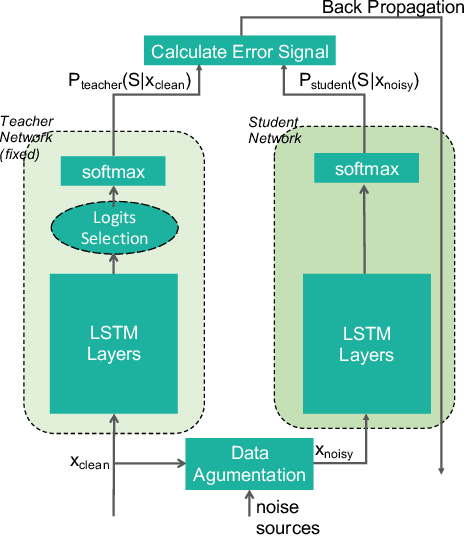
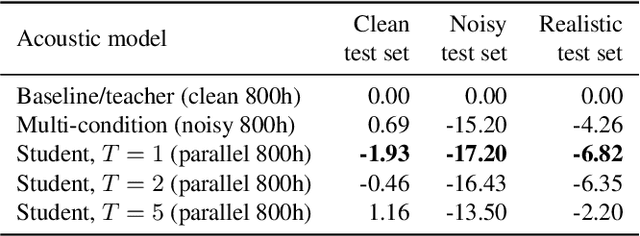
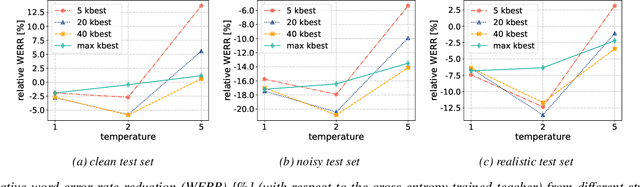
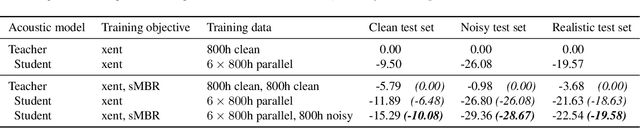
For real-world speech recognition applications, noise robustness is still a challenge. In this work, we adopt the teacher-student (T/S) learning technique using a parallel clean and noisy corpus for improving automatic speech recognition (ASR) performance under multimedia noise. On top of that, we apply a logits selection method which only preserves the k highest values to prevent wrong emphasis of knowledge from the teacher and to reduce bandwidth needed for transferring data. We incorporate up to 8000 hours of untranscribed data for training and present our results on sequence trained models apart from cross entropy trained ones. The best sequence trained student model yields relative word error rate (WER) reductions of approximately 10.1%, 28.7% and 19.6% on our clean, simulated noisy and real test sets respectively comparing to a sequence trained teacher.