 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWav2vec-C: A Self-supervised Model for Speech Representation Learning
Mar 09, 2021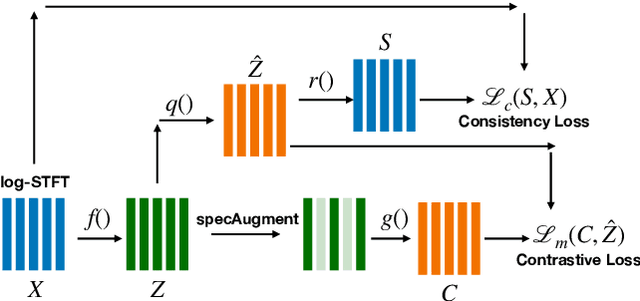

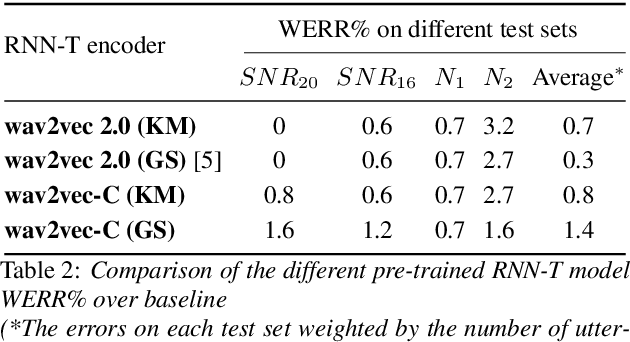
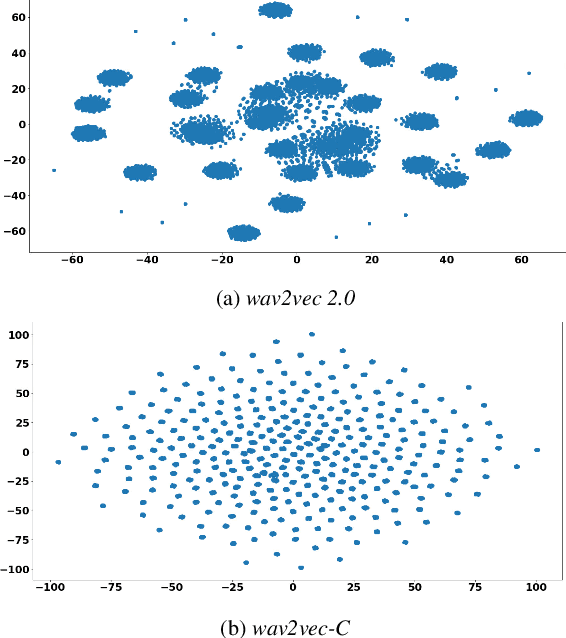
Wav2vec-C introduces a novel representation learning technique combining elements from wav2vec 2.0 and VQ-VAE. Our model learns to reproduce quantized representations from partially masked speech encoding using a contrastive loss in a way similar to Wav2vec 2.0. However, the quantization process is regularized by an additional consistency network that learns to reconstruct the input features to the wav2vec 2.0 network from the quantized representations in a way similar to a VQ-VAE model. The proposed self-supervised model is trained on 10k hours of unlabeled data and subsequently used as the speech encoder in a RNN-T ASR model and fine-tuned with 1k hours of labeled data. This work is one of only a few studies of self-supervised learning on speech tasks with a large volume of real far-field labeled data. The Wav2vec-C encoded representations achieves, on average, twice the error reduction over baseline and a higher codebook utilization in comparison to wav2vec 2.0
Multi-Stream End-to-End Speech Recognition
Jun 17, 2019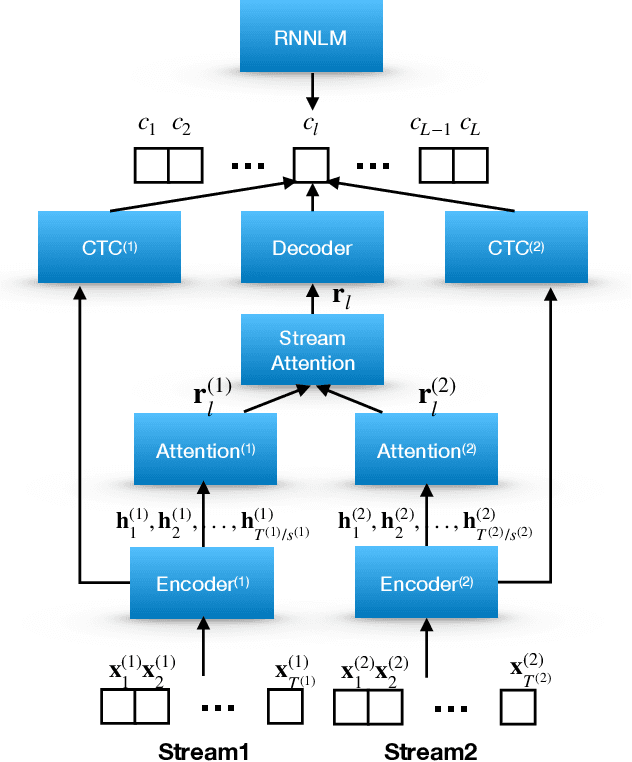
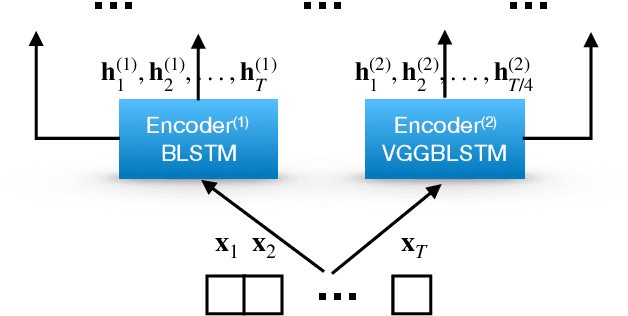
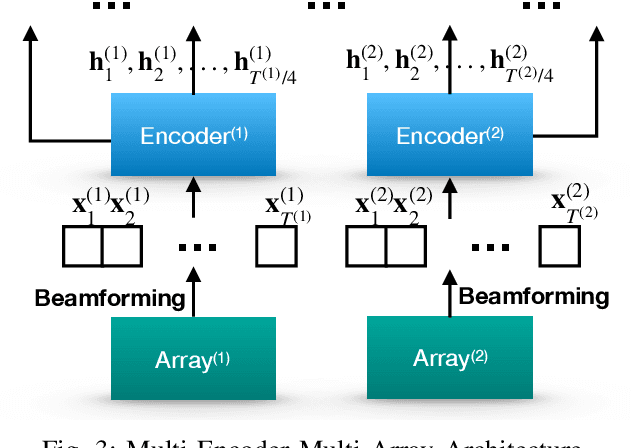
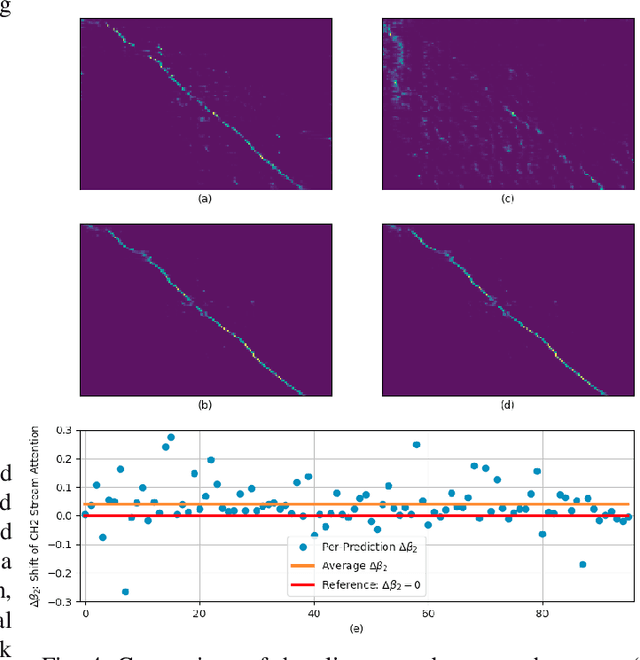
Attention-based methods and Connectionist Temporal Classification (CTC) network have been promising research directions for end-to-end (E2E) Automatic Speech Recognition (ASR). The joint CTC/Attention model has achieved great success by utilizing both architectures during multi-task training and joint decoding. In this work, we present a multi-stream framework based on joint CTC/Attention E2E ASR with parallel streams represented by separate encoders aiming to capture diverse information. On top of the regular attention networks, the Hierarchical Attention Network (HAN) is introduced to steer the decoder toward the most informative encoders. A separate CTC network is assigned to each stream to force monotonic alignments. Two representative framework have been proposed and discussed, which are Multi-Encoder Multi-Resolution (MEM-Res) framework and Multi-Encoder Multi-Array (MEM-Array) framework, respectively. In MEM-Res framework, two heterogeneous encoders with different architectures, temporal resolutions and separate CTC networks work in parallel to extract complimentary information from same acoustics. Experiments are conducted on Wall Street Journal (WSJ) and CHiME-4, resulting in relative Word Error Rate (WER) reduction of 18.0-32.1% and the best WER of 3.6% in the WSJ eval92 test set. The MEM-Array framework aims at improving the far-field ASR robustness using multiple microphone arrays which are activated by separate encoders. Compared with the best single-array results, the proposed framework has achieved relative WER reduction of 3.7% and 9.7% in AMI and DIRHA multi-array corpora, respectively, which also outperforms conventional fusion strategies.
Multi-encoder multi-resolution framework for end-to-end speech recognition
Nov 12, 2018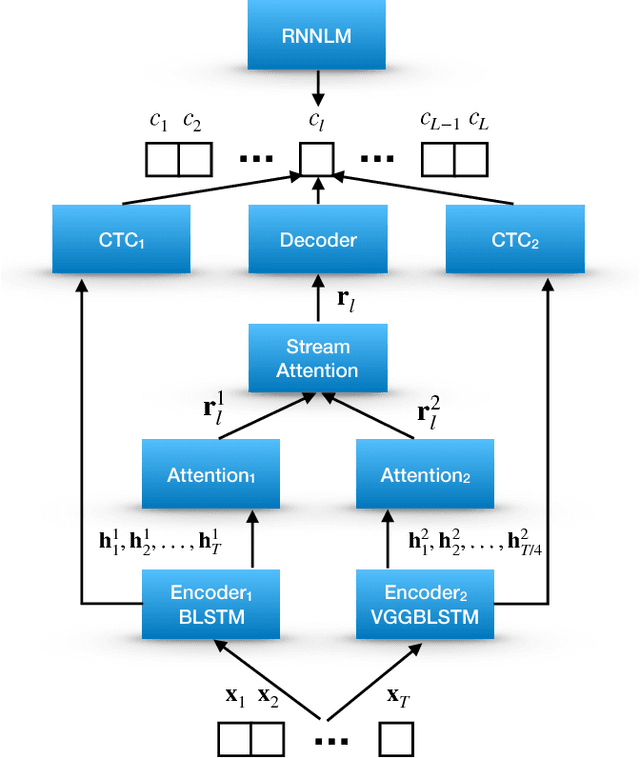



Attention-based methods and Connectionist Temporal Classification (CTC) network have been promising research directions for end-to-end Automatic Speech Recognition (ASR). The joint CTC/Attention model has achieved great success by utilizing both architectures during multi-task training and joint decoding. In this work, we present a novel Multi-Encoder Multi-Resolution (MEMR) framework based on the joint CTC/Attention model. Two heterogeneous encoders with different architectures, temporal resolutions and separate CTC networks work in parallel to extract complimentary acoustic information. A hierarchical attention mechanism is then used to combine the encoder-level information. To demonstrate the effectiveness of the proposed model, experiments are conducted on Wall Street Journal (WSJ) and CHiME-4, resulting in relative Word Error Rate (WER) reduction of 18.0-32.1%. Moreover, the proposed MEMR model achieves 3.6% WER in the WSJ eval92 test set, which is the best WER reported for an end-to-end system on this benchmark.
Device-directed Utterance Detection
Aug 07, 2018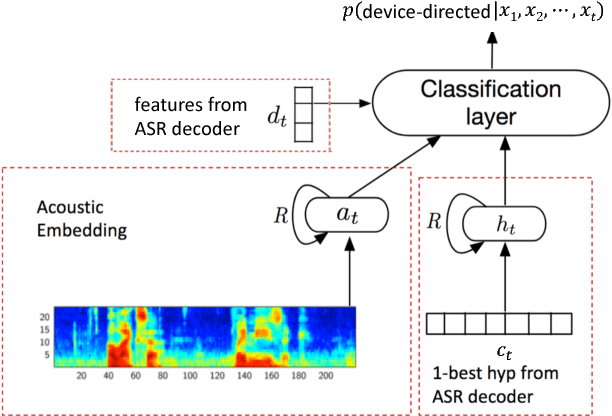
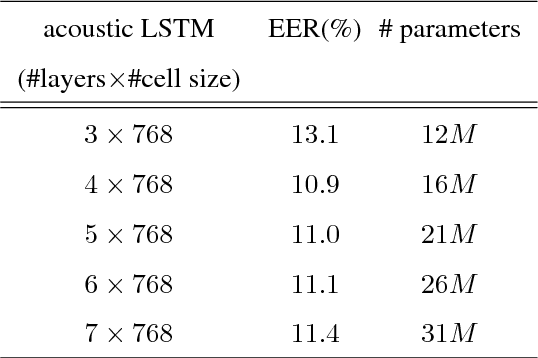
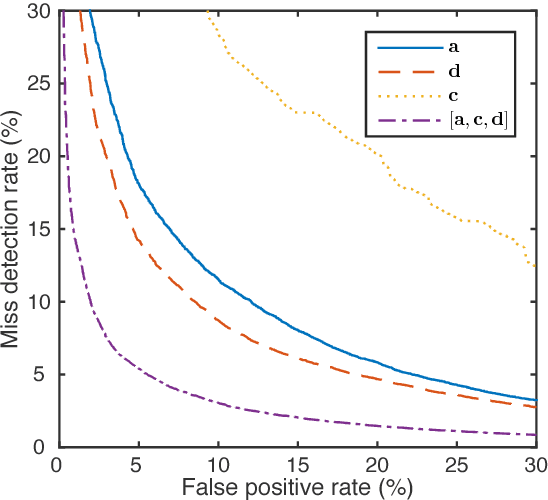
In this work, we propose a classifier for distinguishing device-directed queries from background speech in the context of interactions with voice assistants. Applications include rejection of false wake-ups or unintended interactions as well as enabling wake-word free follow-up queries. Consider the example interaction: $"Computer,~play~music", "Computer,~reduce~the~volume"$. In this interaction, the user needs to repeat the wake-word ($Computer$) for the second query. To allow for more natural interactions, the device could immediately re-enter listening state after the first query (without wake-word repetition) and accept or reject a potential follow-up as device-directed or background speech. The proposed model consists of two long short-term memory (LSTM) neural networks trained on acoustic features and automatic speech recognition (ASR) 1-best hypotheses, respectively. A feed-forward deep neural network (DNN) is then trained to combine the acoustic and 1-best embeddings, derived from the LSTMs, with features from the ASR decoder. Experimental results show that ASR decoder, acoustic embeddings, and 1-best embeddings yield an equal-error-rate (EER) of $9.3~\%$, $10.9~\%$ and $20.1~\%$, respectively. Combination of the features resulted in a $44~\%$ relative improvement and a final EER of $5.2~\%$.
On the Relevance of Auditory-Based Gabor Features for Deep Learning in Automatic Speech Recognition
Feb 14, 2017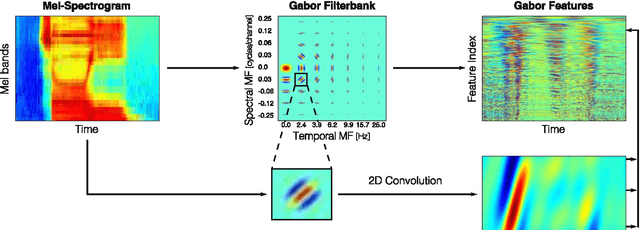
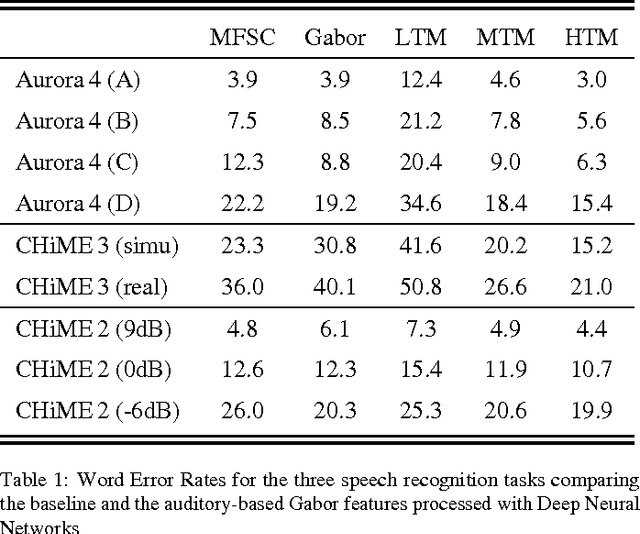
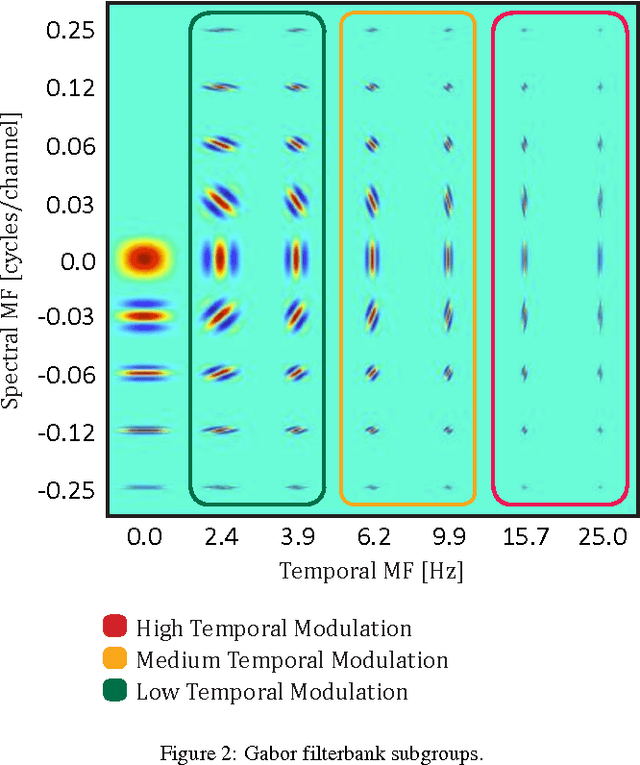

Previous studies support the idea of merging auditory-based Gabor features with deep learning architectures to achieve robust automatic speech recognition, however, the cause behind the gain of such combination is still unknown. We believe these representations provide the deep learning decoder with more discriminable cues. Our aim with this paper is to validate this hypothesis by performing experiments with three different recognition tasks (Aurora 4, CHiME 2 and CHiME 3) and assess the discriminability of the information encoded by Gabor filterbank features. Additionally, to identify the contribution of low, medium and high temporal modulation frequencies subsets of the Gabor filterbank were used as features (dubbed LTM, MTM and HTM respectively). With temporal modulation frequencies between 16 and 25 Hz, HTM consistently outperformed the remaining ones in every condition, highlighting the robustness of these representations against channel distortions, low signal-to-noise ratios and acoustically challenging real-life scenarios with relative improvements from 11 to 56% against a Mel-filterbank-DNN baseline. To explain the results, a measure of similarity between phoneme classes from DNN activations is proposed and linked to their acoustic properties. We find this measure to be consistent with the observed error rates and highlight specific differences on phoneme level to pinpoint the benefit of the proposed features.