 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevice-directed Utterance Detection
Paper and Code
Aug 07, 2018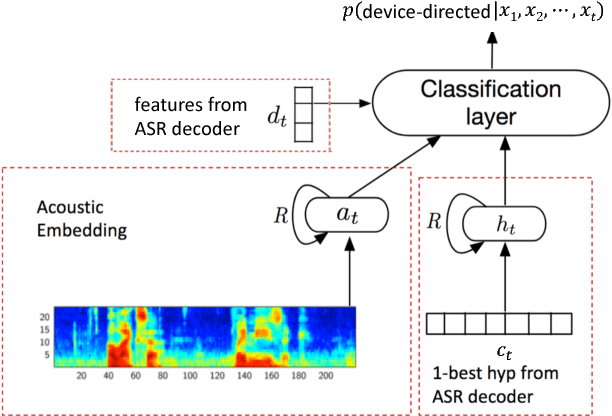
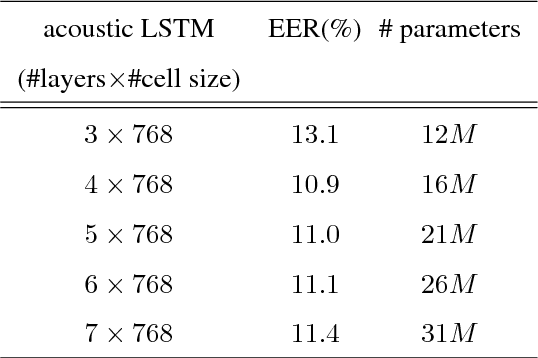
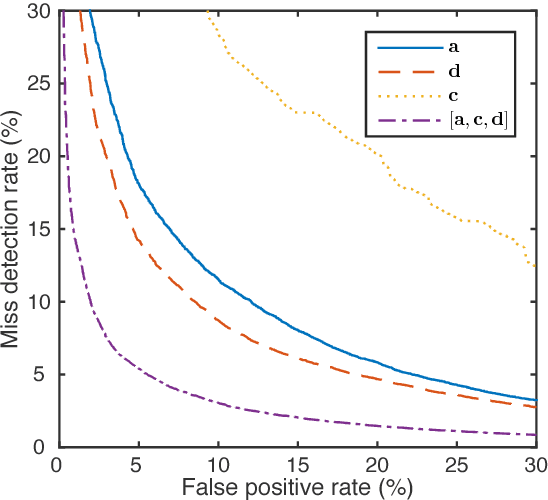
In this work, we propose a classifier for distinguishing device-directed queries from background speech in the context of interactions with voice assistants. Applications include rejection of false wake-ups or unintended interactions as well as enabling wake-word free follow-up queries. Consider the example interaction: $"Computer,~play~music", "Computer,~reduce~the~volume"$. In this interaction, the user needs to repeat the wake-word ($Computer$) for the second query. To allow for more natural interactions, the device could immediately re-enter listening state after the first query (without wake-word repetition) and accept or reject a potential follow-up as device-directed or background speech. The proposed model consists of two long short-term memory (LSTM) neural networks trained on acoustic features and automatic speech recognition (ASR) 1-best hypotheses, respectively. A feed-forward deep neural network (DNN) is then trained to combine the acoustic and 1-best embeddings, derived from the LSTMs, with features from the ASR decoder. Experimental results show that ASR decoder, acoustic embeddings, and 1-best embeddings yield an equal-error-rate (EER) of $9.3~\%$, $10.9~\%$ and $20.1~\%$, respectively. Combination of the features resulted in a $44~\%$ relative improvement and a final EER of $5.2~\%$.