 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Representation Learning for Automatic Speech Recognition
Aug 07, 2023



Federated Learning (FL) is a privacy-preserving paradigm, allowing edge devices to learn collaboratively without sharing data. Edge devices like Alexa and Siri are prospective sources of unlabeled audio data that can be tapped to learn robust audio representations. In this work, we bring Self-supervised Learning (SSL) and FL together to learn representations for Automatic Speech Recognition respecting data privacy constraints. We use the speaker and chapter information in the unlabeled speech dataset, Libri-Light, to simulate non-IID speaker-siloed data distributions and pre-train an LSTM encoder with the Contrastive Predictive Coding framework with FedSGD. We show that the pre-trained ASR encoder in FL performs as well as a centrally pre-trained model and produces an improvement of 12-15% (WER) compared to no pre-training. We further adapt the federated pre-trained models to a new language, French, and show a 20% (WER) improvement over no pre-training.
Federated Self-Learning with Weak Supervision for Speech Recognition
Jun 21, 2023



Automatic speech recognition (ASR) models with low-footprint are increasingly being deployed on edge devices for conversational agents, which enhances privacy. We study the problem of federated continual incremental learning for recurrent neural network-transducer (RNN-T) ASR models in the privacy-enhancing scheme of learning on-device, without access to ground truth human transcripts or machine transcriptions from a stronger ASR model. In particular, we study the performance of a self-learning based scheme, with a paired teacher model updated through an exponential moving average of ASR models. Further, we propose using possibly noisy weak-supervision signals such as feedback scores and natural language understanding semantics determined from user behavior across multiple turns in a session of interactions with the conversational agent. These signals are leveraged in a multi-task policy-gradient training approach to improve the performance of self-learning for ASR. Finally, we show how catastrophic forgetting can be mitigated by combining on-device learning with a memory-replay approach using selected historical datasets. These innovations allow for 10% relative improvement in WER on new use cases with minimal degradation on other test sets in the absence of strong-supervision signals such as ground-truth transcriptions.
Stutter-TTS: Controlled Synthesis and Improved Recognition of Stuttered Speech
Nov 04, 2022



Stuttering is a speech disorder where the natural flow of speech is interrupted by blocks, repetitions or prolongations of syllables, words and phrases. The majority of existing automatic speech recognition (ASR) interfaces perform poorly on utterances with stutter, mainly due to lack of matched training data. Synthesis of speech with stutter thus presents an opportunity to improve ASR for this type of speech. We describe Stutter-TTS, an end-to-end neural text-to-speech model capable of synthesizing diverse types of stuttering utterances. We develop a simple, yet effective prosody-control strategy whereby additional tokens are introduced into source text during training to represent specific stuttering characteristics. By choosing the position of the stutter tokens, Stutter-TTS allows word-level control of where stuttering occurs in the synthesized utterance. We are able to synthesize stutter events with high accuracy (F1-scores between 0.63 and 0.84, depending on stutter type). By fine-tuning an ASR model on synthetic stuttered speech we are able to reduce word error by 5.7% relative on stuttered utterances, with only minor (<0.2% relative) degradation for fluent utterances.
* 8 pages, 3 figures, 2 tables
ILASR: Privacy-Preserving Incremental Learning for Automatic Speech Recognition at Production Scale
Jul 22, 2022
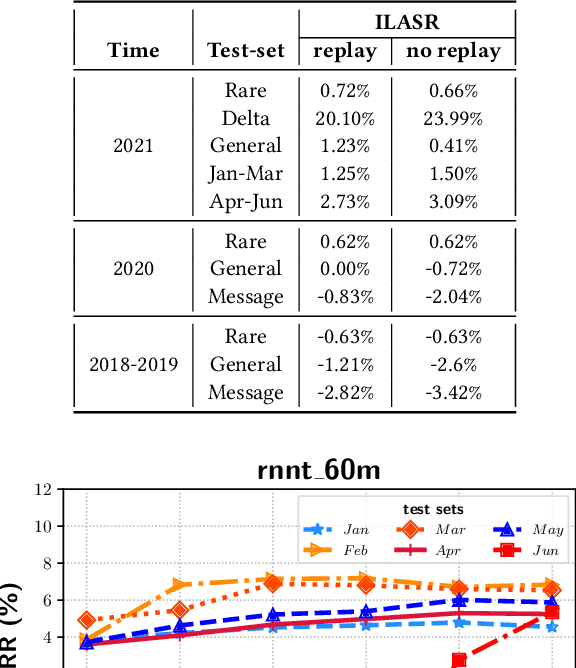
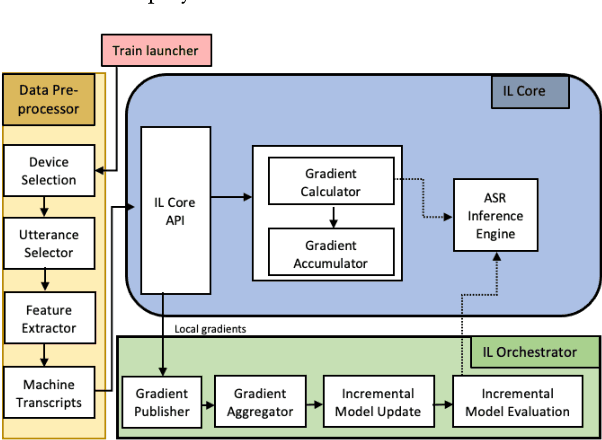
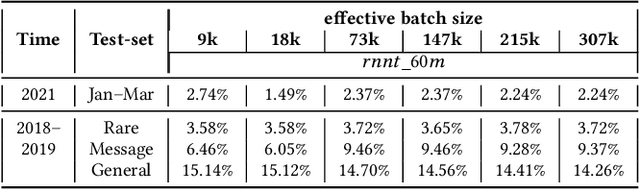
Incremental learning is one paradigm to enable model building and updating at scale with streaming data. For end-to-end automatic speech recognition (ASR) tasks, the absence of human annotated labels along with the need for privacy preserving policies for model building makes it a daunting challenge. Motivated by these challenges, in this paper we use a cloud based framework for production systems to demonstrate insights from privacy preserving incremental learning for automatic speech recognition (ILASR). By privacy preserving, we mean, usage of ephemeral data which are not human annotated. This system is a step forward for production levelASR models for incremental/continual learning that offers near real-time test-bed for experimentation in the cloud for end-to-end ASR, while adhering to privacy-preserving policies. We show that the proposed system can improve the production models significantly(3%) over a new time period of six months even in the absence of human annotated labels with varying levels of weak supervision and large batch sizes in incremental learning. This improvement is 20% over test sets with new words and phrases in the new time period. We demonstrate the effectiveness of model building in a privacy-preserving incremental fashion for ASR while further exploring the utility of having an effective teacher model and use of large batch sizes.
Reducing Geographic Disparities in Automatic Speech Recognition via Elastic Weight Consolidation
Jul 16, 2022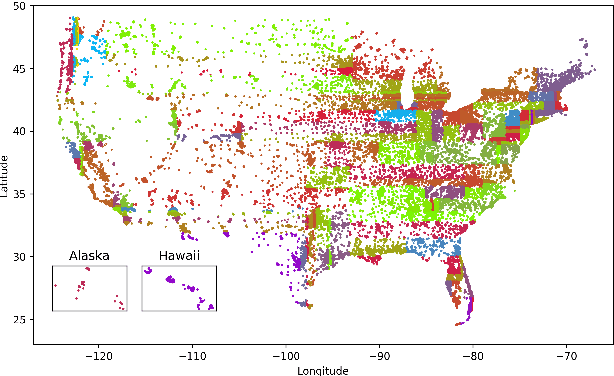

We present an approach to reduce the performance disparity between geographic regions without degrading performance on the overall user population for ASR. A popular approach is to fine-tune the model with data from regions where the ASR model has a higher word error rate (WER). However, when the ASR model is adapted to get better performance on these high-WER regions, its parameters wander from the previous optimal values, which can lead to worse performance in other regions. In our proposed method, we utilize the elastic weight consolidation (EWC) regularization loss to identify directions in parameters space along which the ASR weights can vary to improve for high-error regions, while still maintaining performance on the speaker population overall. Our results demonstrate that EWC can reduce the word error rate (WER) in the region with highest WER by 3.2% relative while reducing the overall WER by 1.3% relative. We also evaluate the role of language and acoustic models in ASR fairness and propose a clustering algorithm to identify WER disparities based on geographic region.
Adversarial Reweighting for Speaker Verification Fairness
Jul 15, 2022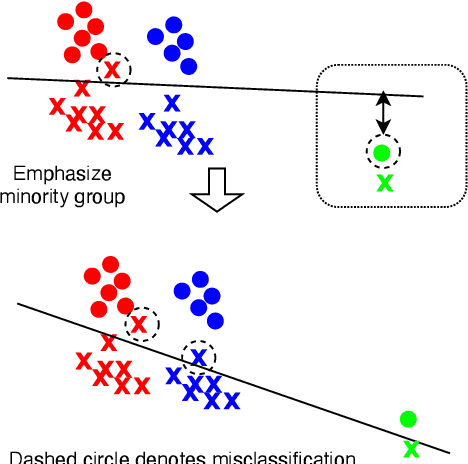
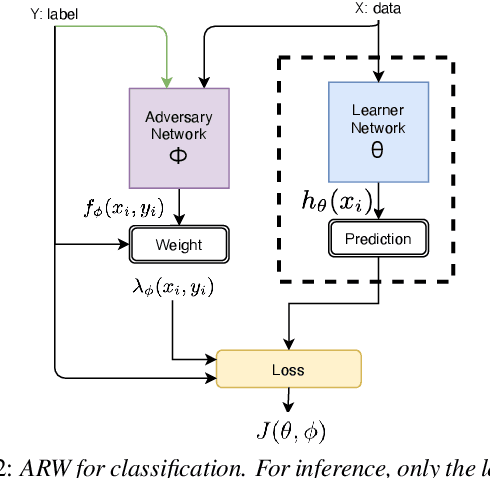
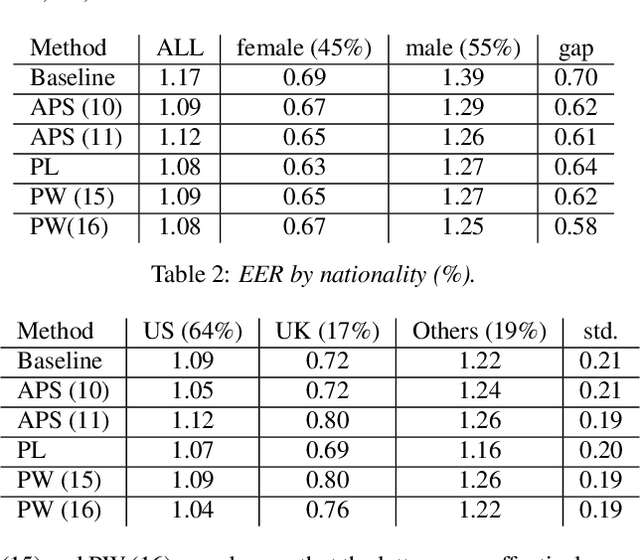
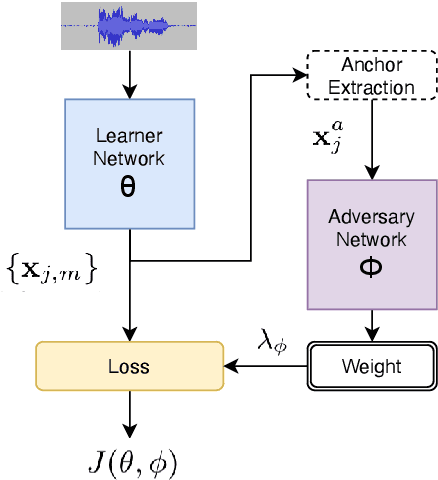
We address performance fairness for speaker verification using the adversarial reweighting (ARW) method. ARW is reformulated for speaker verification with metric learning, and shown to improve results across different subgroups of gender and nationality, without requiring annotation of subgroups in the training data. An adversarial network learns a weight for each training sample in the batch so that the main learner is forced to focus on poorly performing instances. Using a min-max optimization algorithm, this method improves overall speaker verification fairness. We present three different ARWformulations: accumulated pairwise similarity, pseudo-labeling, and pairwise weighting, and measure their performance in terms of equal error rate (EER) on the VoxCeleb corpus. Results show that the pairwise weighting method can achieve 1.08% overall EER, 1.25% for male and 0.67% for female speakers, with relative EER reductions of 7.7%, 10.1% and 3.0%, respectively. For nationality subgroups, the proposed algorithm showed 1.04% EER for US speakers, 0.76% for UK speakers, and 1.22% for all others. The absolute EER gap between gender groups was reduced from 0.70% to 0.58%, while the standard deviation over nationality groups decreased from 0.21 to 0.19.
Improving fairness in speaker verification via Group-adapted Fusion Network
Feb 23, 2022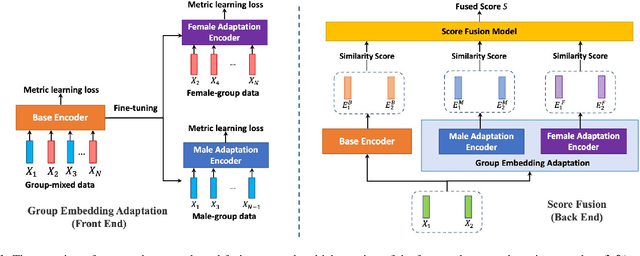
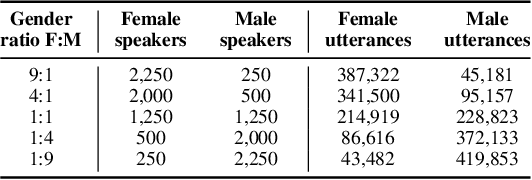

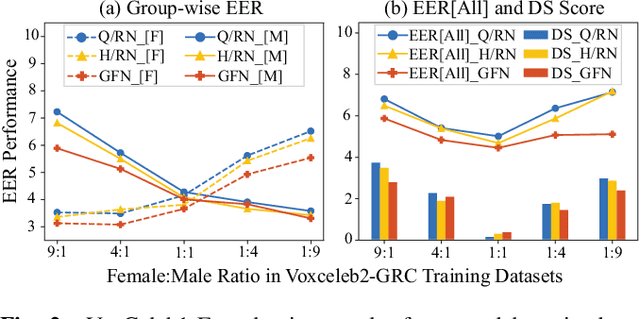
Modern speaker verification models use deep neural networks to encode utterance audio into discriminative embedding vectors. During the training process, these networks are typically optimized to differentiate arbitrary speakers. This learning process biases the learning of fine voice characteristics towards dominant demographic groups, which can lead to an unfair performance disparity across different groups. This is observed especially with underrepresented demographic groups sharing similar voice characteristics. In this work, we investigate the fairness of speaker verification models on controlled datasets with imbalanced gender distributions, providing direct evidence that model performance suffers for underrepresented groups. To mitigate this disparity we propose the group-adapted fusion network (GFN) architecture, a modular architecture based on group embedding adaptation and score fusion. We show that our method alleviates model unfairness by improving speaker verification both overall and for individual groups. Given imbalanced group representation in training, our proposed method achieves overall equal error rate (EER) reduction of 9.6% to 29.0% relative, reduces minority group EER by 13.7% to 18.6%, and results in 20.0% to 25.4% less EER disparity, compared to baselines. The approach is applicable to other types of training data skew in speaker recognition systems.
Investigation of Training Label Error Impact on RNN-T
Dec 01, 2021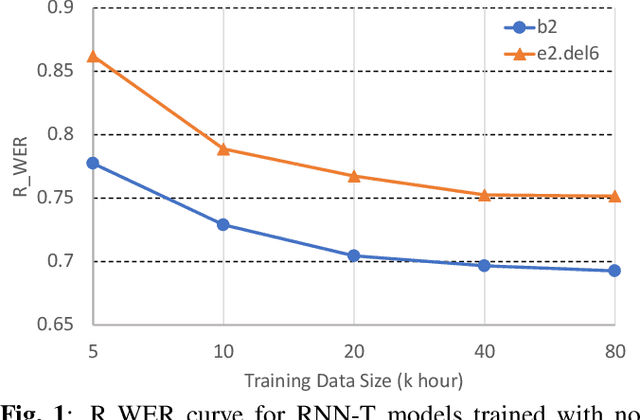
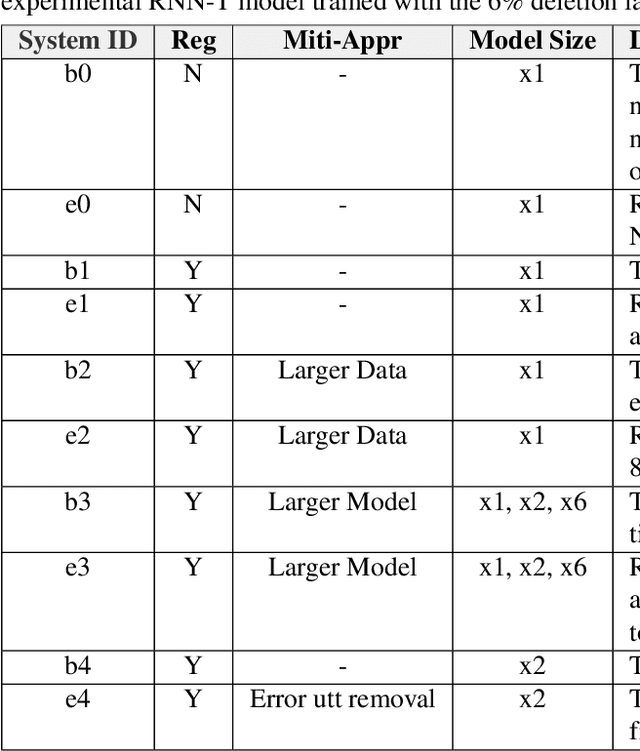
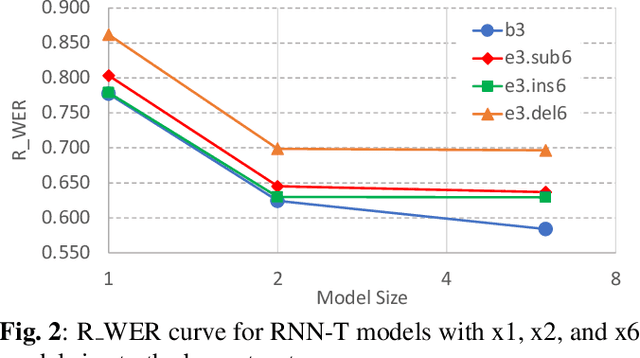
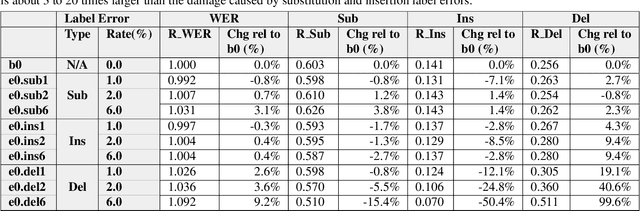
In this paper, we propose an approach to quantitatively analyze impacts of different training label errors to RNN-T based ASR models. The result shows deletion errors are more harmful than substitution and insertion label errors in RNN-T training data. We also examined label error impact mitigation approaches on RNN-T and found that, though all the methods mitigate the label-error-caused degradation to some extent, they could not remove the performance gap between the models trained with and without the presence of label errors. Based on the analysis results, we suggest to design data pipelines for RNN-T with higher priority on reducing deletion label errors. We also find that ensuring high-quality training labels remains important, despite of the existence of the label error mitigation approaches.
Do You Listen with One or Two Microphones? A Unified ASR Model for Single and Multi-Channel Audio
Jun 28, 2021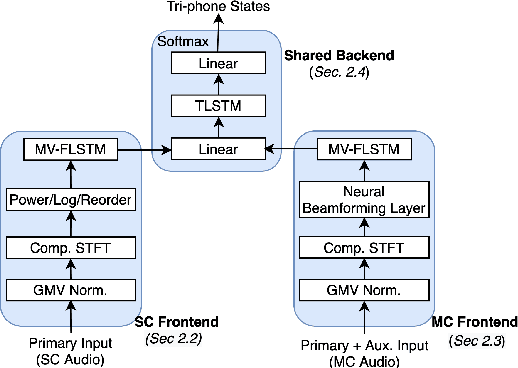
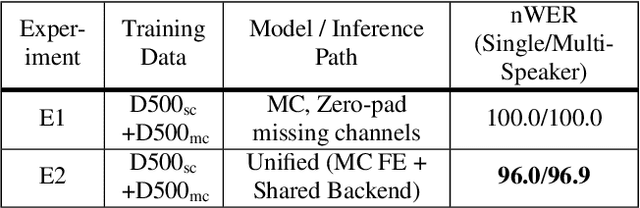
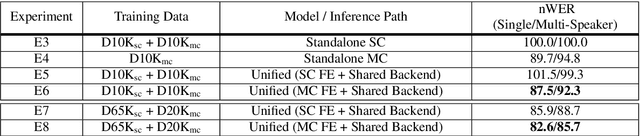
Automatic speech recognition (ASR) models are typically designed to operate on a single input data type, e.g. a single or multi-channel audio streamed from a device. This design decision assumes the primary input data source does not change and if an additional (auxiliary) data source is occasionally available, it cannot be used. An ASR model that operates on both primary and auxiliary data can achieve better accuracy compared to a primary-only solution; and a model that can serve both primary-only (PO) and primary-plus-auxiliary (PPA) modes is highly desirable. In this work, we propose a unified ASR model that can serve both modes. We demonstrate its efficacy in a realistic scenario where a set of devices typically stream a single primary audio channel, and two additional auxiliary channels only when upload bandwidth allows it. The architecture enables a unique methodology that uses both types of input audio during training time. Our proposed approach achieves up to 12.5% relative word-error-rate reduction (WERR) compared to a PO baseline, and up to 16.0% relative WERR in low-SNR conditions. The unique training methodology achieves up to 2.5% relative WERR compared to a PPA baseline.
SynthASR: Unlocking Synthetic Data for Speech Recognition
Jun 14, 2021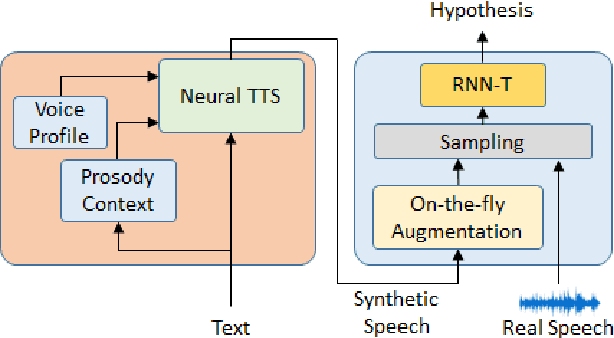
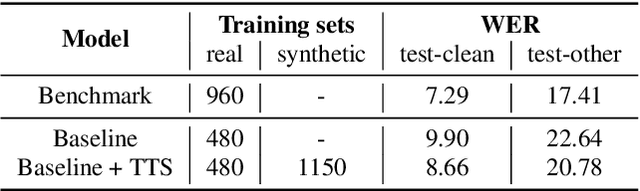
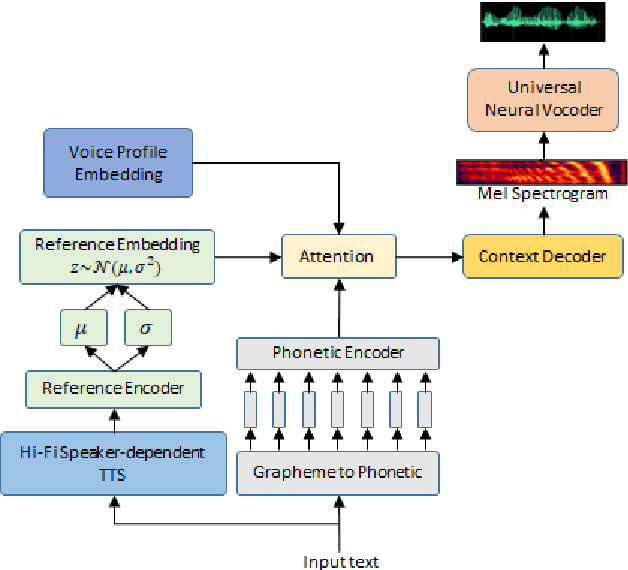
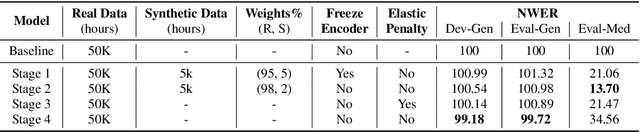
End-to-end (E2E) automatic speech recognition (ASR) models have recently demonstrated superior performance over the traditional hybrid ASR models. Training an E2E ASR model requires a large amount of data which is not only expensive but may also raise dependency on production data. At the same time, synthetic speech generated by the state-of-the-art text-to-speech (TTS) engines has advanced to near-human naturalness. In this work, we propose to utilize synthetic speech for ASR training (SynthASR) in applications where data is sparse or hard to get for ASR model training. In addition, we apply continual learning with a novel multi-stage training strategy to address catastrophic forgetting, achieved by a mix of weighted multi-style training, data augmentation, encoder freezing, and parameter regularization. In our experiments conducted on in-house datasets for a new application of recognizing medication names, training ASR RNN-T models with synthetic audio via the proposed multi-stage training improved the recognition performance on new application by more than 65% relative, without degradation on existing general applications. Our observations show that SynthASR holds great promise in training the state-of-the-art large-scale E2E ASR models for new applications while reducing the costs and dependency on production data.