 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring a Behavioral Model of "Positive Friction" in Human-AI Interaction
Feb 15, 2024


Designing seamless, frictionless user experiences has long been a dominant trend in both applied behavioral science and artificial intelligence (AI), in which the goal of making desirable actions easy and efficient informs efforts to minimize friction in user experiences. However, in some settings, friction can be genuinely beneficial, such as the insertion of deliberate delays to increase reflection, preventing individuals from resorting to automatic or biased behaviors, and enhancing opportunities for unexpected discoveries. More recently, the popularization and availability of AI on a widespread scale has only increased the need to examine how friction can help or hinder users of AI; it also suggests a need to consider how positive friction can benefit AI practitioners, both during development processes (e.g., working with diverse teams) and to inform how AI is designed into offerings. This paper first proposes a "positive friction" model that can help characterize how friction is currently beneficial in user and developer experiences with AI, diagnose the potential need for friction where it may not yet exist in these contexts, and inform how positive friction can be used to generate solutions, especially as advances in AI continue to be progress and new opportunities emerge. It then explores this model in the context of AI users and developers by proposing the value of taking a hybrid "AI+human" lens, and concludes by suggesting questions for further exploration.
* This preprint has not undergone peer review or any post-submission corrections. The Version of Record of this contribution will be published in Springer Nature Computer Science book series in Volume HCI International 2024
Adversarial Reweighting for Speaker Verification Fairness
Jul 15, 2022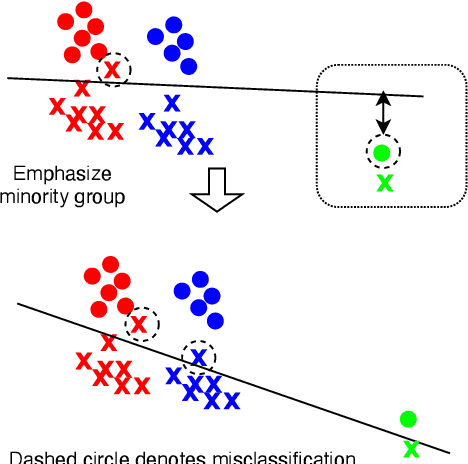
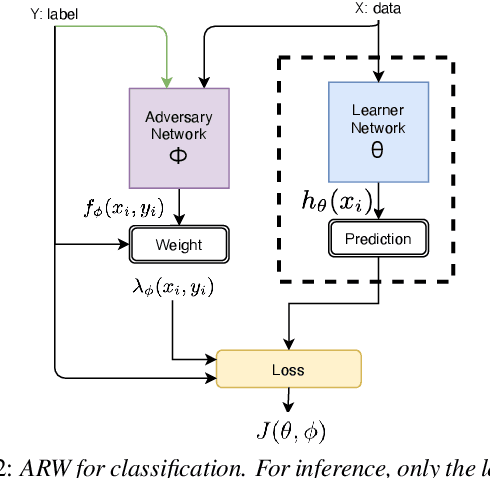
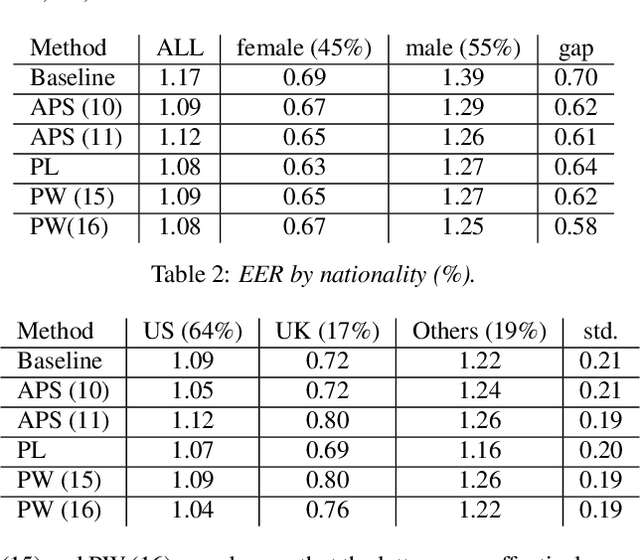
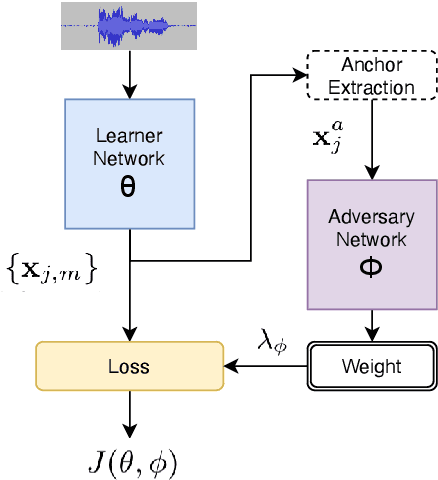
We address performance fairness for speaker verification using the adversarial reweighting (ARW) method. ARW is reformulated for speaker verification with metric learning, and shown to improve results across different subgroups of gender and nationality, without requiring annotation of subgroups in the training data. An adversarial network learns a weight for each training sample in the batch so that the main learner is forced to focus on poorly performing instances. Using a min-max optimization algorithm, this method improves overall speaker verification fairness. We present three different ARWformulations: accumulated pairwise similarity, pseudo-labeling, and pairwise weighting, and measure their performance in terms of equal error rate (EER) on the VoxCeleb corpus. Results show that the pairwise weighting method can achieve 1.08% overall EER, 1.25% for male and 0.67% for female speakers, with relative EER reductions of 7.7%, 10.1% and 3.0%, respectively. For nationality subgroups, the proposed algorithm showed 1.04% EER for US speakers, 0.76% for UK speakers, and 1.22% for all others. The absolute EER gap between gender groups was reduced from 0.70% to 0.58%, while the standard deviation over nationality groups decreased from 0.21 to 0.19.
Self-supervised Speaker Recognition Training Using Human-Machine Dialogues
Feb 07, 2022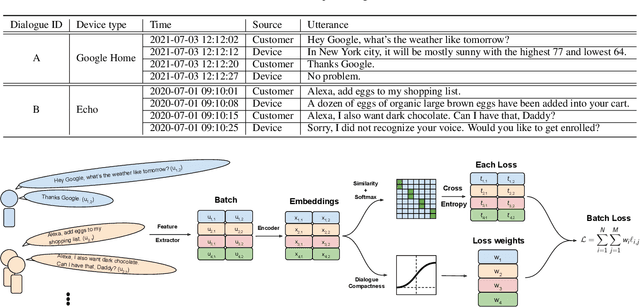

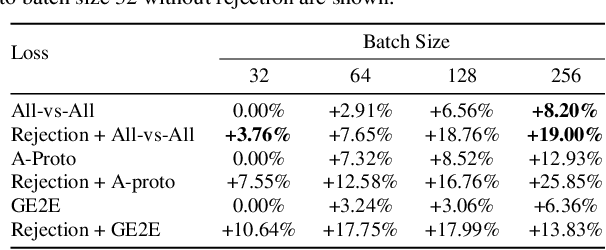

Speaker recognition, recognizing speaker identities based on voice alone, enables important downstream applications, such as personalization and authentication. Learning speaker representations, in the context of supervised learning, heavily depends on both clean and sufficient labeled data, which is always difficult to acquire. Noisy unlabeled data, on the other hand, also provides valuable information that can be exploited using self-supervised training methods. In this work, we investigate how to pretrain speaker recognition models by leveraging dialogues between customers and smart-speaker devices. However, the supervisory information in such dialogues is inherently noisy, as multiple speakers may speak to a device in the course of the same dialogue. To address this issue, we propose an effective rejection mechanism that selectively learns from dialogues based on their acoustic homogeneity. Both reconstruction-based and contrastive-learning-based self-supervised methods are compared. Experiments demonstrate that the proposed method provides significant performance improvements, superior to earlier work. Dialogue pretraining when combined with the rejection mechanism yields 27.10% equal error rate (EER) reduction in speaker recognition, compared to a model without self-supervised pretraining.
Fusion of Embeddings Networks for Robust Combination of Text Dependent and Independent Speaker Recognition
Jun 18, 2021


By implicitly recognizing a user based on his/her speech input, speaker identification enables many downstream applications, such as personalized system behavior and expedited shopping checkouts. Based on whether the speech content is constrained or not, both text-dependent (TD) and text-independent (TI) speaker recognition models may be used. We wish to combine the advantages of both types of models through an ensemble system to make more reliable predictions. However, any such combined approach has to be robust to incomplete inputs, i.e., when either TD or TI input is missing. As a solution we propose a fusion of embeddings network foenet architecture, combining joint learning with neural attention. We compare foenet with four competitive baseline methods on a dataset of voice assistant inputs, and show that it achieves higher accuracy than the baseline and score fusion methods, especially in the presence of incomplete inputs.