 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Synthetic Speaker Profiles in Text-to-Speech Systems
Feb 07, 2022The diversity of speaker profiles in multi-speaker TTS systems is a crucial aspect of its performance, as it measures how many different speaker profiles TTS systems could possibly synthesize. However, this important aspect is often overlooked when building multi-speaker TTS systems and there is no established framework to evaluate this diversity. The reason behind is that most multi-speaker TTS systems are limited to generate speech signals with the same speaker profiles as its training data. They often use discrete speaker embedding vectors which have a one-to-one correspondence with individual speakers. This correspondence limits TTS systems and hinders their capability of generating unseen speaker profiles that did not appear during training. In this paper, we aim to build multi-speaker TTS systems that have a greater variety of speaker profiles and can generate new synthetic speaker profiles that are different from training data. To this end, we propose to use generative models with a triplet loss and a specific shuffle mechanism. In our experiments, the effectiveness and advantages of the proposed method have been demonstrated in terms of both the distinctiveness and intelligibility of synthesized speech signals.
Fusion of Embeddings Networks for Robust Combination of Text Dependent and Independent Speaker Recognition
Jun 18, 2021


By implicitly recognizing a user based on his/her speech input, speaker identification enables many downstream applications, such as personalized system behavior and expedited shopping checkouts. Based on whether the speech content is constrained or not, both text-dependent (TD) and text-independent (TI) speaker recognition models may be used. We wish to combine the advantages of both types of models through an ensemble system to make more reliable predictions. However, any such combined approach has to be robust to incomplete inputs, i.e., when either TD or TI input is missing. As a solution we propose a fusion of embeddings network foenet architecture, combining joint learning with neural attention. We compare foenet with four competitive baseline methods on a dataset of voice assistant inputs, and show that it achieves higher accuracy than the baseline and score fusion methods, especially in the presence of incomplete inputs.
Scaling Laws for Acoustic Models
Jun 11, 2021

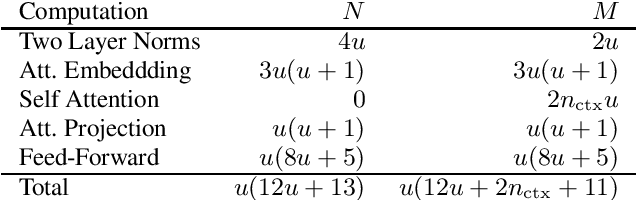

There is a recent trend in machine learning to increase model quality by growing models to sizes previously thought to be unreasonable. Recent work has shown that autoregressive generative models with cross-entropy objective functions exhibit smooth power-law relationships, or scaling laws, that predict model quality from model size, training set size, and the available compute budget. These scaling laws allow one to choose nearly optimal hyper-parameters given constraints on available training data, model parameter count, or training computation budget. In this paper, we demonstrate that acoustic models trained with an auto-predictive coding loss behave as if they are subject to similar scaling laws. We extend previous work to jointly predict loss due to model size, to training set size, and to the inherent "irreducible loss" of the task. We find that the scaling laws accurately match model performance over two orders of magnitude in both model size and training set size, and make predictions about the limits of model performance.
Untangling in Invariant Speech Recognition
Mar 03, 2020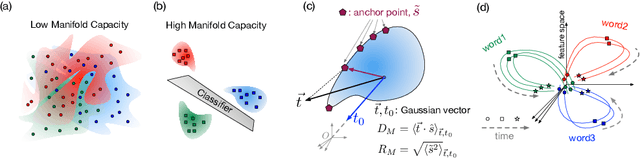
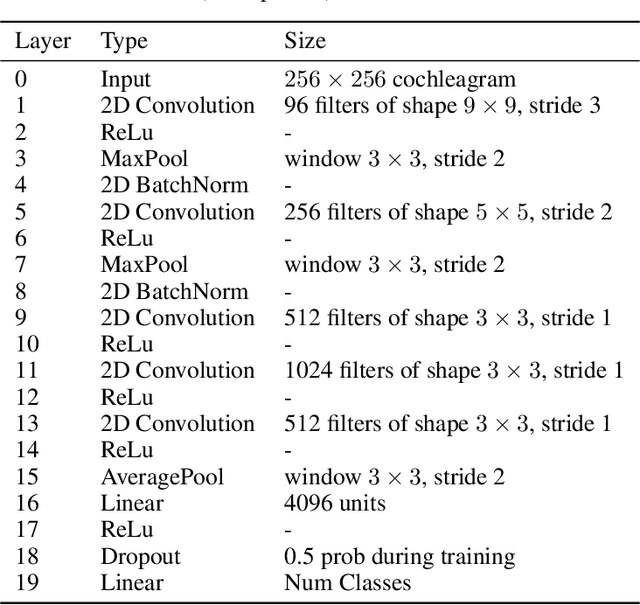
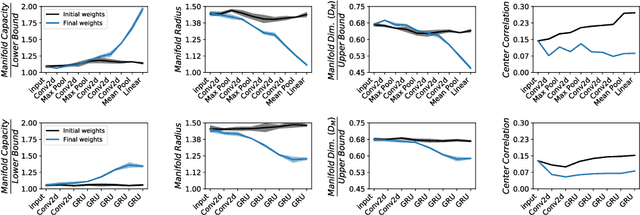
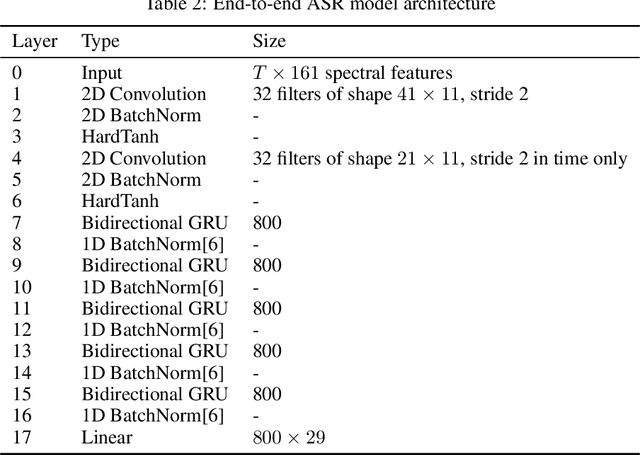
Encouraged by the success of deep neural networks on a variety of visual tasks, much theoretical and experimental work has been aimed at understanding and interpreting how vision networks operate. Meanwhile, deep neural networks have also achieved impressive performance in audio processing applications, both as sub-components of larger systems and as complete end-to-end systems by themselves. Despite their empirical successes, comparatively little is understood about how these audio models accomplish these tasks. In this work, we employ a recently developed statistical mechanical theory that connects geometric properties of network representations and the separability of classes to probe how information is untangled within neural networks trained to recognize speech. We observe that speaker-specific nuisance variations are discarded by the network's hierarchy, whereas task-relevant properties such as words and phonemes are untangled in later layers. Higher level concepts such as parts-of-speech and context dependence also emerge in the later layers of the network. Finally, we find that the deep representations carry out significant temporal untangling by efficiently extracting task-relevant features at each time step of the computation. Taken together, these findings shed light on how deep auditory models process time dependent input signals to achieve invariant speech recognition, and show how different concepts emerge through the layers of the network.