 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Fallen Objects Via Asynchronous Audio-Visual Integration
Jul 07, 2022
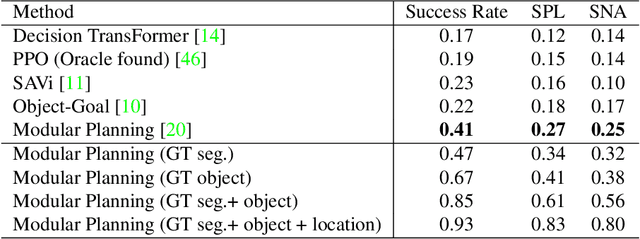

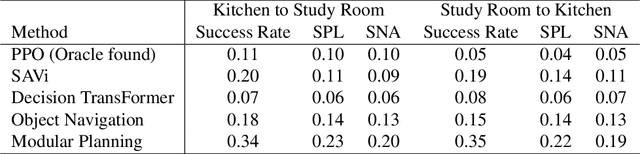
The way an object looks and sounds provide complementary reflections of its physical properties. In many settings cues from vision and audition arrive asynchronously but must be integrated, as when we hear an object dropped on the floor and then must find it. In this paper, we introduce a setting in which to study multi-modal object localization in 3D virtual environments. An object is dropped somewhere in a room. An embodied robot agent, equipped with a camera and microphone, must determine what object has been dropped -- and where -- by combining audio and visual signals with knowledge of the underlying physics. To study this problem, we have generated a large-scale dataset -- the Fallen Objects dataset -- that includes 8000 instances of 30 physical object categories in 64 rooms. The dataset uses the ThreeDWorld platform which can simulate physics-based impact sounds and complex physical interactions between objects in a photorealistic setting. As a first step toward addressing this challenge, we develop a set of embodied agent baselines, based on imitation learning, reinforcement learning, and modular planning, and perform an in-depth analysis of the challenge of this new task.
Object-based synthesis of scraping and rolling sounds based on non-linear physical constraints
Dec 16, 2021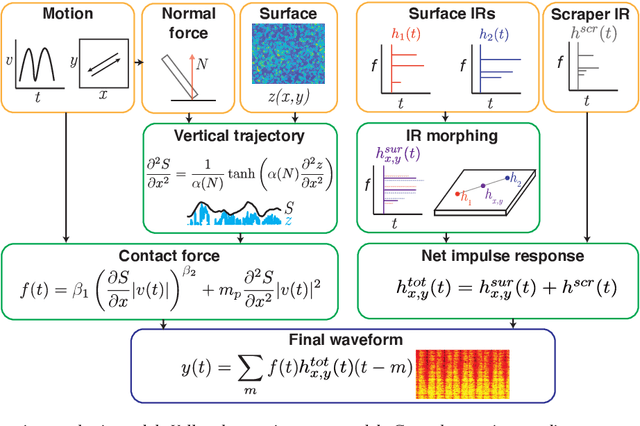
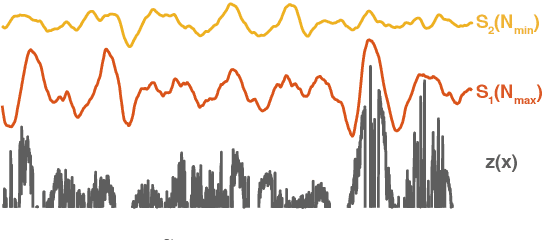
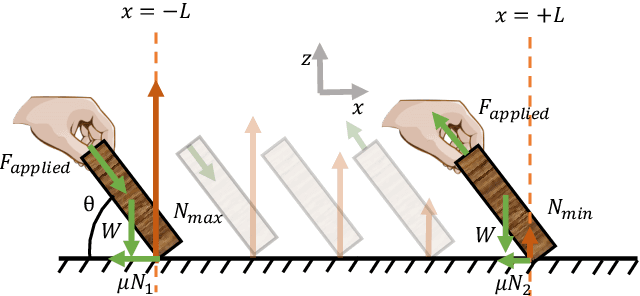
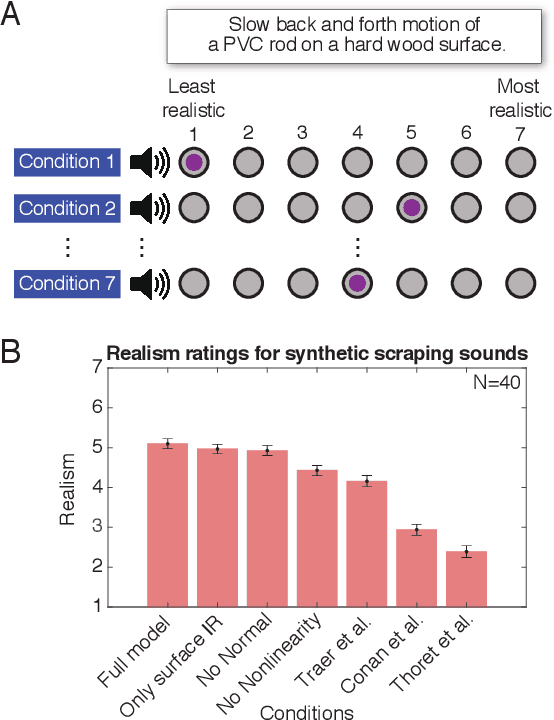
Sustained contact interactions like scraping and rolling produce a wide variety of sounds. Previous studies have explored ways to synthesize these sounds efficiently and intuitively but could not fully mimic the rich structure of real instances of these sounds. We present a novel source-filter model for realistic synthesis of scraping and rolling sounds with physically and perceptually relevant controllable parameters constrained by principles of mechanics. Key features of our model include non-linearities to constrain the contact force, naturalistic normal force variation for different motions, and a method for morphing impulse responses within a material to achieve location-dependence. Perceptual experiments show that the presented model is able to synthesize realistic scraping and rolling sounds while conveying physical information similar to that in recorded sounds.
The ThreeDWorld Transport Challenge: A Visually Guided Task-and-Motion Planning Benchmark for Physically Realistic Embodied AI
Mar 25, 2021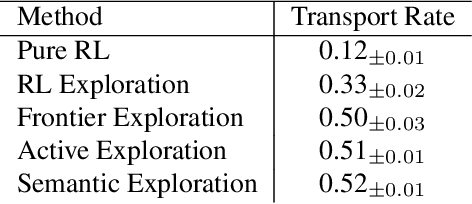

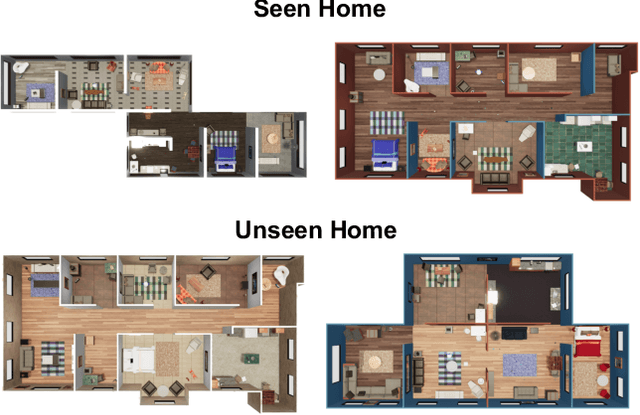
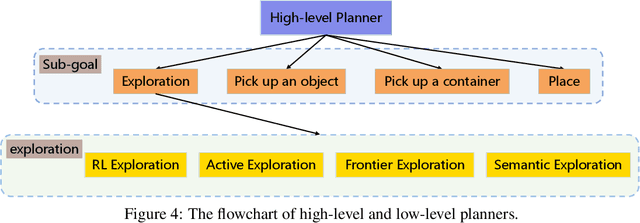
We introduce a visually-guided and physics-driven task-and-motion planning benchmark, which we call the ThreeDWorld Transport Challenge. In this challenge, an embodied agent equipped with two 9-DOF articulated arms is spawned randomly in a simulated physical home environment. The agent is required to find a small set of objects scattered around the house, pick them up, and transport them to a desired final location. We also position containers around the house that can be used as tools to assist with transporting objects efficiently. To complete the task, an embodied agent must plan a sequence of actions to change the state of a large number of objects in the face of realistic physical constraints. We build this benchmark challenge using the ThreeDWorld simulation: a virtual 3D environment where all objects respond to physics, and where can be controlled using fully physics-driven navigation and interaction API. We evaluate several existing agents on this benchmark. Experimental results suggest that: 1) a pure RL model struggles on this challenge; 2) hierarchical planning-based agents can transport some objects but still far from solving this task. We anticipate that this benchmark will empower researchers to develop more intelligent physics-driven robots for the physical world.
ThreeDWorld: A Platform for Interactive Multi-Modal Physical Simulation
Jul 09, 2020
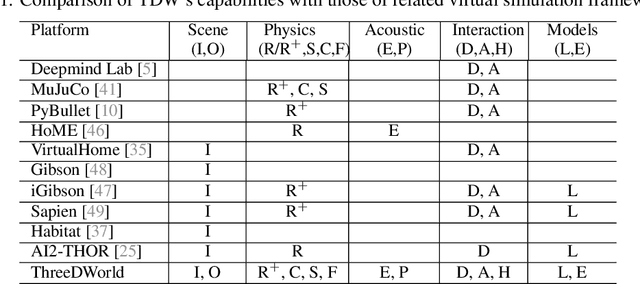

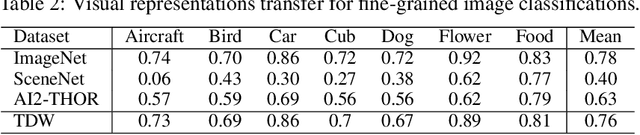
We introduce ThreeDWorld (TDW), a platform for interactive multi-modal physical simulation. With TDW, users can simulate high-fidelity sensory data and physical interactions between mobile agents and objects in a wide variety of rich 3D environments. TDW has several unique properties: 1) realtime near photo-realistic image rendering quality; 2) a library of objects and environments with materials for high-quality rendering, and routines enabling user customization of the asset library; 3) generative procedures for efficiently building classes of new environments 4) high-fidelity audio rendering; 5) believable and realistic physical interactions for a wide variety of material types, including cloths, liquid, and deformable objects; 6) a range of "avatar" types that serve as embodiments of AI agents, with the option for user avatar customization; and 7) support for human interactions with VR devices. TDW also provides a rich API enabling multiple agents to interact within a simulation and return a range of sensor and physics data representing the state of the world. We present initial experiments enabled by the platform around emerging research directions in computer vision, machine learning, and cognitive science, including multi-modal physical scene understanding, multi-agent interactions, models that "learn like a child", and attention studies in humans and neural networks. The simulation platform will be made publicly available.
Untangling in Invariant Speech Recognition
Mar 03, 2020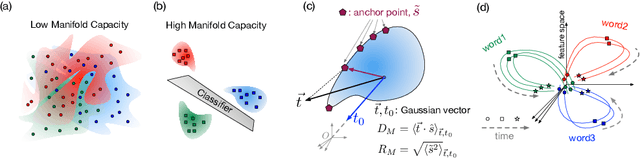
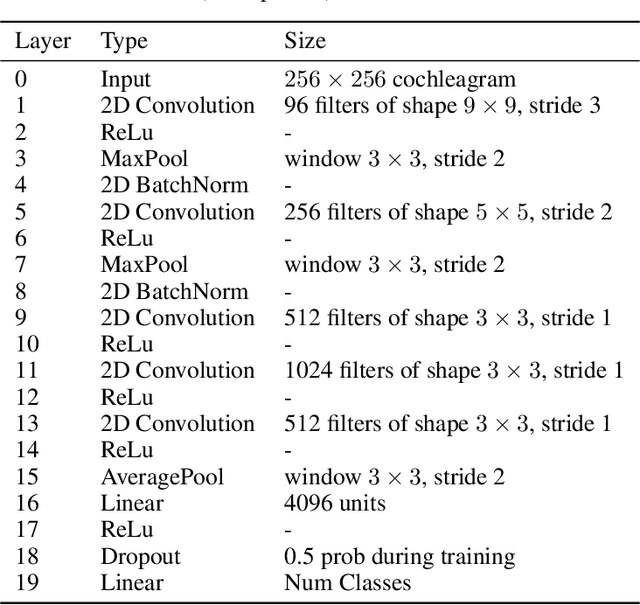
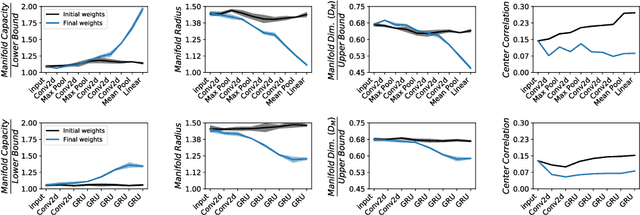
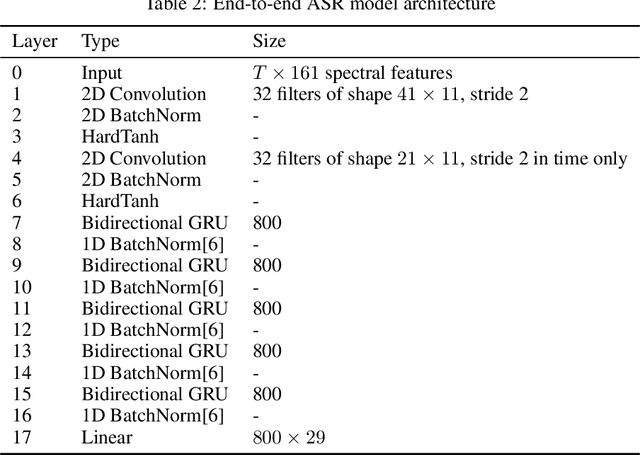
Encouraged by the success of deep neural networks on a variety of visual tasks, much theoretical and experimental work has been aimed at understanding and interpreting how vision networks operate. Meanwhile, deep neural networks have also achieved impressive performance in audio processing applications, both as sub-components of larger systems and as complete end-to-end systems by themselves. Despite their empirical successes, comparatively little is understood about how these audio models accomplish these tasks. In this work, we employ a recently developed statistical mechanical theory that connects geometric properties of network representations and the separability of classes to probe how information is untangled within neural networks trained to recognize speech. We observe that speaker-specific nuisance variations are discarded by the network's hierarchy, whereas task-relevant properties such as words and phonemes are untangled in later layers. Higher level concepts such as parts-of-speech and context dependence also emerge in the later layers of the network. Finally, we find that the deep representations carry out significant temporal untangling by efficiently extracting task-relevant features at each time step of the computation. Taken together, these findings shed light on how deep auditory models process time dependent input signals to achieve invariant speech recognition, and show how different concepts emerge through the layers of the network.
Self-Supervised Audio-Visual Co-Segmentation
Apr 18, 2019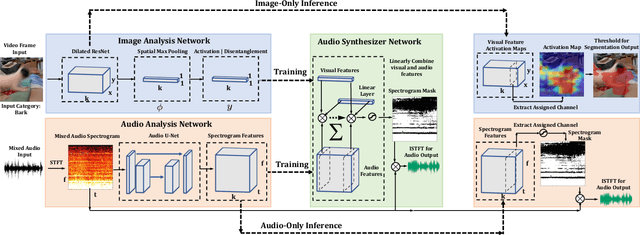
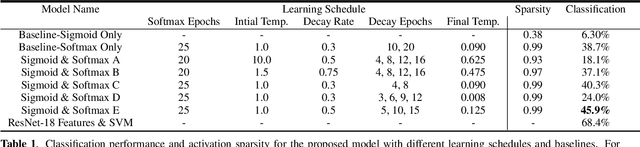
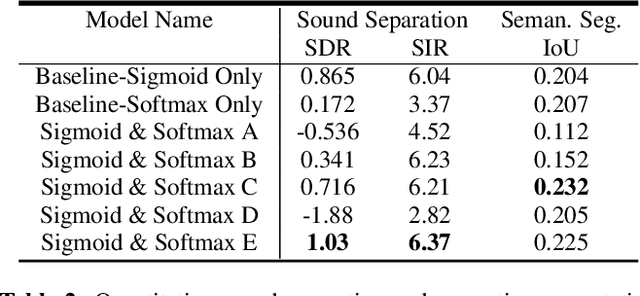
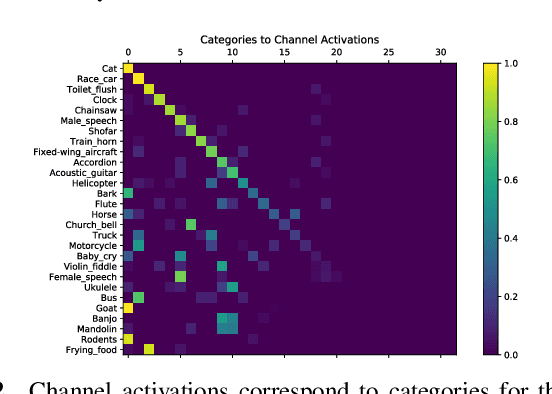
Segmenting objects in images and separating sound sources in audio are challenging tasks, in part because traditional approaches require large amounts of labeled data. In this paper we develop a neural network model for visual object segmentation and sound source separation that learns from natural videos through self-supervision. The model is an extension of recently proposed work that maps image pixels to sounds. Here, we introduce a learning approach to disentangle concepts in the neural networks, and assign semantic categories to network feature channels to enable independent image segmentation and sound source separation after audio-visual training on videos. Our evaluations show that the disentangled model outperforms several baselines in semantic segmentation and sound source separation.
The Sound of Pixels
Oct 14, 2018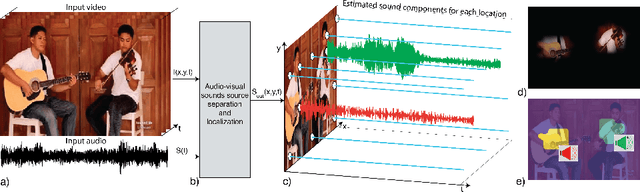

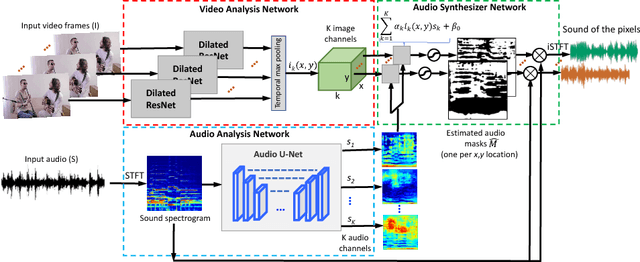
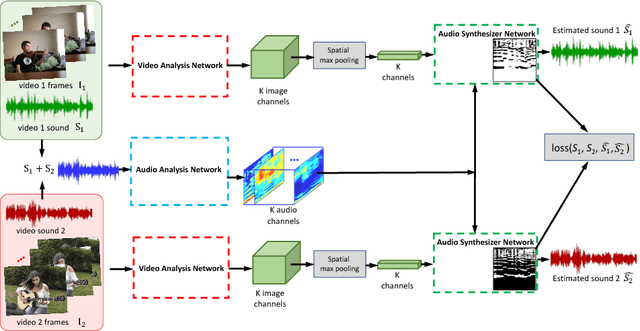
We introduce PixelPlayer, a system that, by leveraging large amounts of unlabeled videos, learns to locate image regions which produce sounds and separate the input sounds into a set of components that represents the sound from each pixel. Our approach capitalizes on the natural synchronization of the visual and audio modalities to learn models that jointly parse sounds and images, without requiring additional manual supervision. Experimental results on a newly collected MUSIC dataset show that our proposed Mix-and-Separate framework outperforms several baselines on source separation. Qualitative results suggest our model learns to ground sounds in vision, enabling applications such as independently adjusting the volume of sound sources.
Visually Indicated Sounds
Apr 30, 2016
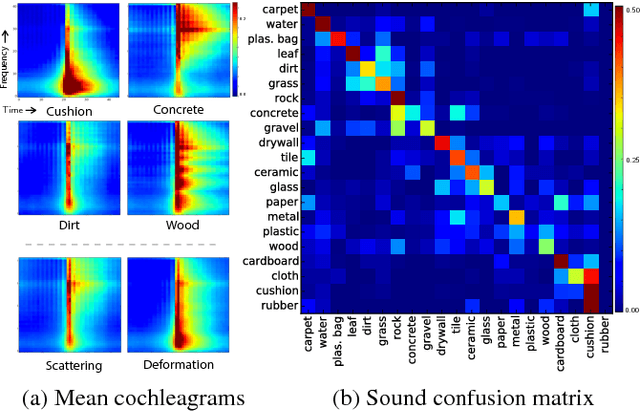
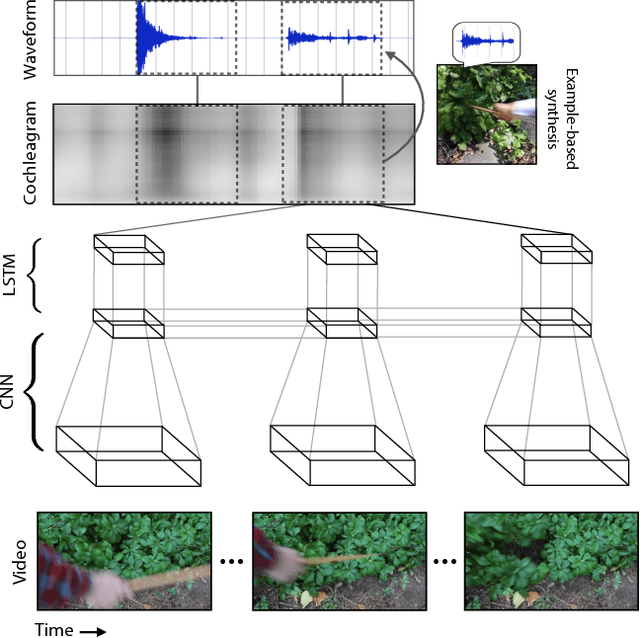
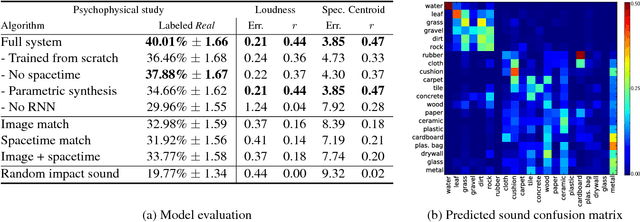
Objects make distinctive sounds when they are hit or scratched. These sounds reveal aspects of an object's material properties, as well as the actions that produced them. In this paper, we propose the task of predicting what sound an object makes when struck as a way of studying physical interactions within a visual scene. We present an algorithm that synthesizes sound from silent videos of people hitting and scratching objects with a drumstick. This algorithm uses a recurrent neural network to predict sound features from videos and then produces a waveform from these features with an example-based synthesis procedure. We show that the sounds predicted by our model are realistic enough to fool participants in a "real or fake" psychophysical experiment, and that they convey significant information about material properties and physical interactions.