 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-layer attentive probing improves transfer of audio representations for bioacoustics
May 11, 2026Probing heads map the representations learned from audio by a machine learning model to downstream task labels and are a key component in evaluating representation learning. Most bioacoustic benchmarks use a fixed, low-capacity probe, such as a linear layer on the final encoder layer. While this standardization enables model comparisons, it may bias results by overlooking the interaction between encoder features and probe design. In this work, we systematically study different probing strategies across two bioacoustic benchmarks, BEANs and BirdSet. We evaluate last- and multi-layer probing, across linear and attention probes. We show that larger probe heads that leverage time information have superior performance. Our results suggest that current benchmarks may misrepresent encoder quality when relying on a last-layer probing setup. Multi-layer probing improves downstream task performance across all tested models, while attention probing has superior performance to linear probing for transformer models.
Robust detection of overlapping bioacoustic sound events
Mar 04, 2025We propose a method for accurately detecting bioacoustic sound events that is robust to overlapping events, a common issue in domains such as ethology, ecology and conservation. While standard methods employ a frame-based, multi-label approach, we introduce an onset-based detection method which we name Voxaboxen. It takes inspiration from object detection methods in computer vision, but simultaneously takes advantage of recent advances in self-supervised audio encoders. For each time window, Voxaboxen predicts whether it contains the start of a vocalization and how long the vocalization is. It also does the same in reverse, predicting whether each window contains the end of a vocalization, and how long ago it started. The two resulting sets of bounding boxes are then fused using a graph-matching algorithm. We also release a new dataset designed to measure performance on detecting overlapping vocalizations. This consists of recordings of zebra finches annotated with temporally-strong labels and showing frequent overlaps. We test Voxaboxen on seven existing data sets and on our new data set. We compare Voxaboxen to natural baselines and existing sound event detection methods and demonstrate SotA results. Further experiments show that improvements are robust to frequent vocalization overlap.
Biodenoising: animal vocalization denoising without access to clean data
Oct 04, 2024Animal vocalization denoising is a task similar to human speech enhancement, a well-studied field of research. In contrast to the latter, it is applied to a higher diversity of sound production mechanisms and recording environments, and this higher diversity is a challenge for existing models. Adding to the challenge and in contrast to speech, we lack large and diverse datasets comprising clean vocalizations. As a solution we use as training data pseudo-clean targets, i.e. pre-denoised vocalizations, and segments of background noise without a vocalization. We propose a train set derived from bioacoustics datasets and repositories representing diverse species, acoustic environments, geographic regions. Additionally, we introduce a non-overlapping benchmark set comprising clean vocalizations from different taxa and noise samples. We show that that denoising models (demucs, CleanUNet) trained on pseudo-clean targets obtained with speech enhancement models achieve competitive results on the benchmarking set. We publish data, code, libraries, and demos https://mariusmiron.com/research/biodenoising.
A benchmark for computational analysis of animal behavior, using animal-borne tags
May 18, 2023Animal-borne sensors ('bio-loggers') can record a suite of kinematic and environmental data, which can elucidate animal ecophysiology and improve conservation efforts. Machine learning techniques are useful for interpreting the large amounts of data recorded by bio-loggers, but there exists no standard for comparing the different machine learning techniques in this domain. To address this, we present the Bio-logger Ethogram Benchmark (BEBE), a collection of datasets with behavioral annotations, standardized modeling tasks, and evaluation metrics. BEBE is to date the largest, most taxonomically diverse, publicly available benchmark of this type, and includes 1654 hours of data collected from 149 individuals across nine taxa. We evaluate the performance of ten different machine learning methods on BEBE, and identify key challenges to be addressed in future work. Datasets, models, and evaluation code are made publicly available at https://github.com/earthspecies/BEBE, to enable community use of BEBE as a point of comparison in methods development.
Modeling Animal Vocalizations through Synthesizers
Oct 19, 2022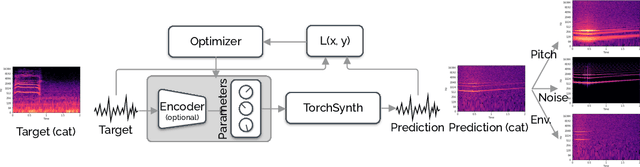
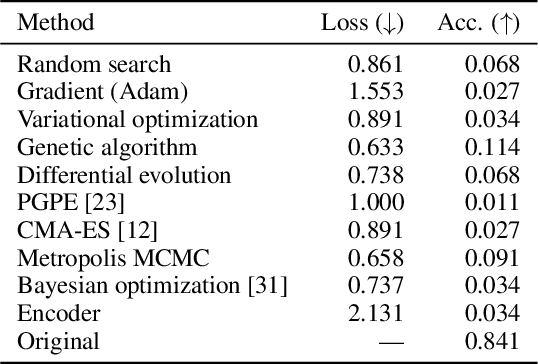
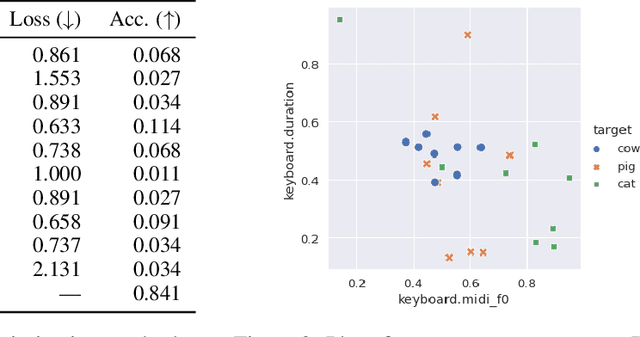
Modeling real-world sound is a fundamental problem in the creative use of machine learning and many other fields, including human speech processing and bioacoustics. Transformer-based generative models and some prior work (e.g., DDSP) are known to produce realistic sound, although they have limited control and are hard to interpret. As an alternative, we aim to use modular synthesizers, i.e., compositional, parametric electronic musical instruments, for modeling non-music sounds. However, inferring synthesizer parameters given a target sound, i.e., the parameter inference task, is not trivial for general sounds, and past research has typically focused on musical sound. In this work, we optimize a differentiable synthesizer from TorchSynth in order to model, emulate, and creatively generate animal vocalizations. We compare an array of optimization methods, from gradient-based search to genetic algorithms, for inferring its parameters, and then demonstrate how one can control and interpret the parameters for modeling non-music sounds.
Object-based synthesis of scraping and rolling sounds based on non-linear physical constraints
Dec 16, 2021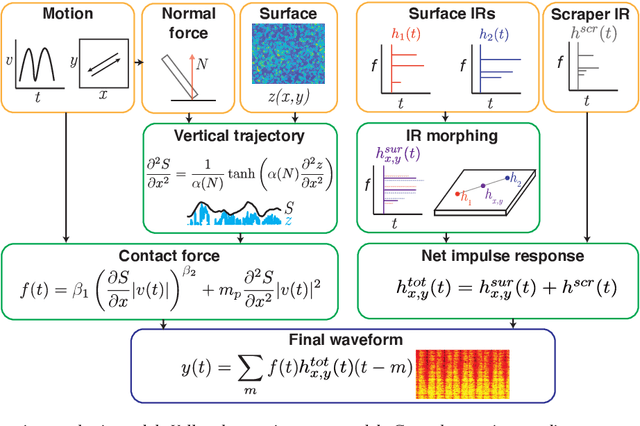
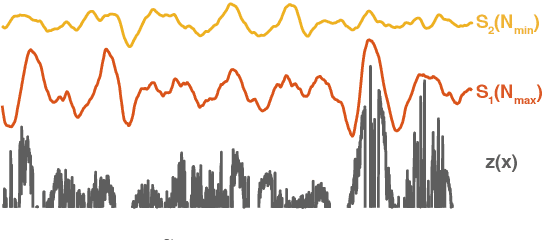
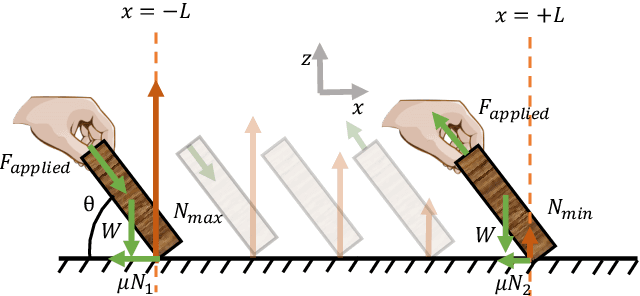
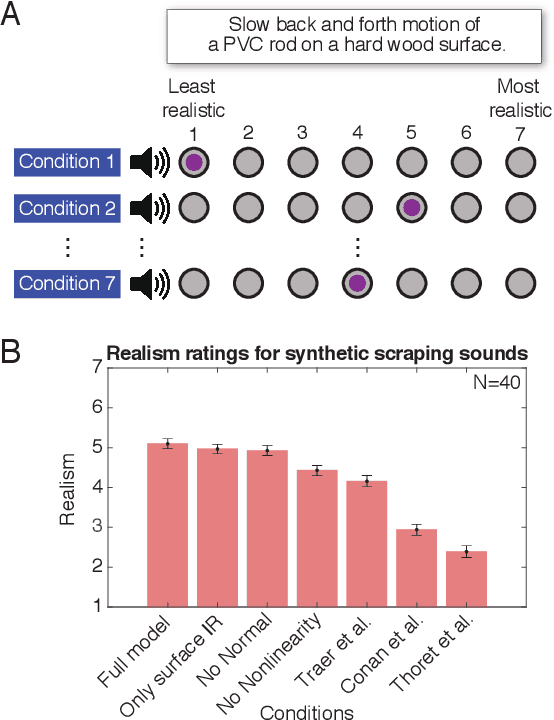
Sustained contact interactions like scraping and rolling produce a wide variety of sounds. Previous studies have explored ways to synthesize these sounds efficiently and intuitively but could not fully mimic the rich structure of real instances of these sounds. We present a novel source-filter model for realistic synthesis of scraping and rolling sounds with physically and perceptually relevant controllable parameters constrained by principles of mechanics. Key features of our model include non-linearities to constrain the contact force, naturalistic normal force variation for different motions, and a method for morphing impulse responses within a material to achieve location-dependence. Perceptual experiments show that the presented model is able to synthesize realistic scraping and rolling sounds while conveying physical information similar to that in recorded sounds.