 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Depth Images of Moving Objects from Wi-Fi CSI Data
Mar 09, 2025This study proposes a new deep learning method for reconstructing depth images of moving objects within a specific area using Wi-Fi channel state information (CSI). The Wi-Fi-based depth imaging technique has novel applications in domains such as security and elder care. However, reconstructing depth images from CSI is challenging because learning the mapping function between CSI and depth images, both of which are high-dimensional data, is particularly difficult. To address the challenge, we propose a new approach called Wi-Depth. The main idea behind the design of Wi-Depth is that a depth image of a moving object can be decomposed into three core components: the shape, depth, and position of the target. Therefore, in the depth-image reconstruction task, Wi-Depth simultaneously estimates the three core pieces of information as auxiliary tasks in our proposed VAE-based teacher-student architecture, enabling it to output images with the consistency of a correct shape, depth, and position. In addition, the design of Wi-Depth is based on our idea that this decomposition efficiently takes advantage of the fact that shape, depth, and position relate to primitive information inferred from CSI such as angle-of-arrival, time-of-flight, and Doppler frequency shift.
Unsupervised Human Activity Recognition through Two-stage Prompting with ChatGPT
Jun 03, 2023Wearable sensor devices, which offer the advantage of recording daily objects used by a person while performing an activity, enable the feasibility of unsupervised Human Activity Recognition (HAR). Unfortunately, previous unsupervised approaches using the usage sequence of objects usually require a proper description of activities manually prepared by humans. Instead, we leverage the knowledge embedded in a Large Language Model (LLM) of ChatGPT. Because the sequence of objects robustly characterizes the activity identity, it is possible that ChatGPT already learned the association between activities and objects from existing contexts. However, previous prompt engineering for ChatGPT exhibits limited generalization ability when dealing with a list of words (i.e., sequence of objects) due to the similar weighting assigned to each word in the list. In this study, we propose a two-stage prompt engineering, which first guides ChatGPT to generate activity descriptions associated with objects while emphasizing important objects for distinguishing similar activities; then outputs activity classes and explanations for enhancing the contexts that are helpful for HAR. To the best of our knowledge, this is the first study that utilizes ChatGPT to recognize activities using objects in an unsupervised manner. We conducted our approach on three datasets and demonstrated the state-of-the-art performance.
A benchmark for computational analysis of animal behavior, using animal-borne tags
May 18, 2023Animal-borne sensors ('bio-loggers') can record a suite of kinematic and environmental data, which can elucidate animal ecophysiology and improve conservation efforts. Machine learning techniques are useful for interpreting the large amounts of data recorded by bio-loggers, but there exists no standard for comparing the different machine learning techniques in this domain. To address this, we present the Bio-logger Ethogram Benchmark (BEBE), a collection of datasets with behavioral annotations, standardized modeling tasks, and evaluation metrics. BEBE is to date the largest, most taxonomically diverse, publicly available benchmark of this type, and includes 1654 hours of data collected from 149 individuals across nine taxa. We evaluate the performance of ten different machine learning methods on BEBE, and identify key challenges to be addressed in future work. Datasets, models, and evaluation code are made publicly available at https://github.com/earthspecies/BEBE, to enable community use of BEBE as a point of comparison in methods development.
OpenPack: A Large-scale Dataset for Recognizing Packaging Works in IoT-enabled Logistic Environments
Dec 10, 2022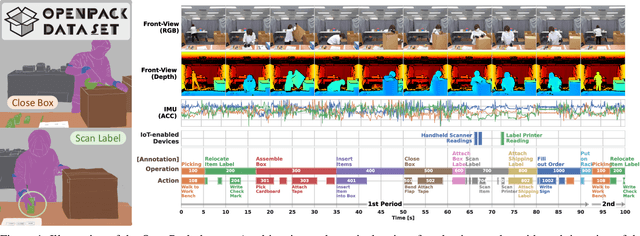
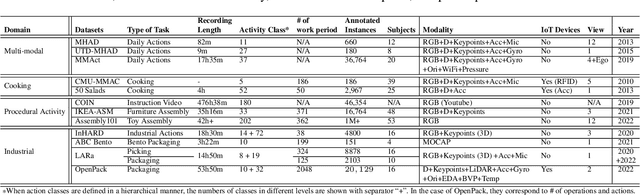
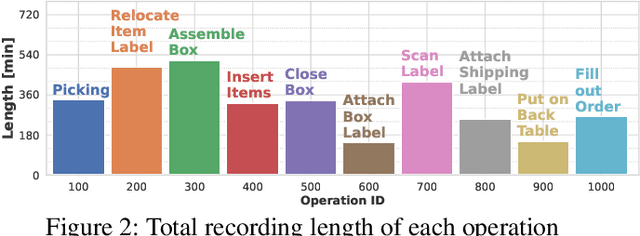
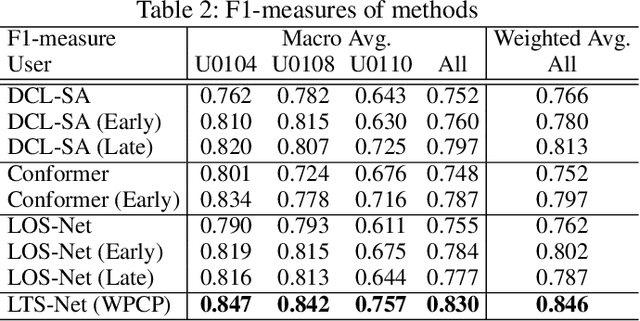
Unlike human daily activities, existing publicly available sensor datasets for work activity recognition in industrial domains are limited by difficulties in collecting realistic data as close collaboration with industrial sites is required. This also limits research on and development of AI methods for industrial applications. To address these challenges and contribute to research on machine recognition of work activities in industrial domains, in this study, we introduce a new large-scale dataset for packaging work recognition called OpenPack. OpenPack contains 53.8 hours of multimodal sensor data, including keypoints, depth images, acceleration data, and readings from IoT-enabled devices (e.g., handheld barcode scanners used in work procedures), collected from 16 distinct subjects with different levels of packaging work experience. On the basis of this dataset, we propose a neural network model designed to recognize work activities, which efficiently fuses sensor data and readings from IoT-enabled devices by processing them within different streams in a ladder-shaped architecture, and the experiment showed the effectiveness of the architecture. We believe that OpenPack will contribute to the community of action/activity recognition with sensors. OpenPack dataset is available at https://open-pack.github.io/.
Using Social Media Background to Improve Cold-start Recommendation Deep Models
Jun 04, 2021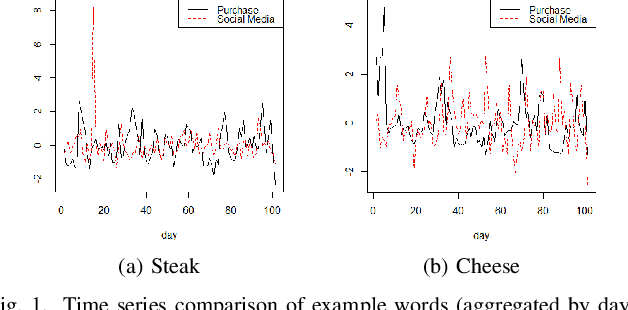
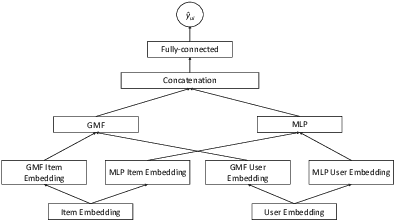
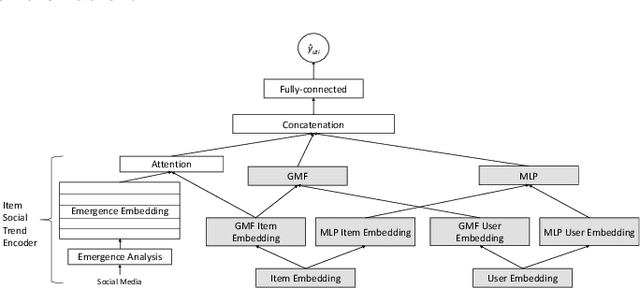
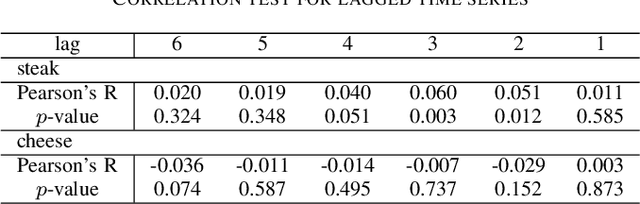
In recommender systems, a cold-start problem occurs when there is no past interaction record associated with the user or item. Typical solutions to the cold-start problem make use of contextual information, such as user demographic attributes or product descriptions. A group of works have shown that social media background can help predicting temporal phenomenons such as product sales and stock price movements. In this work, our goal is to investigate whether social media background can be used as extra contextual information to improve recommendation models. Based on an existing deep neural network model, we proposed a method to represent temporal social media background as embeddings and fuse them as an extra component in the model. We conduct experimental evaluations on a real-world e-commerce dataset and a Twitter dataset. The results show that our method of fusing social media background with the existing model does generally improve recommendation performance. In some cases the recommendation accuracy measured by hit-rate@K doubles after fusing with social media background. Our findings can be beneficial for future recommender system designs that consider complex temporal information representing social interests.