 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Fallen Objects Via Asynchronous Audio-Visual Integration
Paper and Code
Jul 07, 2022
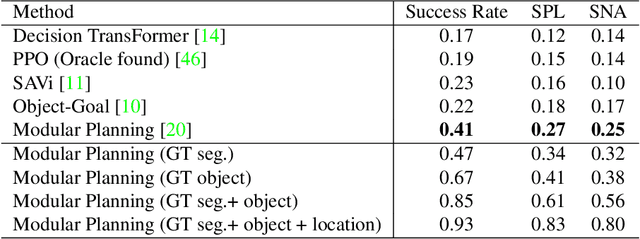

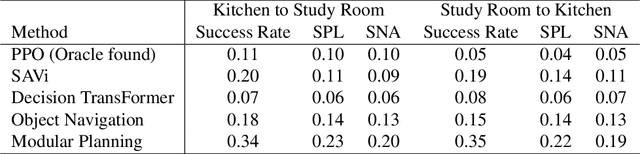
The way an object looks and sounds provide complementary reflections of its physical properties. In many settings cues from vision and audition arrive asynchronously but must be integrated, as when we hear an object dropped on the floor and then must find it. In this paper, we introduce a setting in which to study multi-modal object localization in 3D virtual environments. An object is dropped somewhere in a room. An embodied robot agent, equipped with a camera and microphone, must determine what object has been dropped -- and where -- by combining audio and visual signals with knowledge of the underlying physics. To study this problem, we have generated a large-scale dataset -- the Fallen Objects dataset -- that includes 8000 instances of 30 physical object categories in 64 rooms. The dataset uses the ThreeDWorld platform which can simulate physics-based impact sounds and complex physical interactions between objects in a photorealistic setting. As a first step toward addressing this challenge, we develop a set of embodied agent baselines, based on imitation learning, reinforcement learning, and modular planning, and perform an in-depth analysis of the challenge of this new task.