 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopmental Curiosity and Social Interaction in Virtual Agents
May 22, 2023Infants explore their complex physical and social environment in an organized way. To gain insight into what intrinsic motivations may help structure this exploration, we create a virtual infant agent and place it in a developmentally-inspired 3D environment with no external rewards. The environment has a virtual caregiver agent with the capability to interact contingently with the infant agent in ways that resemble play. We test intrinsic reward functions that are similar to motivations that have been proposed to drive exploration in humans: surprise, uncertainty, novelty, and learning progress. These generic reward functions lead the infant agent to explore its environment and discover the contingencies that are embedded into the caregiver agent. The reward functions that are proxies for novelty and uncertainty are the most successful in generating diverse experiences and activating the environment contingencies. We also find that learning a world model in the presence of an attentive caregiver helps the infant agent learn how to predict scenarios with challenging social and physical dynamics. Taken together, our findings provide insight into how curiosity-like intrinsic rewards and contingent social interaction lead to dynamic social behavior and the creation of a robust predictive world model.
Visual resemblance and communicative context constrain the emergence of graphical conventions
Sep 17, 2021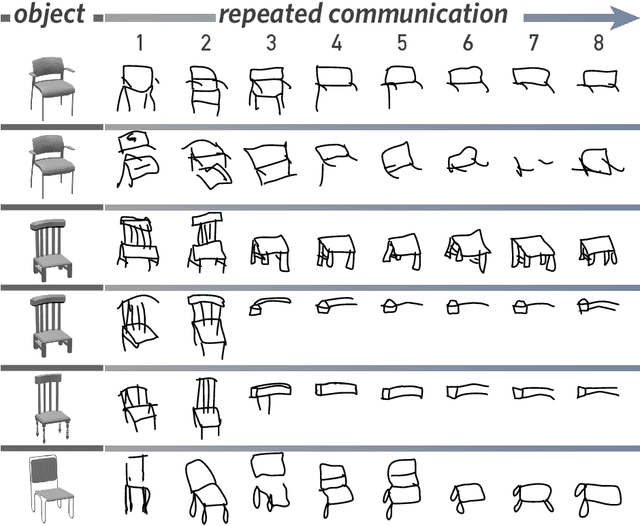
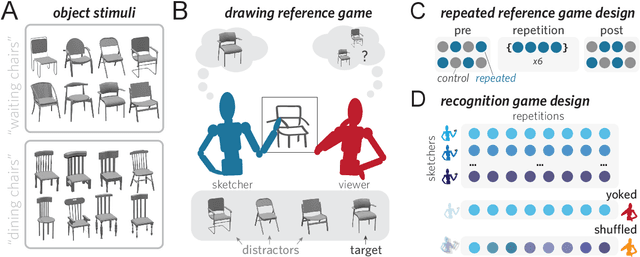
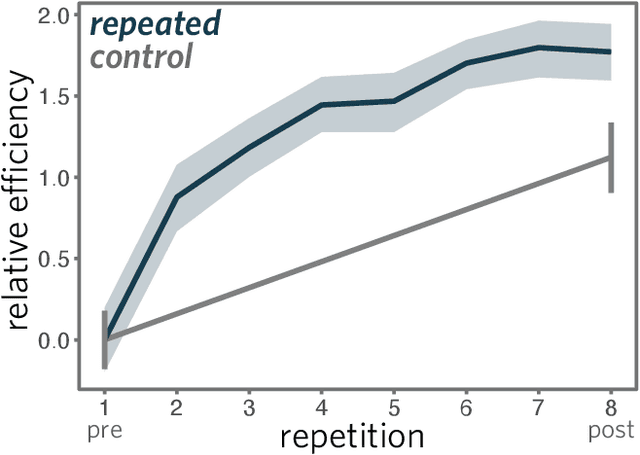
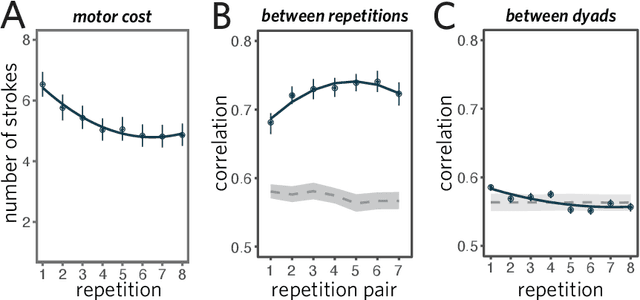
From photorealistic sketches to schematic diagrams, drawing provides a versatile medium for communicating about the visual world. How do images spanning such a broad range of appearances reliably convey meaning? Do viewers understand drawings based solely on their ability to resemble the entities they refer to (i.e., as images), or do they understand drawings based on shared but arbitrary associations with these entities (i.e., as symbols)? In this paper, we provide evidence for a cognitive account of pictorial meaning in which both visual and social information is integrated to support effective visual communication. To evaluate this account, we used a communication task where pairs of participants used drawings to repeatedly communicate the identity of a target object among multiple distractor objects. We manipulated social cues across three experiments and a full internal replication, finding pairs of participants develop referent-specific and interaction-specific strategies for communicating more efficiently over time, going beyond what could be explained by either task practice or a pure resemblance-based account alone. Using a combination of model-based image analyses and crowdsourced sketch annotations, we further determined that drawings did not drift toward arbitrariness, as predicted by a pure convention-based account, but systematically preserved those visual features that were most distinctive of the target object. Taken together, these findings advance theories of pictorial meaning and have implications for how successful graphical conventions emerge via complex interactions between visual perception, communicative experience, and social context.
Active World Model Learning with Progress Curiosity
Jul 15, 2020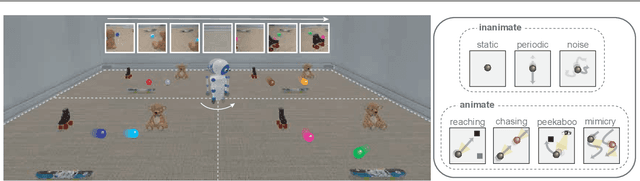
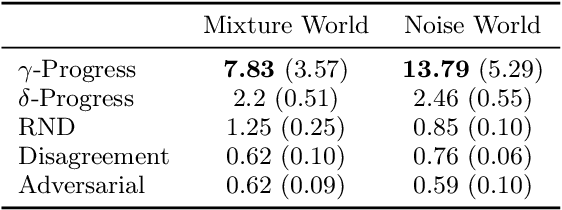
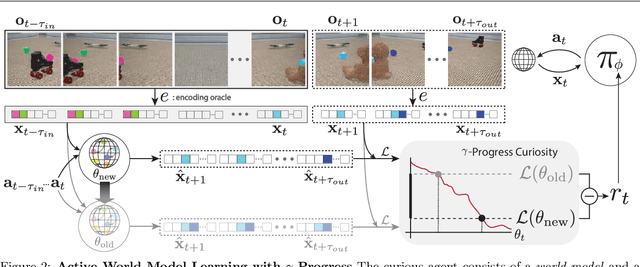
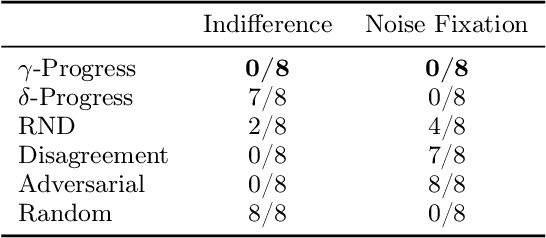
World models are self-supervised predictive models of how the world evolves. Humans learn world models by curiously exploring their environment, in the process acquiring compact abstractions of high bandwidth sensory inputs, the ability to plan across long temporal horizons, and an understanding of the behavioral patterns of other agents. In this work, we study how to design such a curiosity-driven Active World Model Learning (AWML) system. To do so, we construct a curious agent building world models while visually exploring a 3D physical environment rich with distillations of representative real-world agents. We propose an AWML system driven by $\gamma$-Progress: a scalable and effective learning progress-based curiosity signal. We show that $\gamma$-Progress naturally gives rise to an exploration policy that directs attention to complex but learnable dynamics in a balanced manner, thus overcoming the "white noise problem". As a result, our $\gamma$-Progress-driven controller achieves significantly higher AWML performance than baseline controllers equipped with state-of-the-art exploration strategies such as Random Network Distillation and Model Disagreement.
ThreeDWorld: A Platform for Interactive Multi-Modal Physical Simulation
Jul 09, 2020
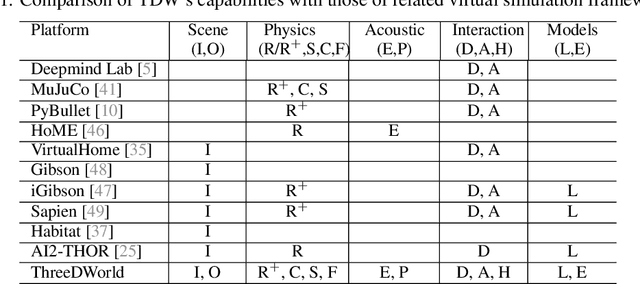

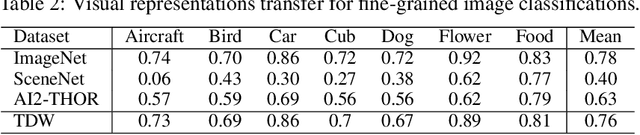
We introduce ThreeDWorld (TDW), a platform for interactive multi-modal physical simulation. With TDW, users can simulate high-fidelity sensory data and physical interactions between mobile agents and objects in a wide variety of rich 3D environments. TDW has several unique properties: 1) realtime near photo-realistic image rendering quality; 2) a library of objects and environments with materials for high-quality rendering, and routines enabling user customization of the asset library; 3) generative procedures for efficiently building classes of new environments 4) high-fidelity audio rendering; 5) believable and realistic physical interactions for a wide variety of material types, including cloths, liquid, and deformable objects; 6) a range of "avatar" types that serve as embodiments of AI agents, with the option for user avatar customization; and 7) support for human interactions with VR devices. TDW also provides a rich API enabling multiple agents to interact within a simulation and return a range of sensor and physics data representing the state of the world. We present initial experiments enabled by the platform around emerging research directions in computer vision, machine learning, and cognitive science, including multi-modal physical scene understanding, multi-agent interactions, models that "learn like a child", and attention studies in humans and neural networks. The simulation platform will be made publicly available.