 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-R1: Do You Really Need Audio to Fine-Tune Your Audio LLM?
May 14, 2025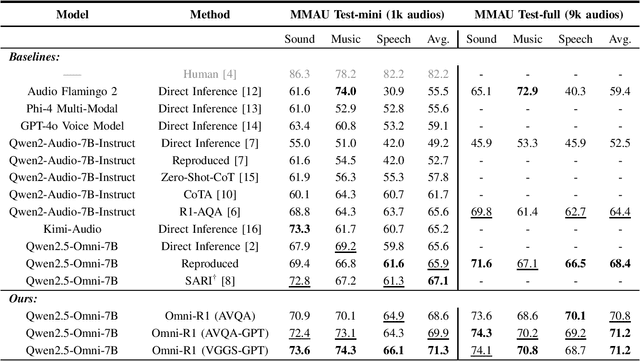
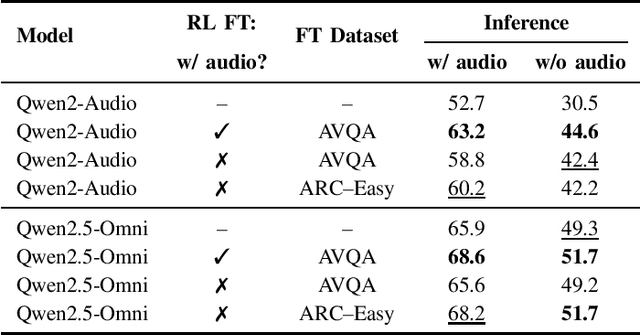
We propose Omni-R1 which fine-tunes a recent multi-modal LLM, Qwen2.5-Omni, on an audio question answering dataset with the reinforcement learning method GRPO. This leads to new State-of-the-Art performance on the recent MMAU benchmark. Omni-R1 achieves the highest accuracies on the sounds, music, speech, and overall average categories, both on the Test-mini and Test-full splits. To understand the performance improvement, we tested models both with and without audio and found that much of the performance improvement from GRPO could be attributed to better text-based reasoning. We also made a surprising discovery that fine-tuning without audio on a text-only dataset was effective at improving the audio-based performance.
CAV-MAE Sync: Improving Contrastive Audio-Visual Mask Autoencoders via Fine-Grained Alignment
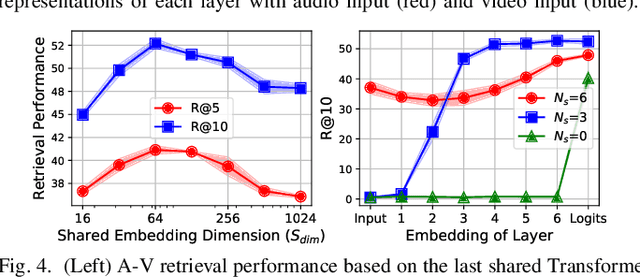
May 02, 2025Recent advances in audio-visual learning have shown promising results in learning representations across modalities. However, most approaches rely on global audio representations that fail to capture fine-grained temporal correspondences with visual frames. Additionally, existing methods often struggle with conflicting optimization objectives when trying to jointly learn reconstruction and cross-modal alignment. In this work, we propose CAV-MAE Sync as a simple yet effective extension of the original CAV-MAE framework for self-supervised audio-visual learning. We address three key challenges: First, we tackle the granularity mismatch between modalities by treating audio as a temporal sequence aligned with video frames, rather than using global representations. Second, we resolve conflicting optimization goals by separating contrastive and reconstruction objectives through dedicated global tokens. Third, we improve spatial localization by introducing learnable register tokens that reduce semantic load on patch tokens. We evaluate the proposed approach on AudioSet, VGG Sound, and the ADE20K Sound dataset on zero-shot retrieval, classification and localization tasks demonstrating state-of-the-art performance and outperforming more complex architectures.
mWhisper-Flamingo for Multilingual Audio-Visual Noise-Robust Speech Recognition
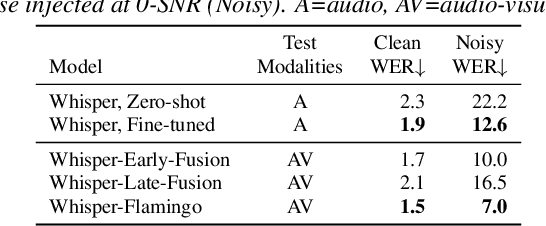
Feb 03, 2025Audio-Visual Speech Recognition (AVSR) combines lip-based video with audio and can improve performance in noise, but most methods are trained only on English data. One limitation is the lack of large-scale multilingual video data, which makes it hard hard to train models from scratch. In this work, we propose mWhisper-Flamingo for multilingual AVSR which combines the strengths of a pre-trained audio model (Whisper) and video model (AV-HuBERT). To enable better multi-modal integration and improve the noisy multilingual performance, we introduce decoder modality dropout where the model is trained both on paired audio-visual inputs and separate audio/visual inputs. mWhisper-Flamingo achieves state-of-the-art WER on MuAViC, an AVSR dataset of 9 languages. Audio-visual mWhisper-Flamingo consistently outperforms audio-only Whisper on all languages in noisy conditions.
Whisper-Flamingo: Integrating Visual Features into Whisper for Audio-Visual Speech Recognition and Translation
Jun 14, 2024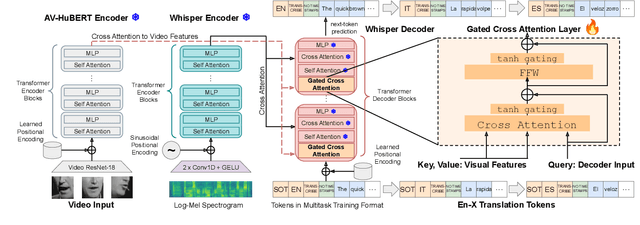
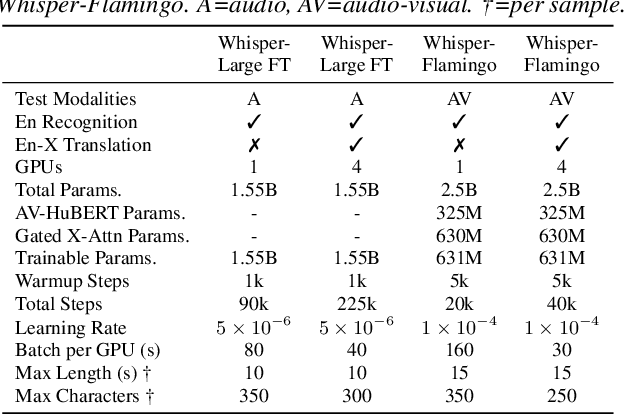
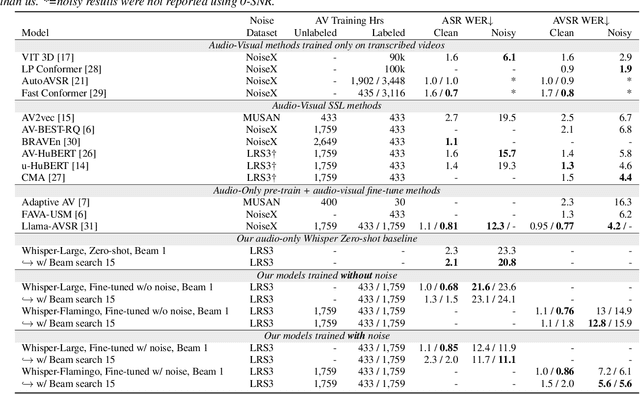
Audio-Visual Speech Recognition (AVSR) uses lip-based video to improve performance in noise. Since videos are harder to obtain than audio, the video training data of AVSR models is usually limited to a few thousand hours. In contrast, speech models such as Whisper are trained with hundreds of thousands of hours of data, and thus learn a better speech-to-text decoder. The huge training data difference motivates us to adapt Whisper to handle video inputs. Inspired by Flamingo which injects visual features into language models, we propose Whisper-Flamingo which integrates visual features into the Whisper speech recognition and translation model with gated cross attention. Our audio-visual Whisper-Flamingo outperforms audio-only Whisper on English speech recognition and En-X translation for 6 languages in noisy conditions. Moreover, Whisper-Flamingo is a versatile model and conducts all of these tasks using one set of parameters, while prior methods are trained separately on each language.
AV-CPL: Continuous Pseudo-Labeling for Audio-Visual Speech Recognition
Sep 29, 2023Audio-visual speech contains synchronized audio and visual information that provides cross-modal supervision to learn representations for both automatic speech recognition (ASR) and visual speech recognition (VSR). We introduce continuous pseudo-labeling for audio-visual speech recognition (AV-CPL), a semi-supervised method to train an audio-visual speech recognition (AVSR) model on a combination of labeled and unlabeled videos with continuously regenerated pseudo-labels. Our models are trained for speech recognition from audio-visual inputs and can perform speech recognition using both audio and visual modalities, or only one modality. Our method uses the same audio-visual model for both supervised training and pseudo-label generation, mitigating the need for external speech recognition models to generate pseudo-labels. AV-CPL obtains significant improvements in VSR performance on the LRS3 dataset while maintaining practical ASR and AVSR performance. Finally, using visual-only speech data, our method is able to leverage unlabeled visual speech to improve VSR.
Comparison of Multilingual Self-Supervised and Weakly-Supervised Speech Pre-Training for Adaptation to Unseen Languages
May 21, 2023



Recent models such as XLS-R and Whisper have made multilingual speech technologies more accessible by pre-training on audio from around 100 spoken languages each. However, there are thousands of spoken languages worldwide, and adapting to new languages is an important problem. In this work, we aim to understand which model adapts better to languages unseen during pre-training. We fine-tune both models on 13 unseen languages and 18 seen languages. Our results show that the number of hours seen per language and language family during pre-training is predictive of how the models compare, despite the significant differences in the pre-training methods.
What, when, and where? -- Self-Supervised Spatio-Temporal Grounding in Untrimmed Multi-Action Videos from Narrated Instructions
Mar 29, 2023Spatio-temporal grounding describes the task of localizing events in space and time, e.g., in video data, based on verbal descriptions only. Models for this task are usually trained with human-annotated sentences and bounding box supervision. This work addresses this task from a multimodal supervision perspective, proposing a framework for spatio-temporal action grounding trained on loose video and subtitle supervision only, without human annotation. To this end, we combine local representation learning, which focuses on leveraging fine-grained spatial information, with a global representation encoding that captures higher-level representations and incorporates both in a joint approach. To evaluate this challenging task in a real-life setting, a new benchmark dataset is proposed providing dense spatio-temporal grounding annotations in long, untrimmed, multi-action instructional videos for over 5K events. We evaluate the proposed approach and other methods on the proposed and standard downstream tasks showing that our method improves over current baselines in various settings, including spatial, temporal, and untrimmed multi-action spatio-temporal grounding.
C2KD: Cross-Lingual Cross-Modal Knowledge Distillation for Multilingual Text-Video Retrieval
Oct 07, 2022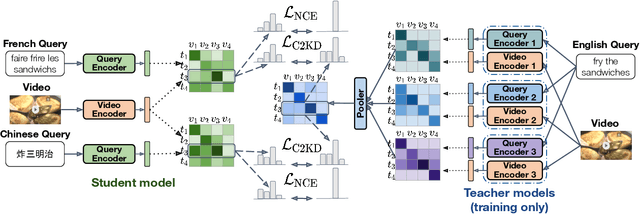
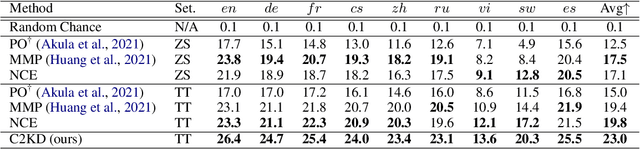

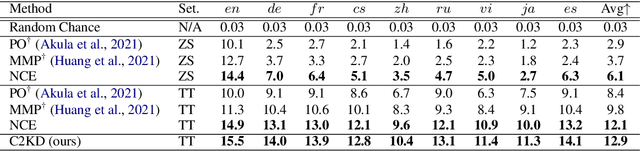
Multilingual text-video retrieval methods have improved significantly in recent years, but the performance for other languages lags behind English. We propose a Cross-Lingual Cross-Modal Knowledge Distillation method to improve multilingual text-video retrieval. Inspired by the fact that English text-video retrieval outperforms other languages, we train a student model using input text in different languages to match the cross-modal predictions from teacher models using input text in English. We propose a cross entropy based objective which forces the distribution over the student's text-video similarity scores to be similar to those of the teacher models. We introduce a new multilingual video dataset, Multi-YouCook2, by translating the English captions in the YouCook2 video dataset to 8 other languages. Our method improves multilingual text-video retrieval performance on Multi-YouCook2 and several other datasets such as Multi-MSRVTT and VATEX. We also conducted an analysis on the effectiveness of different multilingual text models as teachers.
UAVM: A Unified Model for Audio-Visual Learning
Jul 29, 2022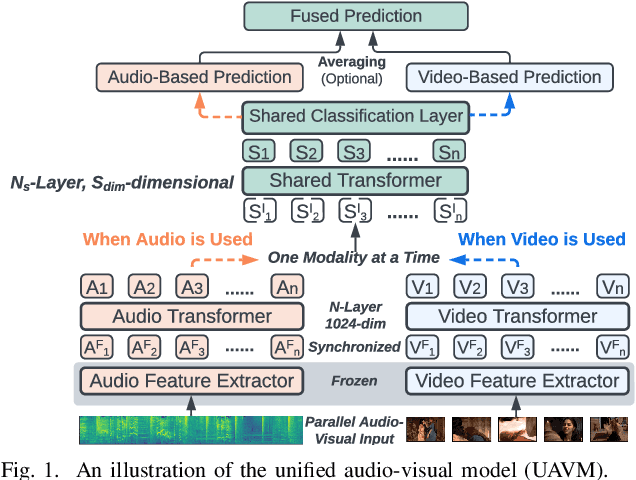
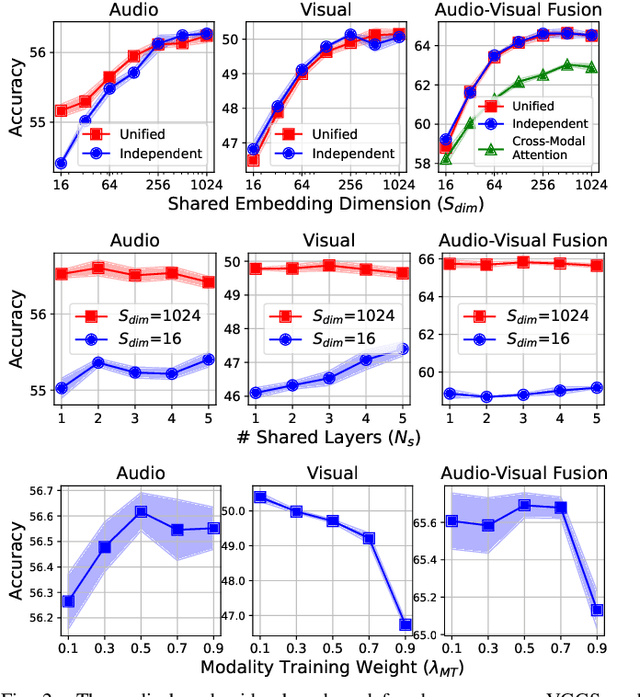
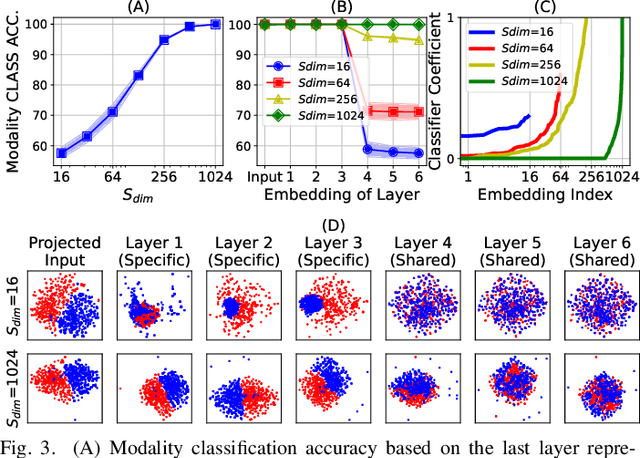
Conventional audio-visual models have independent audio and video branches. We design a unified model for audio and video processing called Unified Audio-Visual Model (UAVM). In this paper, we describe UAVM, report its new state-of-the-art audio-visual event classification accuracy of 65.8% on VGGSound, and describe the intriguing properties of the model.
CMKD: CNN/Transformer-Based Cross-Model Knowledge Distillation for Audio Classification
Mar 13, 2022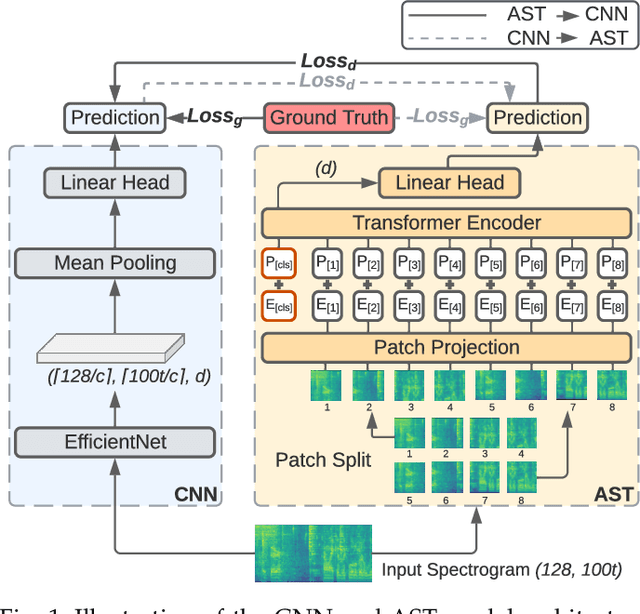
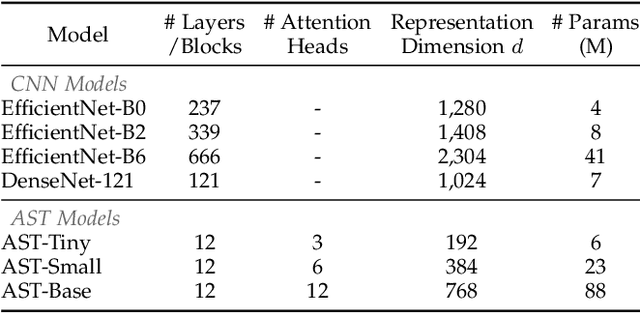

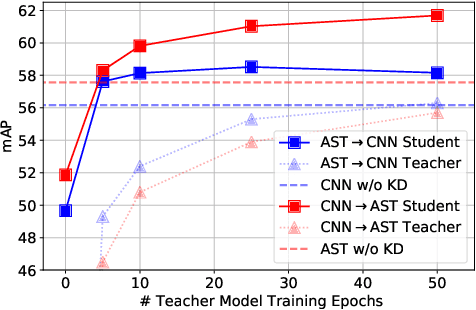
Audio classification is an active research area with a wide range of applications. Over the past decade, convolutional neural networks (CNNs) have been the de-facto standard building block for end-to-end audio classification models. Recently, neural networks based solely on self-attention mechanisms such as the Audio Spectrogram Transformer (AST) have been shown to outperform CNNs. In this paper, we find an intriguing interaction between the two very different models - CNN and AST models are good teachers for each other. When we use either of them as the teacher and train the other model as the student via knowledge distillation (KD), the performance of the student model noticeably improves, and in many cases, is better than the teacher model. In our experiments with this CNN/Transformer Cross-Model Knowledge Distillation (CMKD) method we achieve new state-of-the-art performance on FSD50K, AudioSet, and ESC-50.