 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgestudentSplat: Your Student Model Learns Single-view 3D Gaussian Splatting
Jan 16, 2026Recent advance in feed-forward 3D Gaussian splatting has enable remarkable multi-view 3D scene reconstruction or single-view 3D object reconstruction but single-view 3D scene reconstruction remain under-explored due to inherited ambiguity in single-view. We present \textbf{studentSplat}, a single-view 3D Gaussian splatting method for scene reconstruction. To overcome the scale ambiguity and extrapolation problems inherent in novel-view supervision from a single input, we introduce two techniques: 1) a teacher-student architecture where a multi-view teacher model provides geometric supervision to the single-view student during training, addressing scale ambiguity and encourage geometric validity; and 2) an extrapolation network that completes missing scene context, enabling high-quality extrapolation. Extensive experiments show studentSplat achieves state-of-the-art single-view novel-view reconstruction quality and comparable performance to multi-view methods at the scene level. Furthermore, studentSplat demonstrates competitive performance as a self-supervised single-view depth estimation method, highlighting its potential for general single-view 3D understanding tasks.
Robust Egocentric Visual Attention Prediction Through Language-guided Scene Context-aware Learning
Jan 05, 2026As the demand for analyzing egocentric videos grows, egocentric visual attention prediction, anticipating where a camera wearer will attend, has garnered increasing attention. However, it remains challenging due to the inherent complexity and ambiguity of dynamic egocentric scenes. Motivated by evidence that scene contextual information plays a crucial role in modulating human attention, in this paper, we present a language-guided scene context-aware learning framework for robust egocentric visual attention prediction. We first design a context perceiver which is guided to summarize the egocentric video based on a language-based scene description, generating context-aware video representations. We then introduce two training objectives that: 1) encourage the framework to focus on the target point-of-interest regions and 2) suppress distractions from irrelevant regions which are less likely to attract first-person attention. Extensive experiments on Ego4D and Aria Everyday Activities (AEA) datasets demonstrate the effectiveness of our approach, achieving state-of-the-art performance and enhanced robustness across diverse, dynamic egocentric scenarios.
Dynamically pruning segformer for efficient semantic segmentation
Nov 18, 2021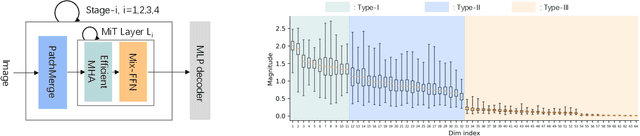
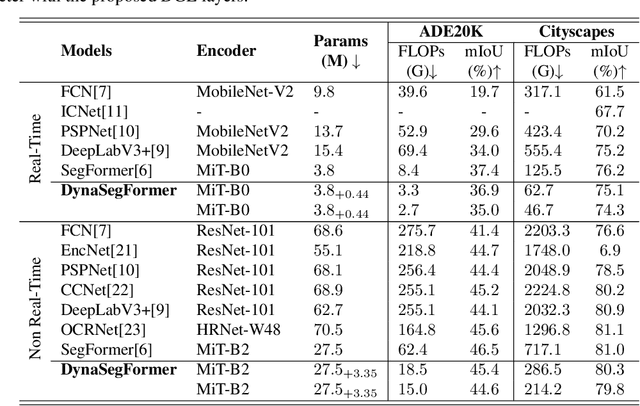
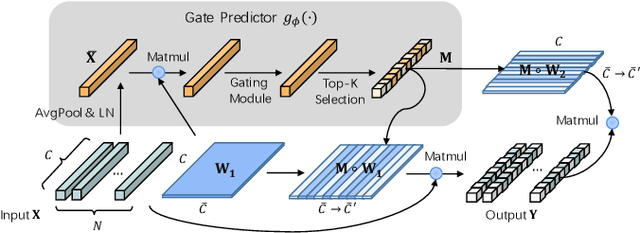
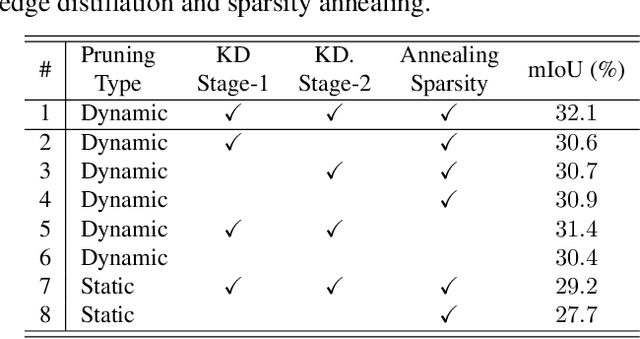
As one of the successful Transformer-based models in computer vision tasks, SegFormer demonstrates superior performance in semantic segmentation. Nevertheless, the high computational cost greatly challenges the deployment of SegFormer on edge devices. In this paper, we seek to design a lightweight SegFormer for efficient semantic segmentation. Based on the observation that neurons in SegFormer layers exhibit large variances across different images, we propose a dynamic gated linear layer, which prunes the most uninformative set of neurons based on the input instance. To improve the dynamically pruned SegFormer, we also introduce two-stage knowledge distillation to transfer the knowledge within the original teacher to the pruned student network. Experimental results show that our method can significantly reduce the computation overhead of SegFormer without an apparent performance drop. For instance, we can achieve 36.9% mIoU with only 3.3G FLOPs on ADE20K, saving more than 60% computation with the drop of only 0.5% in mIoU
Fusion of Embeddings Networks for Robust Combination of Text Dependent and Independent Speaker Recognition
Jun 18, 2021


By implicitly recognizing a user based on his/her speech input, speaker identification enables many downstream applications, such as personalized system behavior and expedited shopping checkouts. Based on whether the speech content is constrained or not, both text-dependent (TD) and text-independent (TI) speaker recognition models may be used. We wish to combine the advantages of both types of models through an ensemble system to make more reliable predictions. However, any such combined approach has to be robust to incomplete inputs, i.e., when either TD or TI input is missing. As a solution we propose a fusion of embeddings network foenet architecture, combining joint learning with neural attention. We compare foenet with four competitive baseline methods on a dataset of voice assistant inputs, and show that it achieves higher accuracy than the baseline and score fusion methods, especially in the presence of incomplete inputs.