 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws for Acoustic Models
Paper and Code
Jun 11, 2021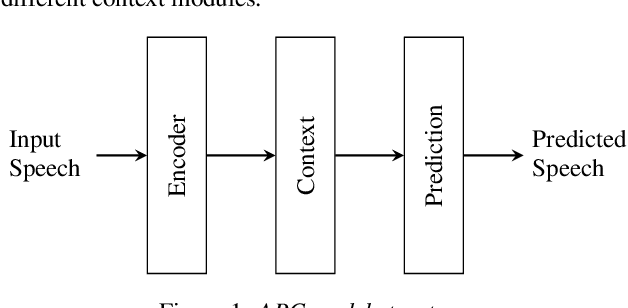


There is a recent trend in machine learning to increase model quality by growing models to sizes previously thought to be unreasonable. Recent work has shown that autoregressive generative models with cross-entropy objective functions exhibit smooth power-law relationships, or scaling laws, that predict model quality from model size, training set size, and the available compute budget. These scaling laws allow one to choose nearly optimal hyper-parameters given constraints on available training data, model parameter count, or training computation budget. In this paper, we demonstrate that acoustic models trained with an auto-predictive coding loss behave as if they are subject to similar scaling laws. We extend previous work to jointly predict loss due to model size, to training set size, and to the inherent "irreducible loss" of the task. We find that the scaling laws accurately match model performance over two orders of magnitude in both model size and training set size, and make predictions about the limits of model performance.