 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving speaker verification robustness with synthetic emotional utterances
Nov 30, 2024



A speaker verification (SV) system offers an authentication service designed to confirm whether a given speech sample originates from a specific speaker. This technology has paved the way for various personalized applications that cater to individual preferences. A noteworthy challenge faced by SV systems is their ability to perform consistently across a range of emotional spectra. Most existing models exhibit high error rates when dealing with emotional utterances compared to neutral ones. Consequently, this phenomenon often leads to missing out on speech of interest. This issue primarily stems from the limited availability of labeled emotional speech data, impeding the development of robust speaker representations that encompass diverse emotional states. To address this concern, we propose a novel approach employing the CycleGAN framework to serve as a data augmentation method. This technique synthesizes emotional speech segments for each specific speaker while preserving the unique vocal identity. Our experimental findings underscore the effectiveness of incorporating synthetic emotional data into the training process. The models trained using this augmented dataset consistently outperform the baseline models on the task of verifying speakers in emotional speech scenarios, reducing equal error rate by as much as 3.64% relative.
Adversarial Reweighting for Speaker Verification Fairness
Jul 15, 2022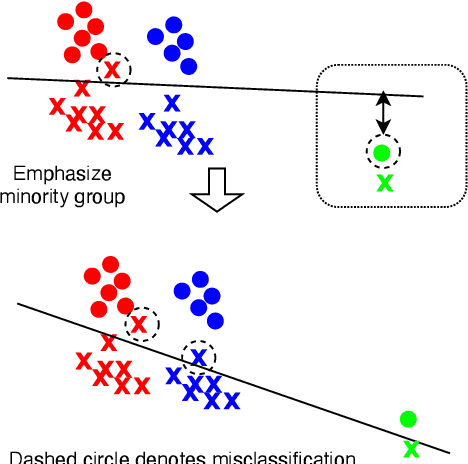
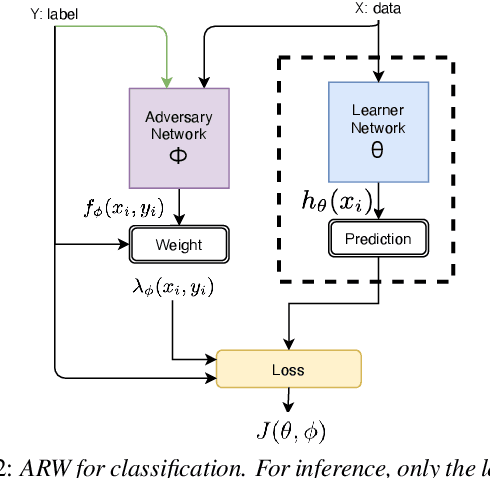
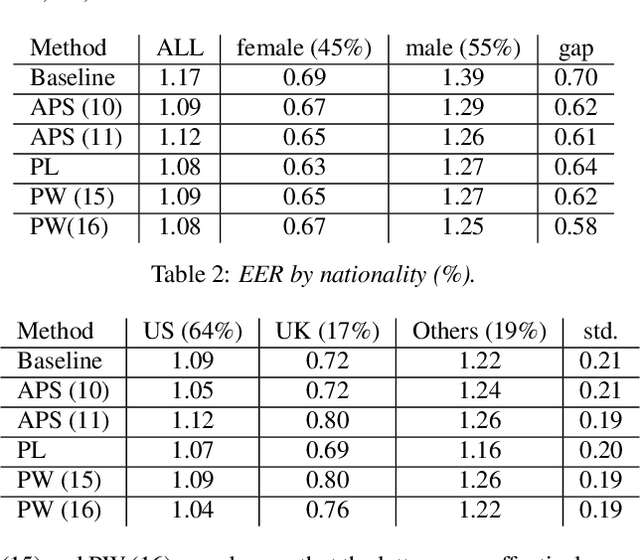
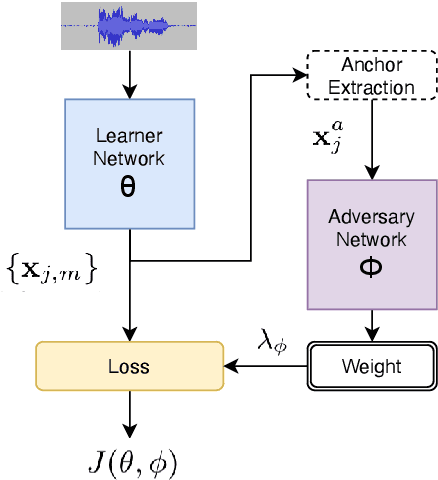
We address performance fairness for speaker verification using the adversarial reweighting (ARW) method. ARW is reformulated for speaker verification with metric learning, and shown to improve results across different subgroups of gender and nationality, without requiring annotation of subgroups in the training data. An adversarial network learns a weight for each training sample in the batch so that the main learner is forced to focus on poorly performing instances. Using a min-max optimization algorithm, this method improves overall speaker verification fairness. We present three different ARWformulations: accumulated pairwise similarity, pseudo-labeling, and pairwise weighting, and measure their performance in terms of equal error rate (EER) on the VoxCeleb corpus. Results show that the pairwise weighting method can achieve 1.08% overall EER, 1.25% for male and 0.67% for female speakers, with relative EER reductions of 7.7%, 10.1% and 3.0%, respectively. For nationality subgroups, the proposed algorithm showed 1.04% EER for US speakers, 0.76% for UK speakers, and 1.22% for all others. The absolute EER gap between gender groups was reduced from 0.70% to 0.58%, while the standard deviation over nationality groups decreased from 0.21 to 0.19.
openFEAT: Improving Speaker Identification by Open-set Few-shot Embedding Adaptation with Transformer
Feb 24, 2022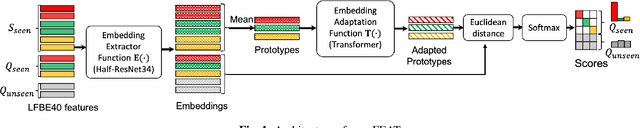
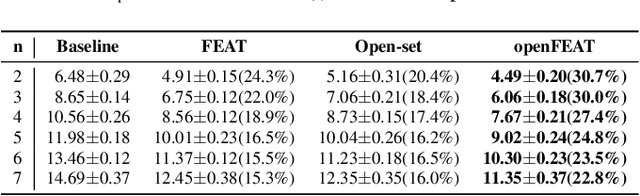
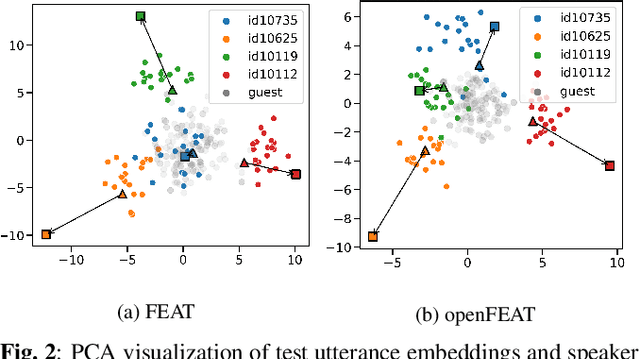
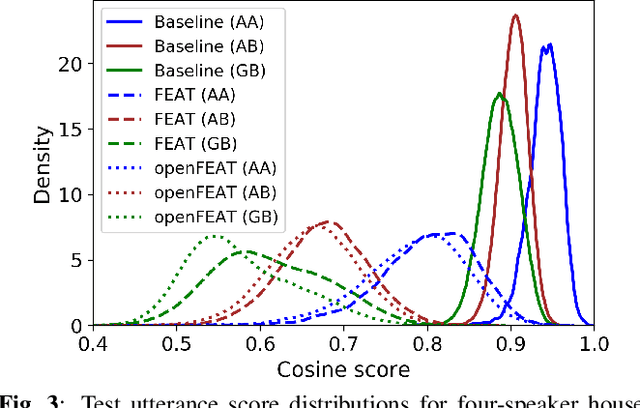
Household speaker identification with few enrollment utterances is an important yet challenging problem, especially when household members share similar voice characteristics and room acoustics. A common embedding space learned from a large number of speakers is not universally applicable for the optimal identification of every speaker in a household. In this work, we first formulate household speaker identification as a few-shot open-set recognition task and then propose a novel embedding adaptation framework to adapt speaker representations from the given universal embedding space to a household-specific embedding space using a set-to-set function, yielding better household speaker identification performance. With our algorithm, Open-set Few-shot Embedding Adaptation with Transformer (openFEAT), we observe that the speaker identification equal error rate (IEER) on simulated households with 2 to 7 hard-to-discriminate speakers is reduced by 23% to 31% relative.
Contrastive-mixup learning for improved speaker verification
Feb 22, 2022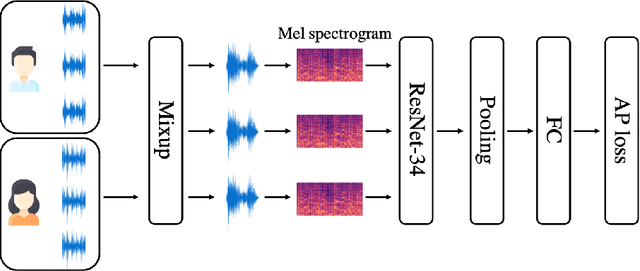
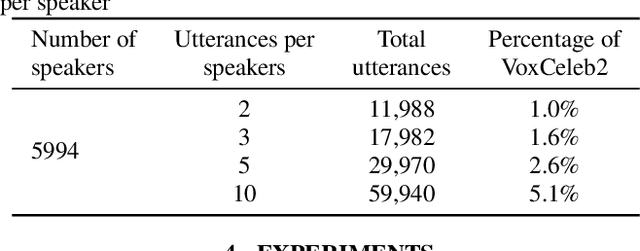

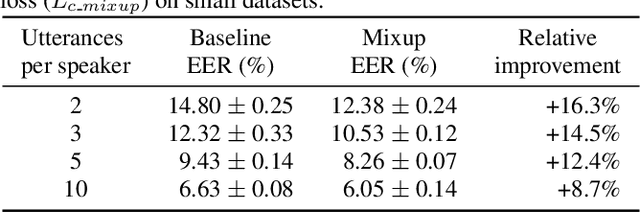
This paper proposes a novel formulation of prototypical loss with mixup for speaker verification. Mixup is a simple yet efficient data augmentation technique that fabricates a weighted combination of random data point and label pairs for deep neural network training. Mixup has attracted increasing attention due to its ability to improve robustness and generalization of deep neural networks. Although mixup has shown success in diverse domains, most applications have centered around closed-set classification tasks. In this work, we propose contrastive-mixup, a novel augmentation strategy that learns distinguishing representations based on a distance metric. During training, mixup operations generate convex interpolations of both inputs and virtual labels. Moreover, we have reformulated the prototypical loss function such that mixup is enabled on metric learning objectives. To demonstrate its generalization given limited training data, we conduct experiments by varying the number of available utterances from each speaker in the VoxCeleb database. Experimental results show that applying contrastive-mixup outperforms the existing baseline, reducing error rate by 16% relatively, especially when the number of training utterances per speaker is limited.
Learning and Evaluating Representations for Deep One-class Classification
Nov 04, 2020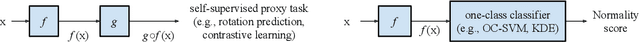



We present a two-stage framework for deep one-class classification. We first learn self-supervised representations from one-class data, and then build one-class classifiers on learned representations. The framework not only allows to learn better representations, but also permits building one-class classifiers that are faithful to the target task. In particular, we present a novel distribution-augmented contrastive learning that extends training distributions via data augmentation to obstruct the uniformity of contrastive representations. Moreover, we argue that classifiers inspired by the statistical perspective in generative or discriminative models are more effective than existing approaches, such as an average of normality scores from a surrogate classifier. In experiments, we demonstrate state-of-the-art performance on visual domain one-class classification benchmarks. Finally, we present visual explanations, confirming that the decision-making process of our deep one-class classifier is intuitive to humans. The code is available at: https://github.com/google-research/google-research/tree/master/deep_representation_one_class.
A Streaming On-Device End-to-End Model Surpassing Server-Side Conventional Model Quality and Latency
Mar 28, 2020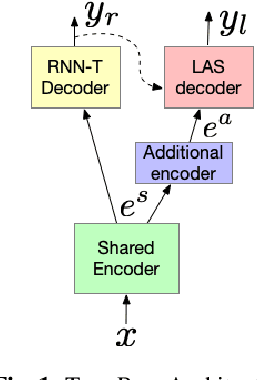
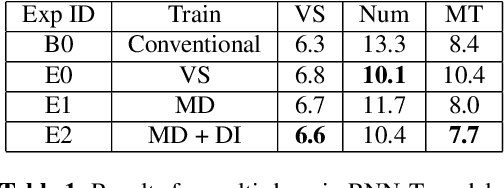
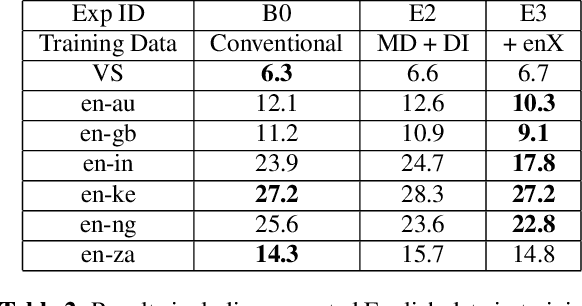
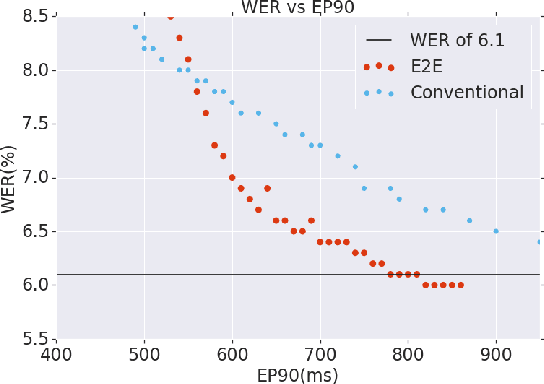
Thus far, end-to-end (E2E) models have not been shown to outperform state-of-the-art conventional models with respect to both quality, i.e., word error rate (WER), and latency, i.e., the time the hypothesis is finalized after the user stops speaking. In this paper, we develop a first-pass Recurrent Neural Network Transducer (RNN-T) model and a second-pass Listen, Attend, Spell (LAS) rescorer that surpasses a conventional model in both quality and latency. On the quality side, we incorporate a large number of utterances across varied domains to increase acoustic diversity and the vocabulary seen by the model. We also train with accented English speech to make the model more robust to different pronunciations. In addition, given the increased amount of training data, we explore a varied learning rate schedule. On the latency front, we explore using the end-of-sentence decision emitted by the RNN-T model to close the microphone, and also introduce various optimizations to improve the speed of LAS rescoring. Overall, we find that RNN-T+LAS offers a better WER and latency tradeoff compared to a conventional model. For example, for the same latency, RNN-T+LAS obtains a 8% relative improvement in WER, while being more than 400-times smaller in model size.