 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Neighborhood Adaptation for Graph Neural Networks
Feb 05, 2026The neighborhood scope (i.e., number of hops) where graph neural networks (GNNs) aggregate information to characterize a node's statistical property is critical to GNNs' performance. Two-stage approaches, training and validating GNNs for every pre-specified neighborhood scope to search for the best setting, is a time-consuming task and tends to be biased due to the search space design. How to adaptively determine proper neighborhood scopes for the aggregation process for both homophilic and heterophilic graphs remains largely unexplored. We thus propose to model the GNNs' message-passing behavior on a graph as a stochastic process by treating the number of hops as a beta process. This Bayesian framework allows us to infer the most plausible neighborhood scope for message aggregation simultaneously with the optimization of GNN parameters. Our theoretical analysis shows that the scope inference improves the expressivity of a GNN. Experiments on benchmark homophilic and heterophilic datasets show that the proposed method is compatible with state-of-the-art GNN variants, achieving competitive or superior performance on the node classification task, and providing well-calibrated predictions.
openFEAT: Improving Speaker Identification by Open-set Few-shot Embedding Adaptation with Transformer
Feb 24, 2022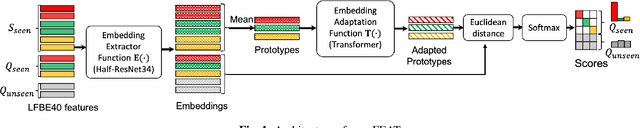
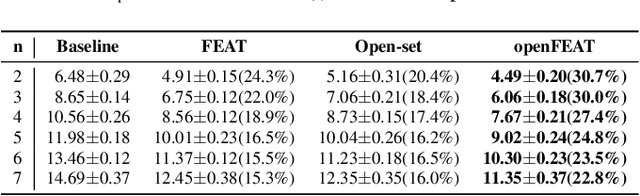
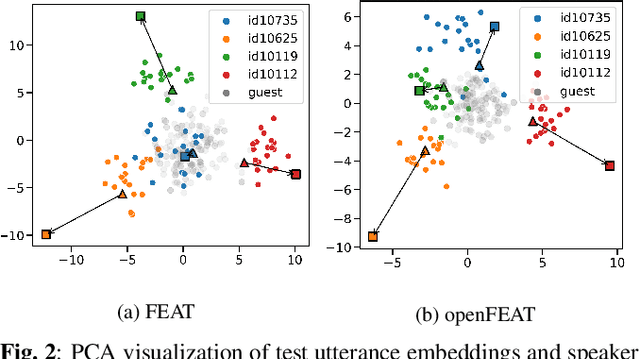
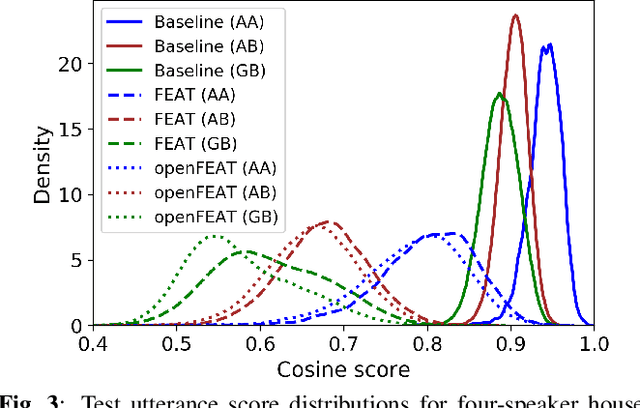
Household speaker identification with few enrollment utterances is an important yet challenging problem, especially when household members share similar voice characteristics and room acoustics. A common embedding space learned from a large number of speakers is not universally applicable for the optimal identification of every speaker in a household. In this work, we first formulate household speaker identification as a few-shot open-set recognition task and then propose a novel embedding adaptation framework to adapt speaker representations from the given universal embedding space to a household-specific embedding space using a set-to-set function, yielding better household speaker identification performance. With our algorithm, Open-set Few-shot Embedding Adaptation with Transformer (openFEAT), we observe that the speaker identification equal error rate (IEER) on simulated households with 2 to 7 hard-to-discriminate speakers is reduced by 23% to 31% relative.