 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Language Models in Conversational Recommender Systems
May 16, 2023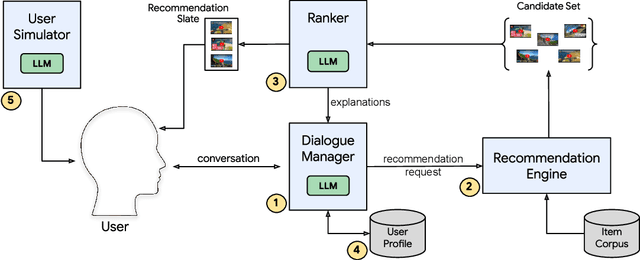



A Conversational Recommender System (CRS) offers increased transparency and control to users by enabling them to engage with the system through a real-time multi-turn dialogue. Recently, Large Language Models (LLMs) have exhibited an unprecedented ability to converse naturally and incorporate world knowledge and common-sense reasoning into language understanding, unlocking the potential of this paradigm. However, effectively leveraging LLMs within a CRS introduces new technical challenges, including properly understanding and controlling a complex conversation and retrieving from external sources of information. These issues are exacerbated by a large, evolving item corpus and a lack of conversational data for training. In this paper, we provide a roadmap for building an end-to-end large-scale CRS using LLMs. In particular, we propose new implementations for user preference understanding, flexible dialogue management and explainable recommendations as part of an integrated architecture powered by LLMs. For improved personalization, we describe how an LLM can consume interpretable natural language user profiles and use them to modulate session-level context. To overcome conversational data limitations in the absence of an existing production CRS, we propose techniques for building a controllable LLM-based user simulator to generate synthetic conversations. As a proof of concept we introduce RecLLM, a large-scale CRS for YouTube videos built on LaMDA, and demonstrate its fluency and diverse functionality through some illustrative example conversations.
openFEAT: Improving Speaker Identification by Open-set Few-shot Embedding Adaptation with Transformer
Feb 24, 2022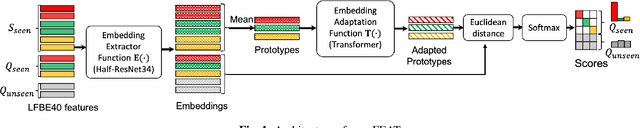
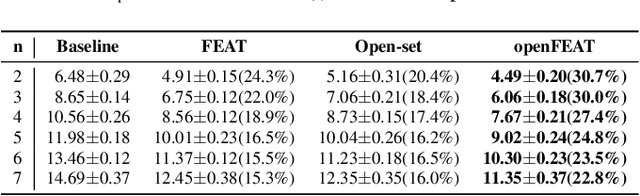
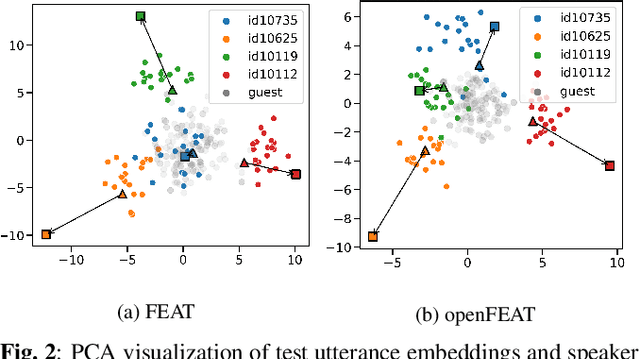
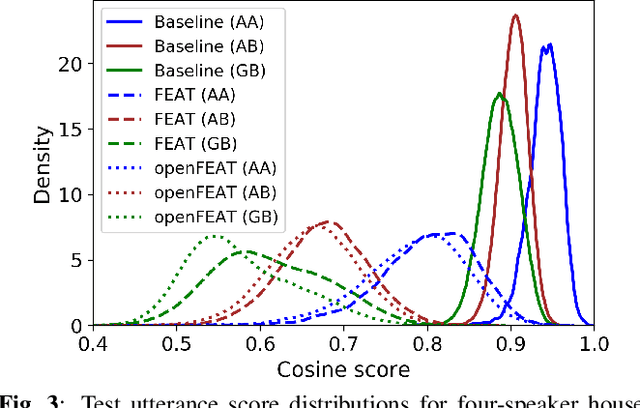
Household speaker identification with few enrollment utterances is an important yet challenging problem, especially when household members share similar voice characteristics and room acoustics. A common embedding space learned from a large number of speakers is not universally applicable for the optimal identification of every speaker in a household. In this work, we first formulate household speaker identification as a few-shot open-set recognition task and then propose a novel embedding adaptation framework to adapt speaker representations from the given universal embedding space to a household-specific embedding space using a set-to-set function, yielding better household speaker identification performance. With our algorithm, Open-set Few-shot Embedding Adaptation with Transformer (openFEAT), we observe that the speaker identification equal error rate (IEER) on simulated households with 2 to 7 hard-to-discriminate speakers is reduced by 23% to 31% relative.
Improving Speaker Identification for Shared Devices by Adapting Embeddings to Speaker Subsets
Sep 06, 2021
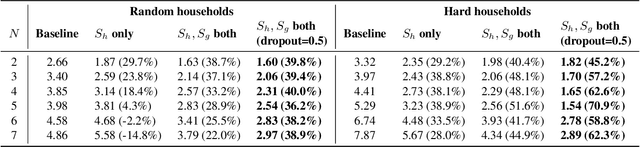
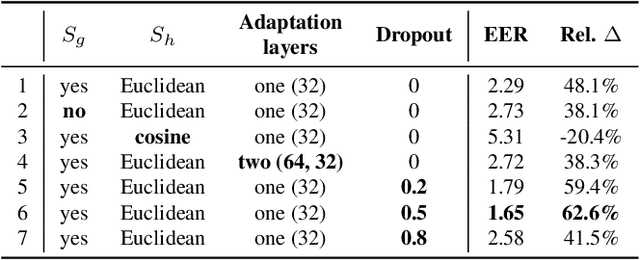
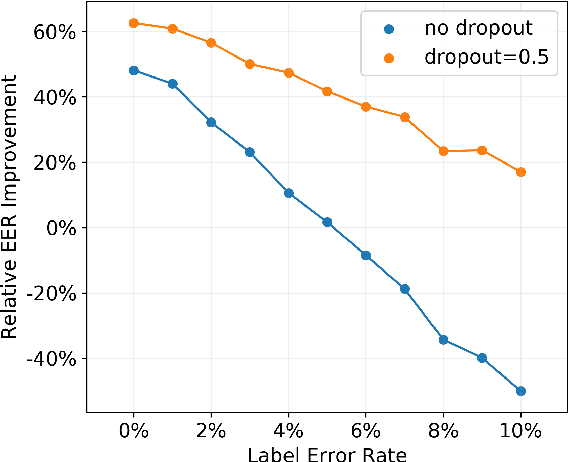
Speaker identification typically involves three stages. First, a front-end speaker embedding model is trained to embed utterance and speaker profiles. Second, a scoring function is applied between a runtime utterance and each speaker profile. Finally, the speaker is identified using nearest neighbor according to the scoring metric. To better distinguish speakers sharing a device within the same household, we propose a household-adapted nonlinear mapping to a low dimensional space to complement the global scoring metric. The combined scoring function is optimized on labeled or pseudo-labeled speaker utterances. With input dropout, the proposed scoring model reduces EER by 45-71% in simulated households with 2 to 7 hard-to-discriminate speakers per household. On real-world internal data, the EER reduction is 49.2%. From t-SNE visualization, we also show that clusters formed by household-adapted speaker embeddings are more compact and uniformly distributed, compared to clusters formed by global embeddings before adaptation.