 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeopenFEAT: Improving Speaker Identification by Open-set Few-shot Embedding Adaptation with Transformer
Feb 24, 2022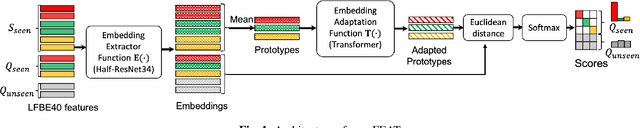
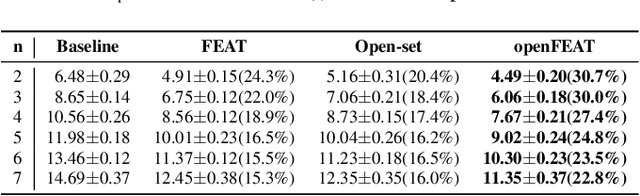
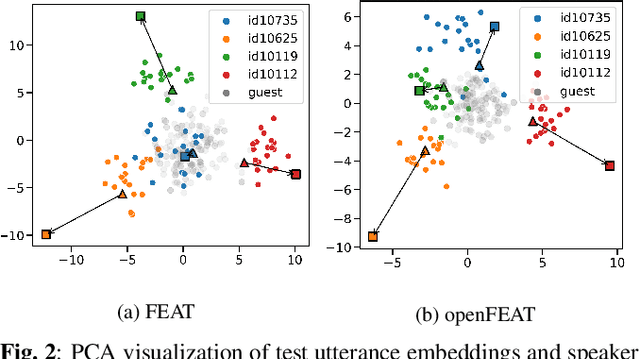
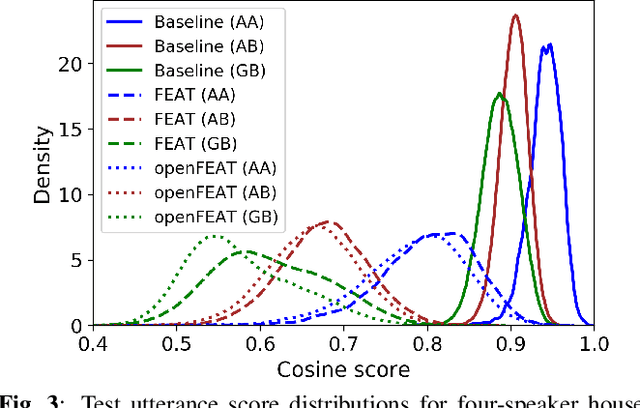
Household speaker identification with few enrollment utterances is an important yet challenging problem, especially when household members share similar voice characteristics and room acoustics. A common embedding space learned from a large number of speakers is not universally applicable for the optimal identification of every speaker in a household. In this work, we first formulate household speaker identification as a few-shot open-set recognition task and then propose a novel embedding adaptation framework to adapt speaker representations from the given universal embedding space to a household-specific embedding space using a set-to-set function, yielding better household speaker identification performance. With our algorithm, Open-set Few-shot Embedding Adaptation with Transformer (openFEAT), we observe that the speaker identification equal error rate (IEER) on simulated households with 2 to 7 hard-to-discriminate speakers is reduced by 23% to 31% relative.
Improving fairness in speaker verification via Group-adapted Fusion Network
Feb 23, 2022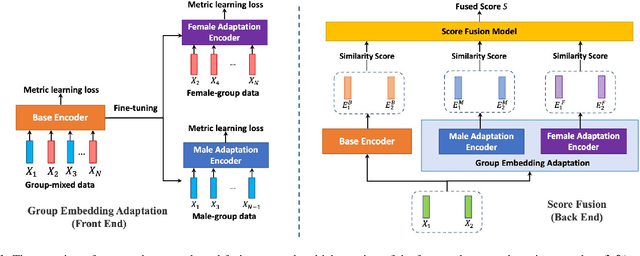
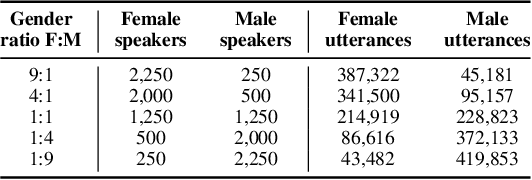

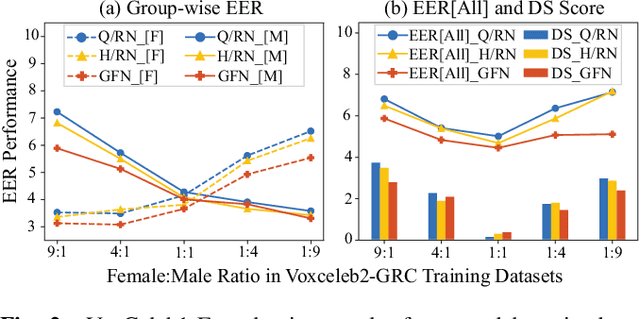
Modern speaker verification models use deep neural networks to encode utterance audio into discriminative embedding vectors. During the training process, these networks are typically optimized to differentiate arbitrary speakers. This learning process biases the learning of fine voice characteristics towards dominant demographic groups, which can lead to an unfair performance disparity across different groups. This is observed especially with underrepresented demographic groups sharing similar voice characteristics. In this work, we investigate the fairness of speaker verification models on controlled datasets with imbalanced gender distributions, providing direct evidence that model performance suffers for underrepresented groups. To mitigate this disparity we propose the group-adapted fusion network (GFN) architecture, a modular architecture based on group embedding adaptation and score fusion. We show that our method alleviates model unfairness by improving speaker verification both overall and for individual groups. Given imbalanced group representation in training, our proposed method achieves overall equal error rate (EER) reduction of 9.6% to 29.0% relative, reduces minority group EER by 13.7% to 18.6%, and results in 20.0% to 25.4% less EER disparity, compared to baselines. The approach is applicable to other types of training data skew in speaker recognition systems.
Contrastive-mixup learning for improved speaker verification
Feb 22, 2022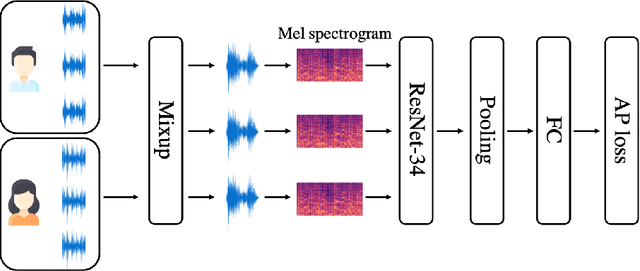

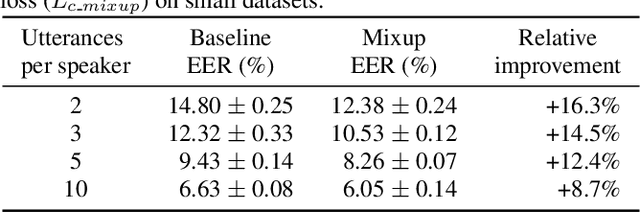
This paper proposes a novel formulation of prototypical loss with mixup for speaker verification. Mixup is a simple yet efficient data augmentation technique that fabricates a weighted combination of random data point and label pairs for deep neural network training. Mixup has attracted increasing attention due to its ability to improve robustness and generalization of deep neural networks. Although mixup has shown success in diverse domains, most applications have centered around closed-set classification tasks. In this work, we propose contrastive-mixup, a novel augmentation strategy that learns distinguishing representations based on a distance metric. During training, mixup operations generate convex interpolations of both inputs and virtual labels. Moreover, we have reformulated the prototypical loss function such that mixup is enabled on metric learning objectives. To demonstrate its generalization given limited training data, we conduct experiments by varying the number of available utterances from each speaker in the VoxCeleb database. Experimental results show that applying contrastive-mixup outperforms the existing baseline, reducing error rate by 16% relatively, especially when the number of training utterances per speaker is limited.
ASR-Aware End-to-end Neural Diarization
Feb 02, 2022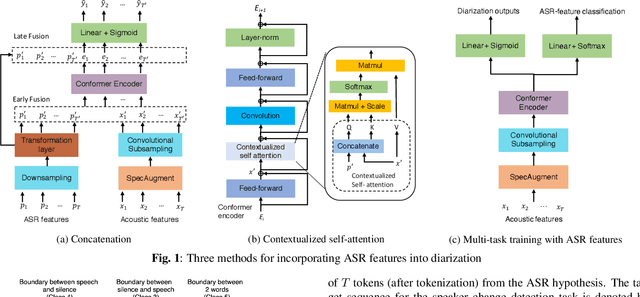
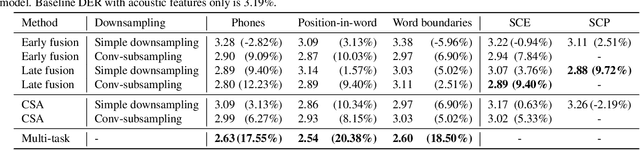
We present a Conformer-based end-to-end neural diarization (EEND) model that uses both acoustic input and features derived from an automatic speech recognition (ASR) model. Two categories of features are explored: features derived directly from ASR output (phones, position-in-word and word boundaries) and features derived from a lexical speaker change detection model, trained by fine-tuning a pretrained BERT model on the ASR output. Three modifications to the Conformer-based EEND architecture are proposed to incorporate the features. First, ASR features are concatenated with acoustic features. Second, we propose a new attention mechanism called contextualized self-attention that utilizes ASR features to build robust speaker representations. Finally, multi-task learning is used to train the model to minimize classification loss for the ASR features along with diarization loss. Experiments on the two-speaker English conversations of Switchboard+SRE data sets show that multi-task learning with position-in-word information is the most effective way of utilizing ASR features, reducing the diarization error rate (DER) by 20% relative to the baseline.
Improving Speaker Identification for Shared Devices by Adapting Embeddings to Speaker Subsets
Sep 06, 2021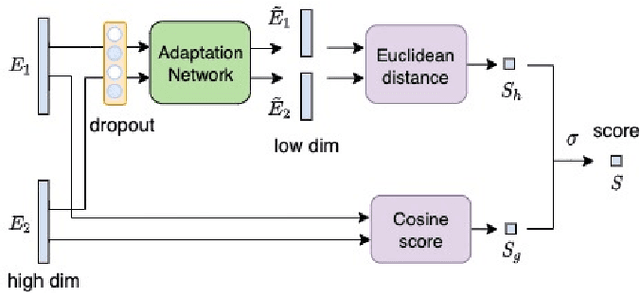
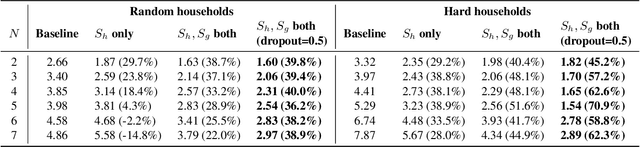
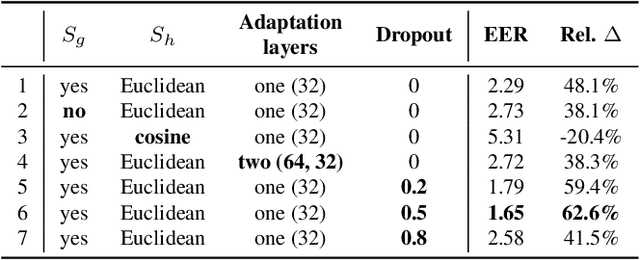
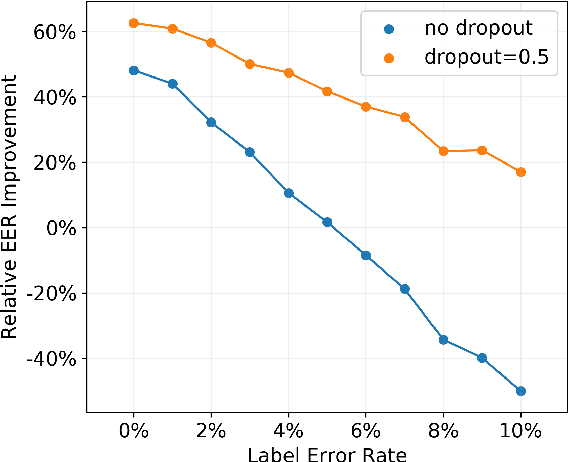
Speaker identification typically involves three stages. First, a front-end speaker embedding model is trained to embed utterance and speaker profiles. Second, a scoring function is applied between a runtime utterance and each speaker profile. Finally, the speaker is identified using nearest neighbor according to the scoring metric. To better distinguish speakers sharing a device within the same household, we propose a household-adapted nonlinear mapping to a low dimensional space to complement the global scoring metric. The combined scoring function is optimized on labeled or pseudo-labeled speaker utterances. With input dropout, the proposed scoring model reduces EER by 45-71% in simulated households with 2 to 7 hard-to-discriminate speakers per household. On real-world internal data, the EER reduction is 49.2%. From t-SNE visualization, we also show that clusters formed by household-adapted speaker embeddings are more compact and uniformly distributed, compared to clusters formed by global embeddings before adaptation.
End-to-end Neural Diarization: From Transformer to Conformer
Jun 14, 2021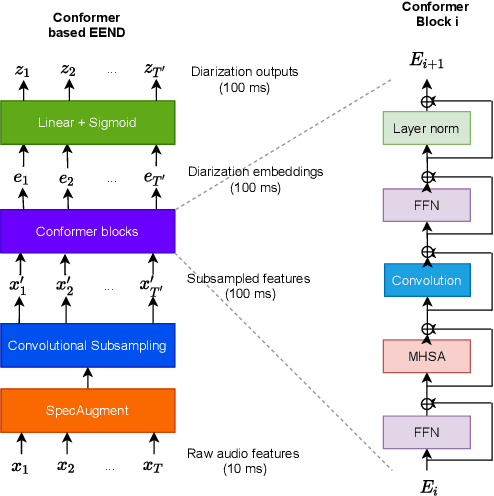
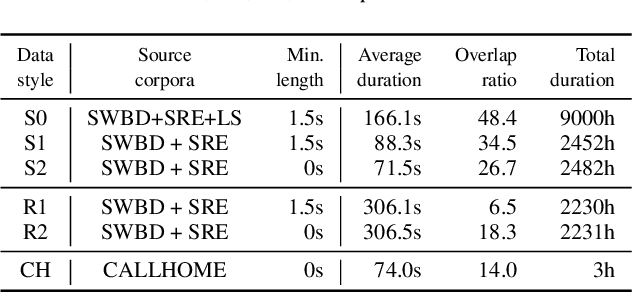

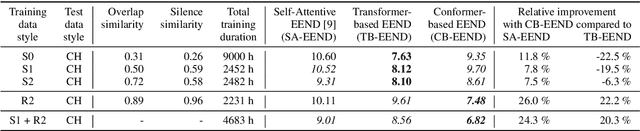
We propose a new end-to-end neural diarization (EEND) system that is based on Conformer, a recently proposed neural architecture that combines convolutional mappings and Transformer to model both local and global dependencies in speech. We first show that data augmentation and convolutional subsampling layers enhance the original self-attentive EEND in the Transformer-based EEND, and then Conformer gives an additional gain over the Transformer-based EEND. However, we notice that the Conformer-based EEND does not generalize as well from simulated to real conversation data as the Transformer-based model. This leads us to quantify the mismatch between simulated data and real speaker behavior in terms of temporal statistics reflecting turn-taking between speakers, and investigate its correlation with diarization error. By mixing simulated and real data in EEND training, we mitigate the mismatch further, with Conformer-based EEND achieving 24% error reduction over the baseline SA-EEND system, and 10% improvement over the best augmented Transformer-based system, on two-speaker CALLHOME data.
BW-EDA-EEND: Streaming End-to-End Neural Speaker Diarization for a Variable Number of Speakers
Nov 05, 2020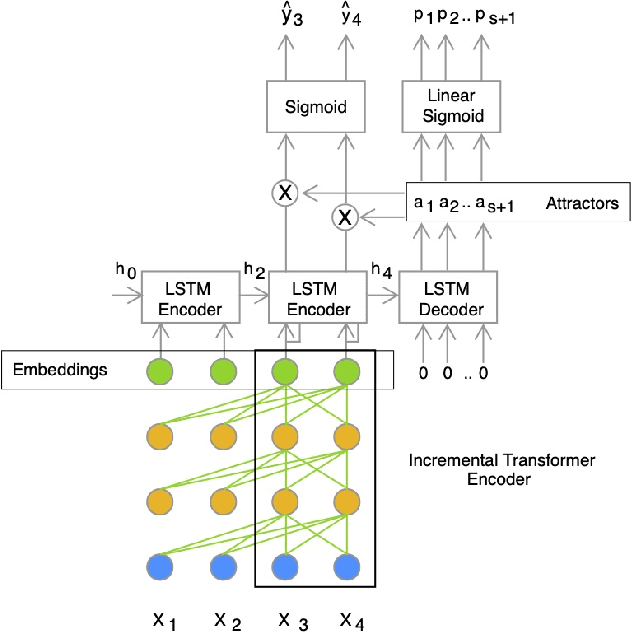
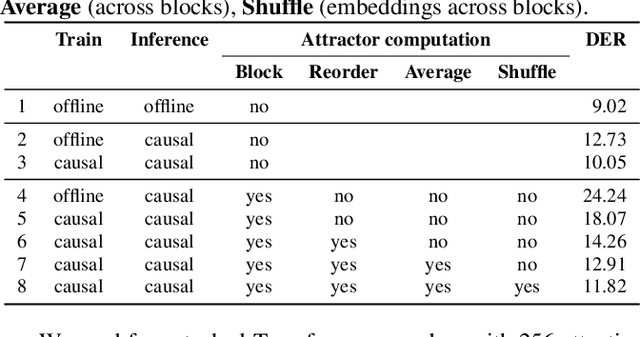
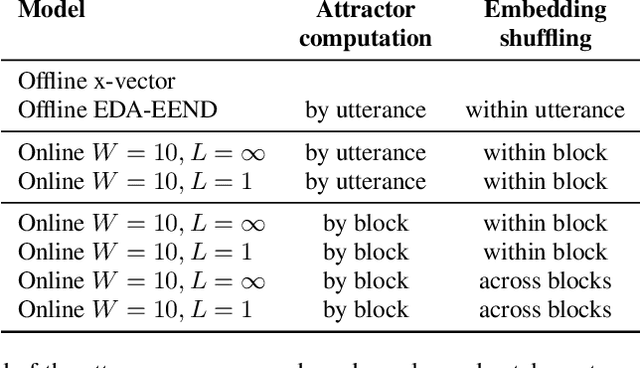
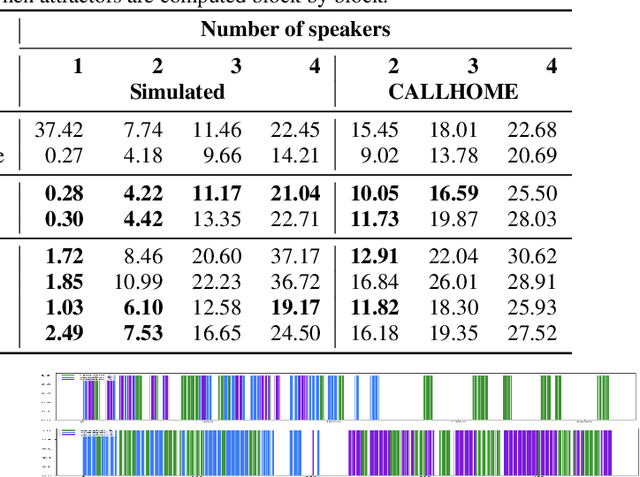
We present a novel online end-to-end neural diarization system, BW-EDA-EEND, that processes data incrementally for a variable number of speakers. The system is based on the EDA architecture of Horiguchi et al., but utilizes the incremental Transformer encoder, attending only to its left contexts and using block-level recurrence in the hidden states to carry information from block to block, making the algorithm complexity linear in time. We propose two variants of it. For unlimited-latency BW-EDA-EEND, which processes inputs in linear time, we show only moderate degradation for up to two speakers using a context size of 10 seconds compared to offline EDA-EEND. With more than two speakers, the accuracy gap between online and offline grows, but it still outperforms a baseline offline clustering diarization system for one to four speakers with unlimited context size, and shows comparable accuracy with context size of 10 seconds. For limited-latency BW-EDA-EEND, which produces diarization outputs block-by-block as audio arrives, we show accuracy comparable to the offline clustering-based system.