 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving fairness in speaker verification via Group-adapted Fusion Network
Feb 23, 2022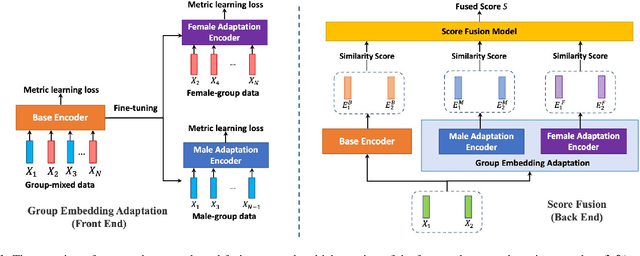
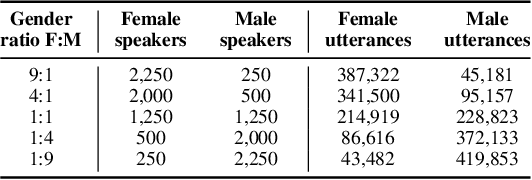

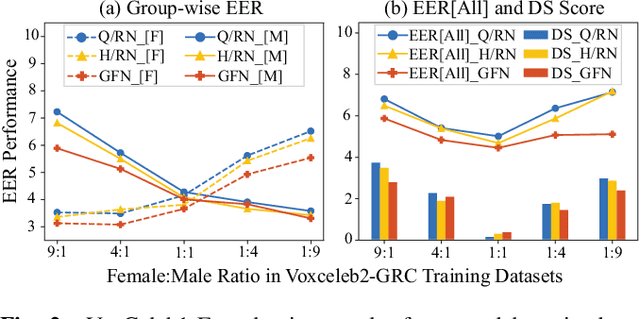
Modern speaker verification models use deep neural networks to encode utterance audio into discriminative embedding vectors. During the training process, these networks are typically optimized to differentiate arbitrary speakers. This learning process biases the learning of fine voice characteristics towards dominant demographic groups, which can lead to an unfair performance disparity across different groups. This is observed especially with underrepresented demographic groups sharing similar voice characteristics. In this work, we investigate the fairness of speaker verification models on controlled datasets with imbalanced gender distributions, providing direct evidence that model performance suffers for underrepresented groups. To mitigate this disparity we propose the group-adapted fusion network (GFN) architecture, a modular architecture based on group embedding adaptation and score fusion. We show that our method alleviates model unfairness by improving speaker verification both overall and for individual groups. Given imbalanced group representation in training, our proposed method achieves overall equal error rate (EER) reduction of 9.6% to 29.0% relative, reduces minority group EER by 13.7% to 18.6%, and results in 20.0% to 25.4% less EER disparity, compared to baselines. The approach is applicable to other types of training data skew in speaker recognition systems.