 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Speech Recognition Error Correction with Large Language Models and Task-Activating Prompting
Oct 10, 2023We explore the ability of large language models (LLMs) to act as speech recognition post-processors that perform rescoring and error correction. Our first focus is on instruction prompting to let LLMs perform these task without fine-tuning, for which we evaluate different prompting schemes, both zero- and few-shot in-context learning, and a novel task activation prompting method that combines causal instructions and demonstration to increase its context windows. Next, we show that rescoring only by in-context learning with frozen LLMs achieves results that are competitive with rescoring by domain-tuned LMs, using a pretrained first-pass recognition system and rescoring output on two out-of-domain tasks (ATIS and WSJ). By combining prompting techniques with fine-tuning we achieve error rates below the N-best oracle level, showcasing the generalization power of the LLMs.
Low-rank Adaptation of Large Language Model Rescoring for Parameter-Efficient Speech Recognition
Sep 26, 2023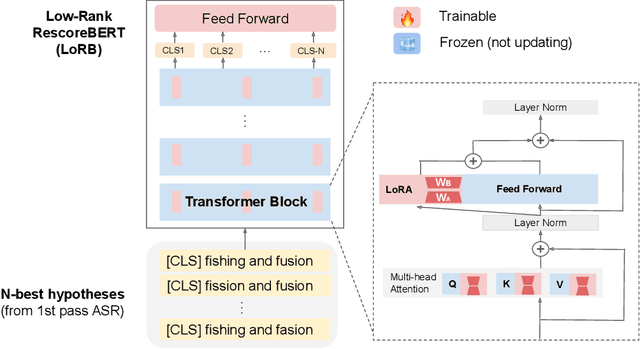
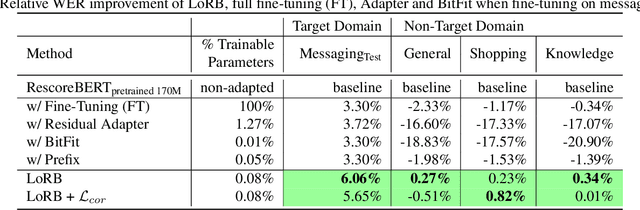
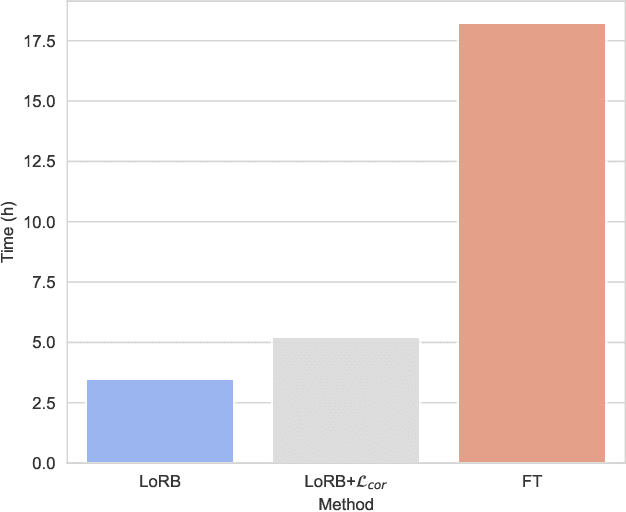
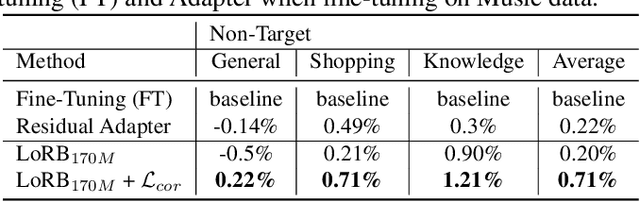
We propose a neural language modeling system based on low-rank adaptation (LoRA) for speech recognition output rescoring. Although pretrained language models (LMs) like BERT have shown superior performance in second-pass rescoring, the high computational cost of scaling up the pretraining stage and adapting the pretrained models to specific domains limit their practical use in rescoring. Here we present a method based on low-rank decomposition to train a rescoring BERT model and adapt it to new domains using only a fraction (0.08%) of the pretrained parameters. These inserted matrices are optimized through a discriminative training objective along with a correlation-based regularization loss. The proposed low-rank adaptation Rescore-BERT (LoRB) architecture is evaluated on LibriSpeech and internal datasets with decreased training times by factors between 5.4 and 3.6.
Adversarial Reweighting for Speaker Verification Fairness
Jul 15, 2022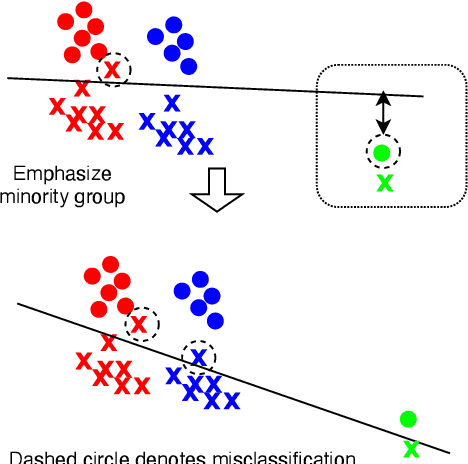
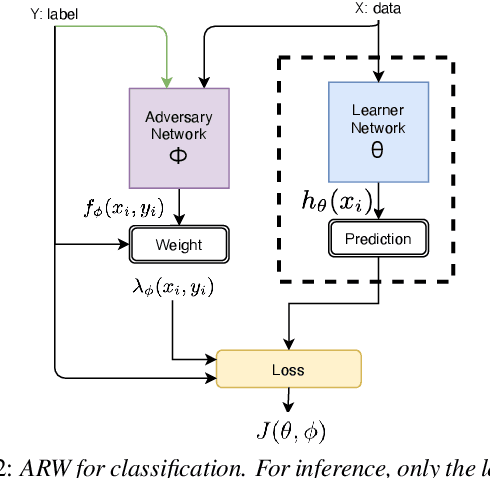
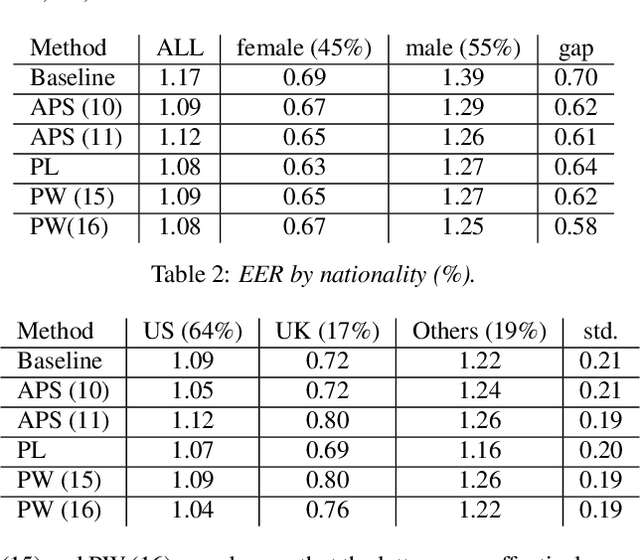
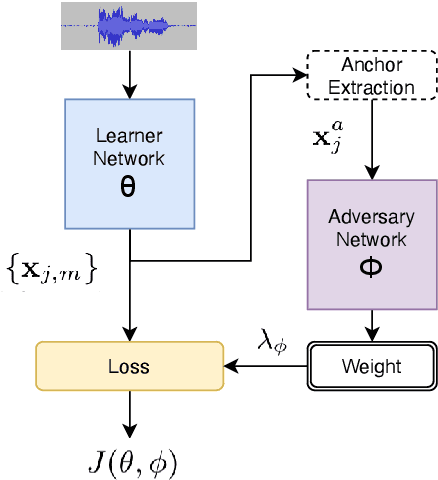
We address performance fairness for speaker verification using the adversarial reweighting (ARW) method. ARW is reformulated for speaker verification with metric learning, and shown to improve results across different subgroups of gender and nationality, without requiring annotation of subgroups in the training data. An adversarial network learns a weight for each training sample in the batch so that the main learner is forced to focus on poorly performing instances. Using a min-max optimization algorithm, this method improves overall speaker verification fairness. We present three different ARWformulations: accumulated pairwise similarity, pseudo-labeling, and pairwise weighting, and measure their performance in terms of equal error rate (EER) on the VoxCeleb corpus. Results show that the pairwise weighting method can achieve 1.08% overall EER, 1.25% for male and 0.67% for female speakers, with relative EER reductions of 7.7%, 10.1% and 3.0%, respectively. For nationality subgroups, the proposed algorithm showed 1.04% EER for US speakers, 0.76% for UK speakers, and 1.22% for all others. The absolute EER gap between gender groups was reduced from 0.70% to 0.58%, while the standard deviation over nationality groups decreased from 0.21 to 0.19.
Treatment Learning Transformer for Noisy Image Classification
Mar 29, 2022
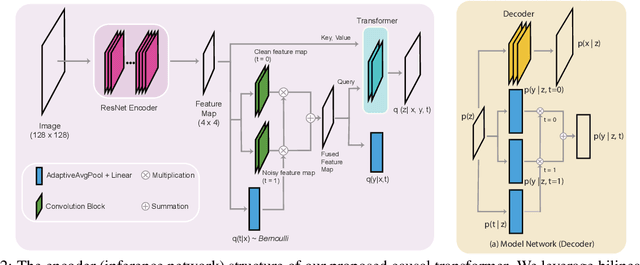


Current top-notch deep learning (DL) based vision models are primarily based on exploring and exploiting the inherent correlations between training data samples and their associated labels. However, a known practical challenge is their degraded performance against "noisy" data, induced by different circumstances such as spurious correlations, irrelevant contexts, domain shift, and adversarial attacks. In this work, we incorporate this binary information of "existence of noise" as treatment into image classification tasks to improve prediction accuracy by jointly estimating their treatment effects. Motivated from causal variational inference, we propose a transformer-based architecture, Treatment Learning Transformer (TLT), that uses a latent generative model to estimate robust feature representations from current observational input for noise image classification. Depending on the estimated noise level (modeled as a binary treatment factor), TLT assigns the corresponding inference network trained by the designed causal loss for prediction. We also create new noisy image datasets incorporating a wide range of noise factors (e.g., object masking, style transfer, and adversarial perturbation) for performance benchmarking. The superior performance of TLT in noisy image classification is further validated by several refutation evaluation metrics. As a by-product, TLT also improves visual salience methods for perceiving noisy images.
Ensemble-based Transfer Learning for Low-resource Machine Translation Quality Estimation
May 17, 2021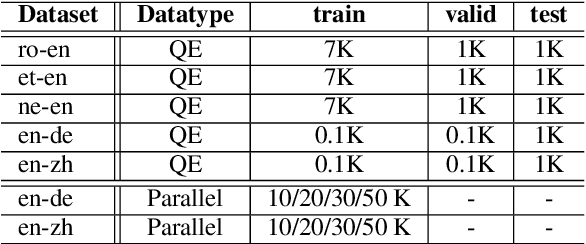

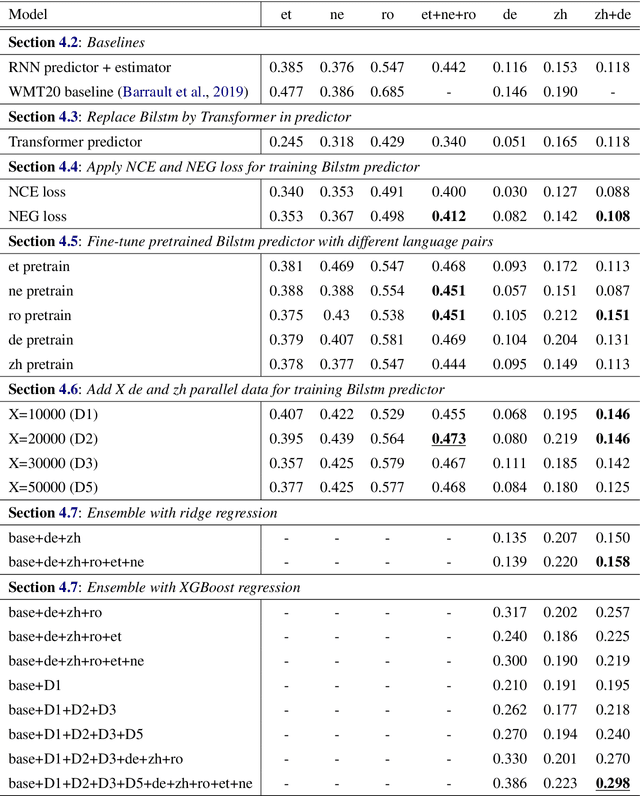
Quality Estimation (QE) of Machine Translation (MT) is a task to estimate the quality scores for given translation outputs from an unknown MT system. However, QE scores for low-resource languages are usually intractable and hard to collect. In this paper, we focus on the Sentence-Level QE Shared Task of the Fifth Conference on Machine Translation (WMT20), but in a more challenging setting. We aim to predict QE scores of given translation outputs when barely none of QE scores of that paired languages are given during training. We propose an ensemble-based predictor-estimator QE model with transfer learning to overcome such QE data scarcity challenge by leveraging QE scores from other miscellaneous languages and translation results of targeted languages. Based on the evaluation results, we provide a detailed analysis of how each of our extension affects QE models on the reliability and the generalization ability to perform transfer learning under multilingual tasks. Finally, we achieve the best performance on the ensemble model combining the models pretrained by individual languages as well as different levels of parallel trained corpus with a Pearson's correlation of 0.298, which is 2.54 times higher than baselines.
DeepOpht: Medical Report Generation for Retinal Images via Deep Models and Visual Explanation
Nov 01, 2020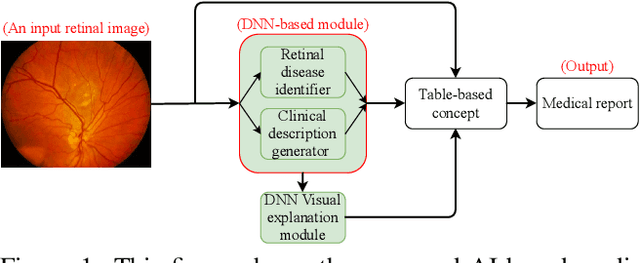
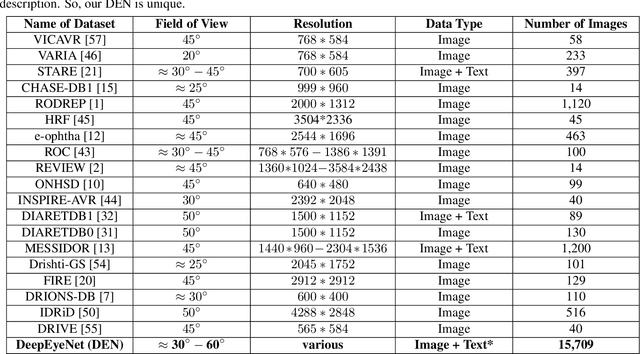
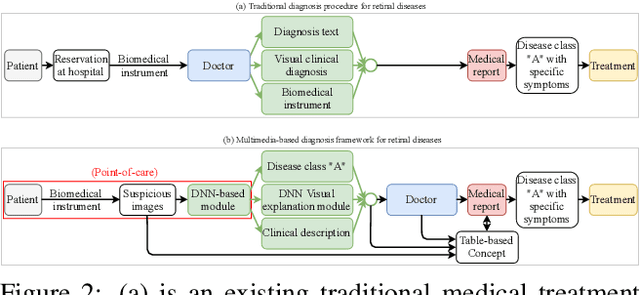
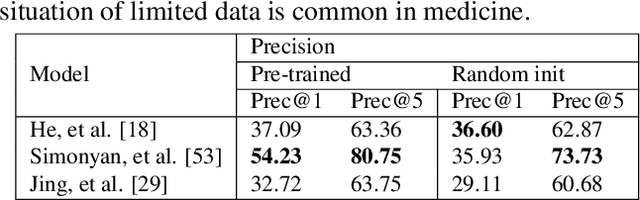
In this work, we propose an AI-based method that intends to improve the conventional retinal disease treatment procedure and help ophthalmologists increase diagnosis efficiency and accuracy. The proposed method is composed of a deep neural networks-based (DNN-based) module, including a retinal disease identifier and clinical description generator, and a DNN visual explanation module. To train and validate the effectiveness of our DNN-based module, we propose a large-scale retinal disease image dataset. Also, as ground truth, we provide a retinal image dataset manually labeled by ophthalmologists to qualitatively show, the proposed AI-based method is effective. With our experimental results, we show that the proposed method is quantitatively and qualitatively effective. Our method is capable of creating meaningful retinal image descriptions and visual explanations that are clinically relevant.
Interpretable Self-Attention Temporal Reasoning for Driving Behavior Understanding
Nov 06, 2019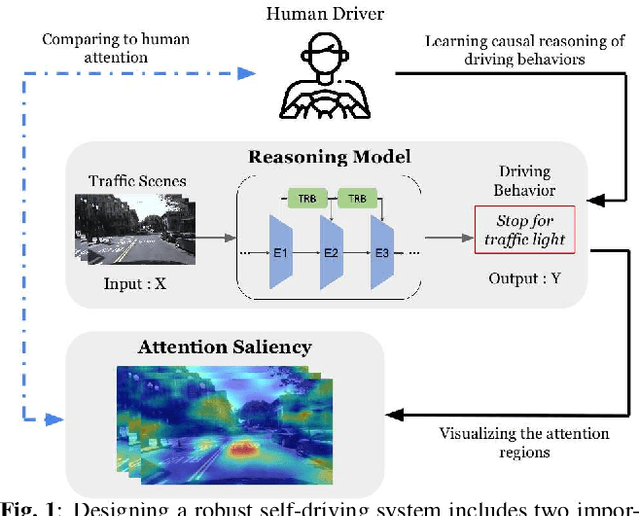
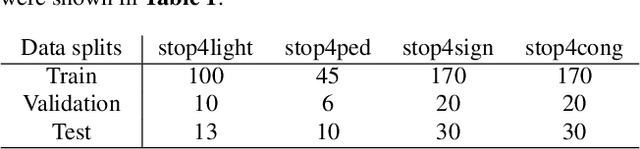
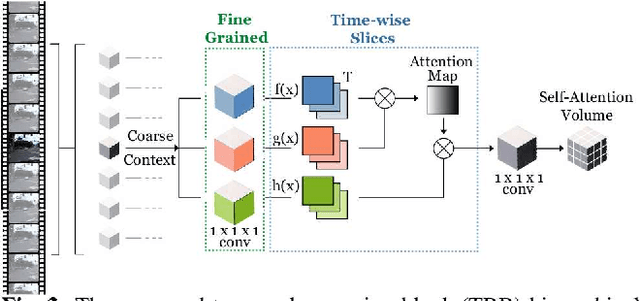
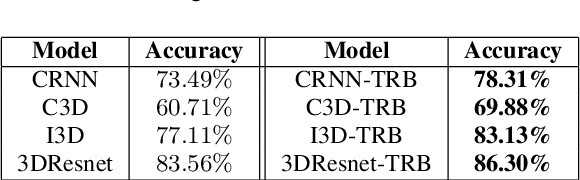
Performing driving behaviors based on causal reasoning is essential to ensure driving safety. In this work, we investigated how state-of-the-art 3D Convolutional Neural Networks (CNNs) perform on classifying driving behaviors based on causal reasoning. We proposed a perturbation-based visual explanation method to inspect the models' performance visually. By examining the video attention saliency, we found that existing models could not precisely capture the causes (e.g., traffic light) of the specific action (e.g., stopping). Therefore, the Temporal Reasoning Block (TRB) was proposed and introduced to the models. With the TRB models, we achieved the accuracy of $\mathbf{86.3\%}$, which outperform the state-of-the-art 3D CNNs from previous works. The attention saliency also demonstrated that TRB helped models focus on the causes more precisely. With both numerical and visual evaluations, we concluded that our proposed TRB models were able to provide accurate driving behavior prediction by learning the causal reasoning of the behaviors.
When Causal Intervention Meets Image Masking and Adversarial Perturbation for Deep Neural Networks
Feb 13, 2019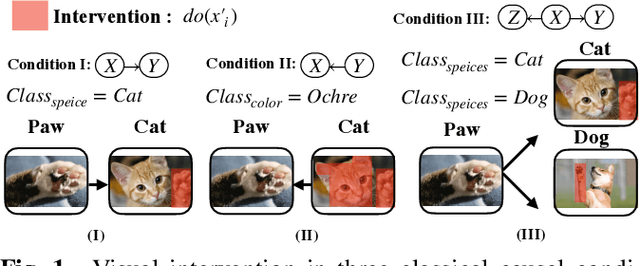
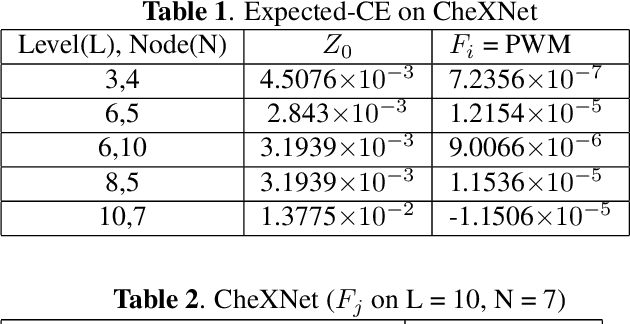
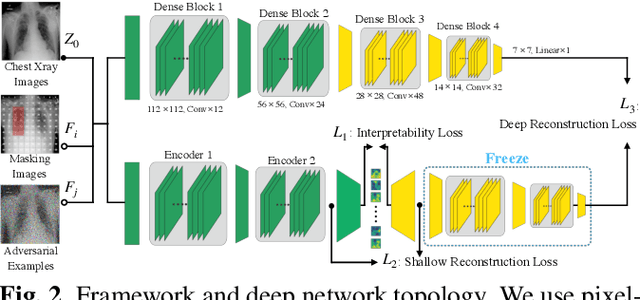

Discovering and exploiting the causality in deep neural networks (DNNs) are crucial challenges for understanding and reasoning causal effects (CE) on an explainable visual model. "Intervention" has been widely used for recognizing a causal relation ontologically. In this paper, we propose a causal inference framework for visual reasoning via do-calculus. To study the intervention effects on pixel-level feature(s) for causal reasoning, we introduce pixel-wise masking and adversarial perturbation. In our framework, CE is calculated using features in a latent space and perturbed prediction from a DNN-based model. We further provide a first look into the characteristics of discovered CE of adversarially perturbed images generated by gradient-based methods. Experimental results show that CE is a competitive and robust index for understanding DNNs when compared with conventional methods such as class-activation mappings (CAMs) on the ChestX-ray 14 dataset for human-interpretable feature(s) (e.g., symptom) reasoning. Moreover, CE holds promises for detecting adversarial examples as it possesses distinct characteristics in the presence of adversarial perturbations.
Synthesizing New Retinal Symptom Images by Multiple Generative Models
Feb 11, 2019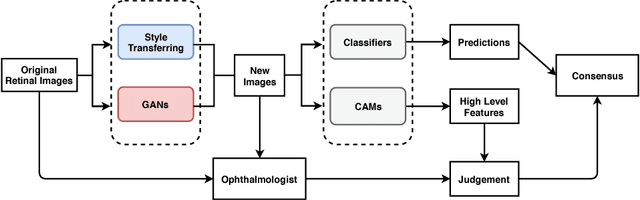
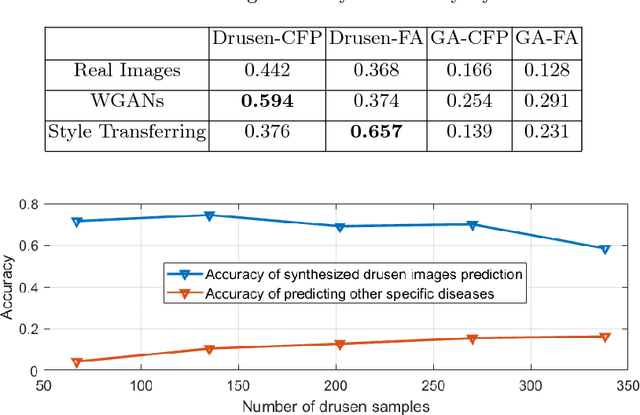
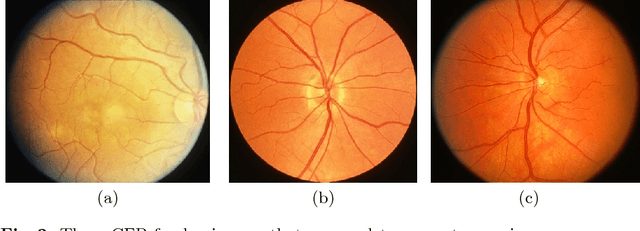
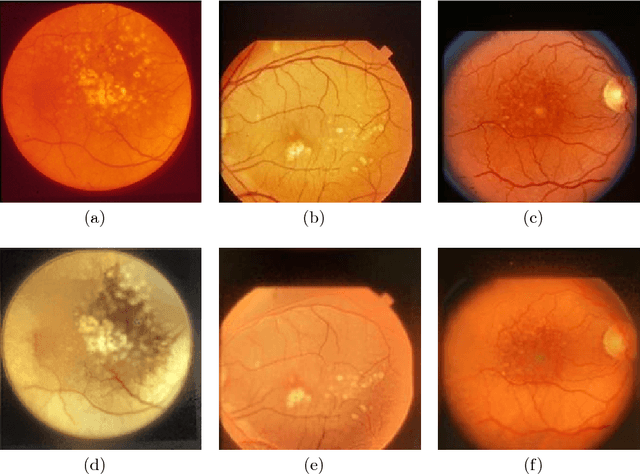
Age-Related Macular Degeneration (AMD) is an asymptomatic retinal disease which may result in loss of vision. There is limited access to high-quality relevant retinal images and poor understanding of the features defining sub-classes of this disease. Motivated by recent advances in machine learning we specifically explore the potential of generative modeling, using Generative Adversarial Networks (GANs) and style transferring, to facilitate clinical diagnosis and disease understanding by feature extraction. We design an analytic pipeline which first generates synthetic retinal images from clinical images; a subsequent verification step is applied. In the synthesizing step we merge GANs (DCGANs and WGANs architectures) and style transferring for the image generation, whereas the verified step controls the accuracy of the generated images. We find that the generated images contain sufficient pathological details to facilitate ophthalmologists' task of disease classification and in discovery of disease relevant features. In particular, our system predicts the drusen and geographic atrophy sub-classes of AMD. Furthermore, the performance using CFP images for GANs outperforms the classification based on using only the original clinical dataset. Our results are evaluated using existing classifier of retinal diseases and class activated maps, supporting the predictive power of the synthetic images and their utility for feature extraction. Our code examples are available online.
Auto-Classification of Retinal Diseases in the Limit of Sparse Data Using a Two-Streams Machine Learning Model
Nov 01, 2018

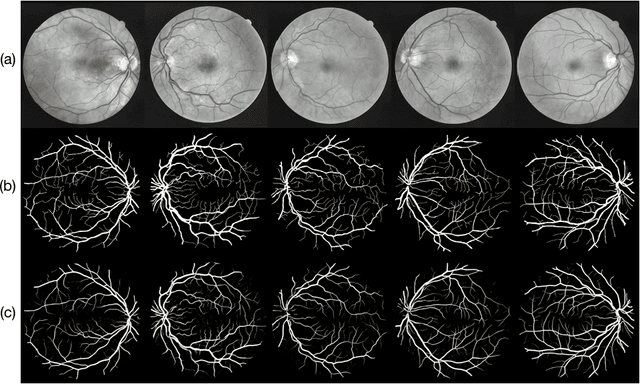
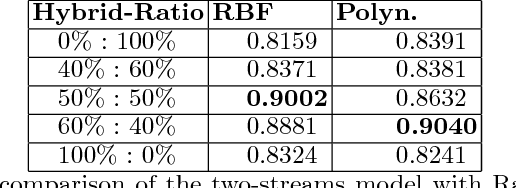
Automatic clinical diagnosis of retinal diseases has emerged as a promising approach to facilitate discovery in areas with limited access to specialists. Based on the fact that fundus structure and vascular disorders are the main characteristics of retinal diseases, we propose a novel visual-assisted diagnosis hybrid model mixing the support vector machine (SVM) and deep neural networks (DNNs). Furthermore, we present a new clinical retina dataset, called EyeNet2, for ophthalmology incorporating 52 retina diseases classes. Using EyeNet2, our model achieves 90.43\% diagnosis accuracy, and the model performance is comparable to the professional ophthalmologists.
* A extension work of a workshop paper arXiv admin note: substantial text overlap with arXiv:1806.06423