 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Orthogonal Chirp Division Multiplexing Over Doubly Selective Channels
Aug 10, 2025In this letter, we extend orthogonal chirp division multiplexing (OCDM) to vector OCDM (VOCDM) to provide more design freedom to deal with doubly selective channels. The VOCDM modulation is implemented by performing M parallel N-size inverse discrete Fresnel transforms (IDFnT). Based on the complex exponential basis expansion model (CE-BEM) for doubly selective channels, we derive the VOCDM input-output relationship, and show performance tradeoffs of VOCDM with respect to (w.r.t.) its modulation parameters M and N. Specifically, we investigate the diversity and peak-to-average power ratio (PAPR) of VOCDM w.r.t. M and N. Under doubly selective channels, VOCDM exhibits superior diversity performance as long as the parameters M and N are configured to satisfy some constraints from the delay and the Doppler spreads of the channel, respectively. Furthermore, the PAPR of VOCDM signals decreases with a decreasing N. These theoretical findings are verified through numerical simulations.
Carrier Frequency Offset Estimation for OCDM with Null Subchirps
Nov 03, 2023In this paper, we investigate the carrier frequency offset (CFO) identifiability problem in orthogonal chirp division multiplexing (OCDM) systems. We propose a transmission scheme by inserting consecutive null subchirps. A CFO estimator is accordingly developed to achieve a full acquisition range. We further demonstrate that the proposed transmission scheme not only help to resolve CFO identifiability issues but also enable multipath diversity for OCDM systems. Simulation results corroborate our theoretical findings.
Precheck Sequence Based False Base Station Detection During Handover: A Physical Layer Based Security Scheme
Jul 03, 2023False Base Station (FBS) attack has been a severe security problem for the cellular network since 2G era. During handover, the user equipment (UE) periodically receives state information from surrounding base stations (BSs) and uploads it to the source BS. The source BS compares the uploaded signal power and shifts UE to another BS that can provide the strongest signal. An FBS can transmit signal with the proper power and attract UE to connect to it. In this paper, based on the 3GPP standard, a Precheck Sequence-based Detection (PSD) Scheme is proposed to secure the transition of legal base station (LBS) for UE. This scheme first analyzes the structure of received signals in blocks and symbols. Several additional symbols are added to the current signal sequence for verification. By designing a long table of symbol sequence, every UE which needs handover will be allocated a specific sequence from this table. The simulation results show that the performance of this PSD Scheme is better than that of any existing ones, even when a specific transmit power is designed for FBS.
Rethinking the Image Feature Biases Exhibited by Deep CNN Models
Nov 03, 2021



In recent years, convolutional neural networks (CNNs) have been applied successfully in many fields. However, such deep neural models are still regarded as black box in most tasks. One of the fundamental issues underlying this problem is understanding which features are most influential in image recognition tasks and how they are processed by CNNs. It is widely accepted that CNN models combine low-level features to form complex shapes until the object can be readily classified, however, several recent studies have argued that texture features are more important than other features. In this paper, we assume that the importance of certain features varies depending on specific tasks, i.e., specific tasks exhibit a feature bias. We designed two classification tasks based on human intuition to train deep neural models to identify anticipated biases. We devised experiments comprising many tasks to test these biases for the ResNet and DenseNet models. From the results, we conclude that (1) the combined effect of certain features is typically far more influential than any single feature; (2) in different tasks, neural models can perform different biases, that is, we can design a specific task to make a neural model biased toward a specific anticipated feature.
Decentralizing Feature Extraction with Quantum Convolutional Neural Network for Automatic Speech Recognition
Oct 26, 2020

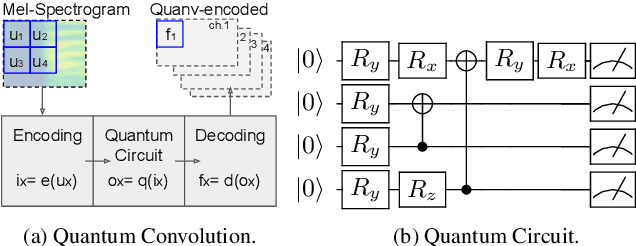

We propose a novel decentralized feature extraction approach in federated learning to address privacy-preservation issues for speech recognition. It is built upon a quantum convolutional neural network (QCNN) composed of a quantum circuit encoder for feature extraction, and a recurrent neural network (RNN) based end-to-end acoustic model (AM). To enhance model parameter protection in a decentralized architecture, an input speech is first up-streamed to a quantum computing server to extract Mel-spectrogram, and the corresponding convolutional features are encoded using a quantum circuit algorithm with random parameters. The encoded features are then down-streamed to the local RNN model for the final recognition. The proposed decentralized framework takes advantage of the quantum learning progress to secure models and to avoid privacy leakage attacks. Testing on the Google Speech Commands Dataset, the proposed QCNN encoder attains a competitive accuracy of 95.12\% in a decentralized model, which is better than the previous architectures using centralized RNN models with convolutional features. We also conduct an in-depth study of different quantum circuit encoder architectures to provide insights into designing QCNN-based feature extractors. Finally, neural saliency analyses demonstrate a high correlation between the proposed QCNN features, class activation maps, and the input Mel-spectrogram.
On Mean Absolute Error for Deep Neural Network Based Vector-to-Vector Regression
Aug 12, 2020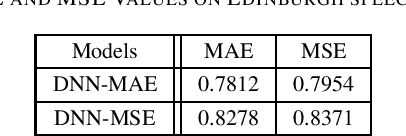
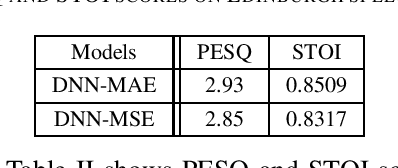
In this paper, we exploit the properties of mean absolute error (MAE) as a loss function for the deep neural network (DNN) based vector-to-vector regression. The goal of this work is two-fold: (i) presenting performance bounds of MAE, and (ii) demonstrating new properties of MAE that make it more appropriate than mean squared error (MSE) as a loss function for DNN based vector-to-vector regression. First, we show that a generalized upper-bound for DNN-based vector- to-vector regression can be ensured by leveraging the known Lipschitz continuity property of MAE. Next, we derive a new generalized upper bound in the presence of additive noise. Finally, in contrast to conventional MSE commonly adopted to approximate Gaussian errors for regression, we show that MAE can be interpreted as an error modeled by Laplacian distribution. Speech enhancement experiments are conducted to corroborate our proposed theorems and validate the performance advantages of MAE over MSE for DNN based regression.
Analyzing Upper Bounds on Mean Absolute Errors for Deep Neural Network Based Vector-to-Vector Regression
Aug 04, 2020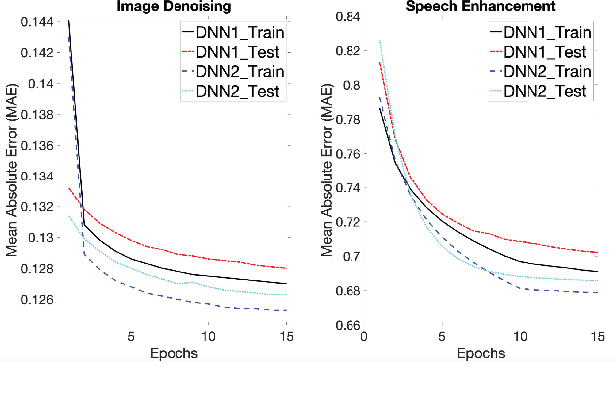

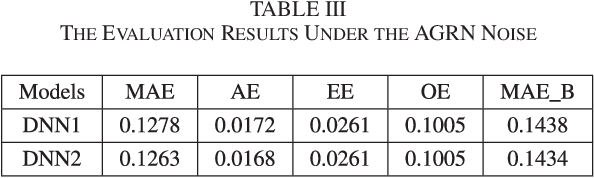

In this paper, we show that, in vector-to-vector regression utilizing deep neural networks (DNNs), a generalized loss of mean absolute error (MAE) between the predicted and expected feature vectors is upper bounded by the sum of an approximation error, an estimation error, and an optimization error. Leveraging upon error decomposition techniques in statistical learning theory and non-convex optimization theory, we derive upper bounds for each of the three aforementioned errors and impose necessary constraints on DNN models. Moreover, we assess our theoretical results through a set of image de-noising and speech enhancement experiments. Our proposed upper bounds of MAE for DNN based vector-to-vector regression are corroborated by the experimental results and the upper bounds are valid with and without the "over-parametrization" technique.
Characterizing Speech Adversarial Examples Using Self-Attention U-Net Enhancement
Mar 31, 2020
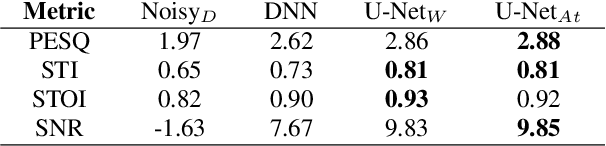
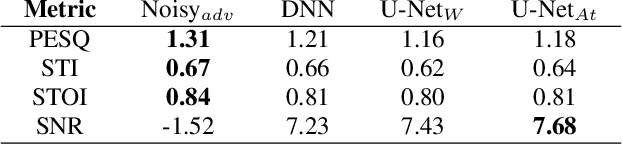
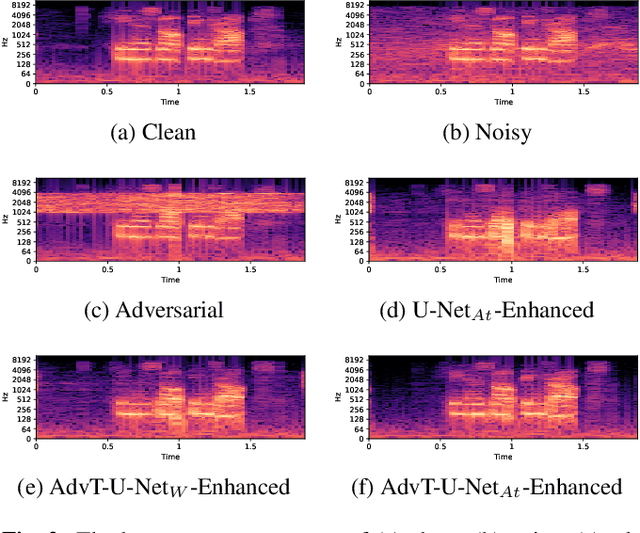
Recent studies have highlighted adversarial examples as ubiquitous threats to the deep neural network (DNN) based speech recognition systems. In this work, we present a U-Net based attention model, U-Net$_{At}$, to enhance adversarial speech signals. Specifically, we evaluate the model performance by interpretable speech recognition metrics and discuss the model performance by the augmented adversarial training. Our experiments show that our proposed U-Net$_{At}$ improves the perceptual evaluation of speech quality (PESQ) from 1.13 to 2.78, speech transmission index (STI) from 0.65 to 0.75, short-term objective intelligibility (STOI) from 0.83 to 0.96 on the task of speech enhancement with adversarial speech examples. We conduct experiments on the automatic speech recognition (ASR) task with adversarial audio attacks. We find that (i) temporal features learned by the attention network are capable of enhancing the robustness of DNN based ASR models; (ii) the generalization power of DNN based ASR model could be enhanced by applying adversarial training with an additive adversarial data augmentation. The ASR metric on word-error-rates (WERs) shows that there is an absolute 2.22 $\%$ decrease under gradient-based perturbation, and an absolute 2.03 $\%$ decrease, under evolutionary-optimized perturbation, which suggests that our enhancement models with adversarial training can further secure a resilient ASR system.
Enhanced Adversarial Strategically-Timed Attacks against Deep Reinforcement Learning
Feb 20, 2020

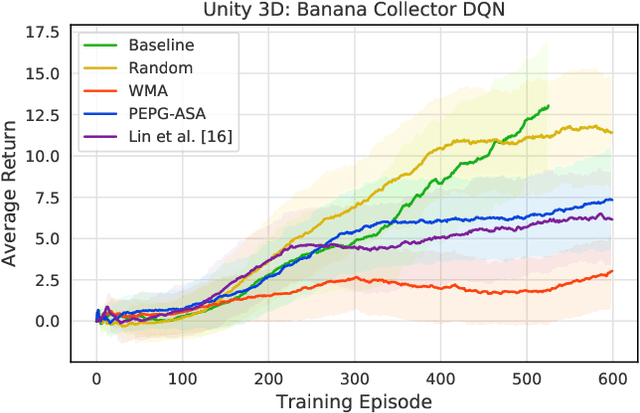
Recent deep neural networks based techniques, especially those equipped with the ability of self-adaptation in the system level such as deep reinforcement learning (DRL), are shown to possess many advantages of optimizing robot learning systems (e.g., autonomous navigation and continuous robot arm control.) However, the learning-based systems and the associated models may be threatened by the risks of intentionally adaptive (e.g., noisy sensor confusion) and adversarial perturbations from real-world scenarios. In this paper, we introduce timing-based adversarial strategies against a DRL-based navigation system by jamming in physical noise patterns on the selected time frames. To study the vulnerability of learning-based navigation systems, we propose two adversarial agent models: one refers to online learning; another one is based on evolutionary learning. Besides, three open-source robot learning and navigation control environments are employed to study the vulnerability under adversarial timing attacks. Our experimental results show that the adversarial timing attacks can lead to a significant performance drop, and also suggest the necessity of enhancing the robustness of robot learning systems.
Variational Quantum Circuits for Deep Reinforcement Learning
Aug 17, 2019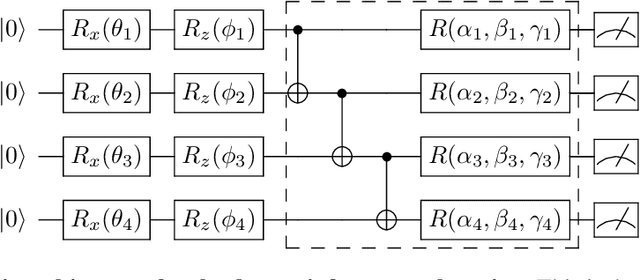


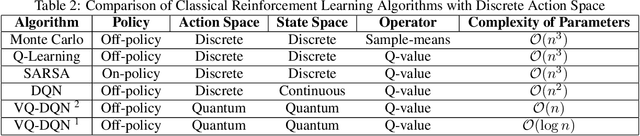
The state-of-the-art Machine learning approaches are based on classical Von-Neumann computing architectures and have been widely used in many industrial and academic domains. With the recent development of quantum computing, a couple of tech-giants have attempted new quantum circuits for machine learning tasks. However, the existing quantum machine learning is hard to simulate classical deep learning models because of the intractability of deep quantum circuits. Thus, it is necessary to design approximated quantum algorithms for quantum machine learning. This work explores variational quantum circuits for deep reinforcement learning. Specifically, we reshape classical deep reinforcement learning algorithms like experience replay and target network into a representation of variational quantum circuits. On the other hand, we use a quantum information encoding scheme to reduce the number of model parameters as small as the scale of $poly(\log{} N)$ in contrast to $poly(N)$ in a standard configuration. Besides, our variational quantum circuits can be deployed in many near-term noisy intermediate quantum machines.