 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSquare Superpixel Generation and Representation Learning via Granular Ball Computing
Mar 31, 2026Superpixels provide a compact region-based representation that preserves object boundaries and local structures, and have therefore been widely used in a variety of vision tasks to reduce computational cost. However, most existing superpixel algorithms produce irregularly shaped regions, which are not well aligned with regular operators such as convolutions. Consequently, superpixels are often treated as an offline preprocessing step, limiting parallel implementation and hindering end-to-end optimization within deep learning pipelines. Motivated by the adaptive representation and coverage property of granular-ball computing, we develop a square superpixel generation approach. Specifically, we approximate superpixels using multi-scale square blocks to avoid the computational and implementation difficulties induced by irregular shapes, enabling efficient parallel processing and learnable feature extraction. For each block, a purity score is computed based on pixel-intensity similarity, and high-quality blocks are selected accordingly. The resulting square superpixels can be readily integrated as graph nodes in graph neural networks (GNNs) or as tokens in Vision Transformers (ViTs), facilitating multi-scale information aggregation and structured visual representation. Experimental results on downstream tasks demonstrate consistent performance improvements, validating the effectiveness of the proposed method.
Granular-ball Guided Masking: Structure-aware Data Augmentation
Dec 24, 2025Deep learning models have achieved remarkable success in computer vision, but they still rely heavily on large-scale labeled data and tend to overfit when data are limited or distributions shift. Data augmentation, particularly mask-based information dropping, can enhance robustness by forcing models to explore complementary cues; however, existing approaches often lack structural awareness and may discard essential semantics. We propose Granular-ball Guided Masking (GBGM), a structure-aware augmentation strategy guided by Granular-ball Computing (GBC). GBGM adaptively preserves semantically rich, structurally important regions while suppressing redundant areas through a coarse-to-fine hierarchical masking process, producing augmentations that are both representative and discriminative. Extensive experiments on multiple benchmarks demonstrate consistent improvements in classification accuracy and masked image reconstruction, confirming the effectiveness and broad applicability of the proposed method. Simple and model-agnostic, it integrates seamlessly into CNNs and Vision Transformers and provides a new paradigm for structure-aware data augmentation.
Face-MakeUp: Multimodal Facial Prompts for Text-to-Image Generation
Jan 05, 2025Facial images have extensive practical applications. Although the current large-scale text-image diffusion models exhibit strong generation capabilities, it is challenging to generate the desired facial images using only text prompt. Image prompts are a logical choice. However, current methods of this type generally focus on general domain. In this paper, we aim to optimize image makeup techniques to generate the desired facial images. Specifically, (1) we built a dataset of 4 million high-quality face image-text pairs (FaceCaptionHQ-4M) based on LAION-Face to train our Face-MakeUp model; (2) to maintain consistency with the reference facial image, we extract/learn multi-scale content features and pose features for the facial image, integrating these into the diffusion model to enhance the preservation of facial identity features for diffusion models. Validation on two face-related test datasets demonstrates that our Face-MakeUp can achieve the best comprehensive performance.All codes are available at:https://github.com/ddw2AIGROUP2CQUPT/Face-MakeUp
HumanVLM: Foundation for Human-Scene Vision-Language Model
Nov 05, 2024Human-scene vision-language tasks are increasingly prevalent in diverse social applications, yet recent advancements predominantly rely on models specifically tailored to individual tasks. Emerging research indicates that large vision-language models (VLMs) can enhance performance across various downstream vision-language understanding tasks. However, general-domain models often underperform in specialized fields. This study introduces a domain-specific Large Vision-Language Model, Human-Scene Vision-Language Model (HumanVLM), designed to provide a foundation for human-scene Vision-Language tasks. Specifically, (1) we create a large-scale human-scene multimodal image-text dataset (HumanCaption-10M) sourced from the Internet to facilitate domain-specific alignment; (2) develop a captioning approach for human-centered images, capturing human faces, bodies, and backgrounds, and construct a high-quality Human-Scene image-text dataset (HumanCaptionHQ, about 311k pairs) that contain as much detailed information as possible about human; (3) Using HumanCaption-10M and HumanCaptionHQ, we train a HumanVLM. In the experiments, we then evaluate our HumanVLM across varous downstream tasks, where it demonstrates superior overall performance among multimodal models of comparable scale, particularly excelling in human-related tasks and significantly outperforming similar models, including Qwen2VL and ChatGPT-4o. HumanVLM, alongside the data introduced, will stimulate the research in human-around fields.
Granular-ball Representation Learning for Deep CNN on Learning with Label Noise
Sep 05, 2024



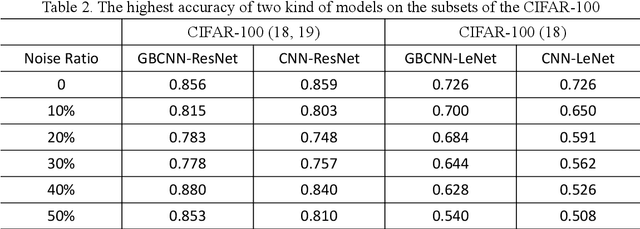
In actual scenarios, whether manually or automatically annotated, label noise is inevitably generated in the training data, which can affect the effectiveness of deep CNN models. The popular solutions require data cleaning or designing additional optimizations to punish the data with mislabeled data, thereby enhancing the robustness of models. However, these methods come at the cost of weakening or even losing some data during the training process. As we know, content is the inherent attribute of an image that does not change with changes in annotations. In this study, we propose a general granular-ball computing (GBC) module that can be embedded into a CNN model, where the classifier finally predicts the label of granular-ball ($gb$) samples instead of each individual samples. Specifically, considering the classification task: (1) in forward process, we split the input samples as $gb$ samples at feature-level, each of which can correspond to multiple samples with varying numbers and share one single label; (2) during the backpropagation process, we modify the gradient allocation strategy of the GBC module to enable it to propagate normally; and (3) we develop an experience replay policy to ensure the stability of the training process. Experiments demonstrate that the proposed method can improve the robustness of CNN models with no additional data or optimization.
PA-LLaVA: A Large Language-Vision Assistant for Human Pathology Image Understanding
Aug 18, 2024The previous advancements in pathology image understanding primarily involved developing models tailored to specific tasks. Recent studies has demonstrated that the large vision-language model can enhance the performance of various downstream tasks in medical image understanding. In this study, we developed a domain-specific large language-vision assistant (PA-LLaVA) for pathology image understanding. Specifically, (1) we first construct a human pathology image-text dataset by cleaning the public medical image-text data for domain-specific alignment; (2) Using the proposed image-text data, we first train a pathology language-image pretraining (PLIP) model as the specialized visual encoder for pathology image, and then we developed scale-invariant connector to avoid the information loss caused by image scaling; (3) We adopt two-stage learning to train PA-LLaVA, first stage for domain alignment, and second stage for end to end visual question \& answering (VQA) task. In experiments, we evaluate our PA-LLaVA on both supervised and zero-shot VQA datasets, our model achieved the best overall performance among multimodal models of similar scale. The ablation experiments also confirmed the effectiveness of our design. We posit that our PA-LLaVA model and the datasets presented in this work can promote research in field of computational pathology. All codes are available at: https://github.com/ddw2AIGROUP2CQUPT/PA-LLaVA}{https://github.com/ddw2AIGROUP2CQUPT/PA-LLaVA
15M Multimodal Facial Image-Text Dataset
Jul 11, 2024Currently, image-text-driven multi-modal deep learning models have demonstrated their outstanding potential in many fields. In practice, tasks centered around facial images have broad application prospects. This paper presents \textbf{FaceCaption-15M}, a large-scale, diverse, and high-quality dataset of facial images accompanied by their natural language descriptions (facial image-to-text). This dataset aims to facilitate a study on face-centered tasks. FaceCaption-15M comprises over 15 million pairs of facial images and their corresponding natural language descriptions of facial features, making it the largest facial image-caption dataset to date. We conducted a comprehensive analysis of image quality, text naturalness, text complexity, and text-image relevance to demonstrate the superiority of FaceCaption-15M. To validate the effectiveness of FaceCaption-15M, we first trained a facial language-image pre-training model (FLIP, similar to CLIP) to align facial image with its corresponding captions in feature space. Subsequently, using both image and text encoders and fine-tuning only the linear layer, our FLIP-based models achieved state-of-the-art results on two challenging face-centered tasks. The purpose is to promote research in the field of face-related tasks through the availability of the proposed FaceCaption-15M dataset. All data, codes, and models are publicly available. https://huggingface.co/datasets/OpenFace-CQUPT/FaceCaption-15M
Multi-Granularity Representation Learning for Sketch-based Dynamic Face Image Retrieval
Dec 31, 2023In specific scenarios, face sketch can be used to identify a person. However, drawing a face sketch often requires exceptional skill and is time-consuming, limiting its widespread applications in actual scenarios. The new framework of sketch less face image retrieval (SLFIR)[1] attempts to overcome the barriers by providing a means for humans and machines to interact during the drawing process. Considering SLFIR problem, there is a large gap between a partial sketch with few strokes and any whole face photo, resulting in poor performance at the early stages. In this study, we propose a multigranularity (MG) representation learning (MGRL) method to address the SLFIR problem, in which we learn the representation of different granularity regions for a partial sketch, and then, by combining all MG regions of the sketches and images, the final distance was determined. In the experiments, our method outperformed state-of-the-art baselines in terms of early retrieval on two accessible datasets. Codes are available at https://github.com/ddw2AIGROUP2CQUPT/MGRL.
Sketch Less Face Image Retrieval: A New Challenge
Feb 11, 2023



In some specific scenarios, face sketch was used to identify a person. However, drawing a complete face sketch often needs skills and takes time, which hinder its widespread applicability in the practice. In this study, we proposed a new task named sketch less face image retrieval (SLFIR), in which the retrieval was carried out at each stroke and aim to retrieve the target face photo using a partial sketch with as few strokes as possible (see Fig.1). Firstly, we developed a method to generate the data of sketch with drawing process, and opened such dataset; Secondly, we proposed a two-stage method as the baseline for SLFIR that (1) A triplet network, was first adopt to learn the joint embedding space shared between the complete sketch and its target face photo; (2) Regarding the sketch drawing episode as a sequence, we designed a LSTM module to optimize the representation of the incomplete face sketch. Experiments indicate that the new framework can finish the retrieval using a partial or pool drawing sketch.
A Study of Deep CNN Model with Labeling Noise Based on Granular-ball Computing
Jul 17, 2022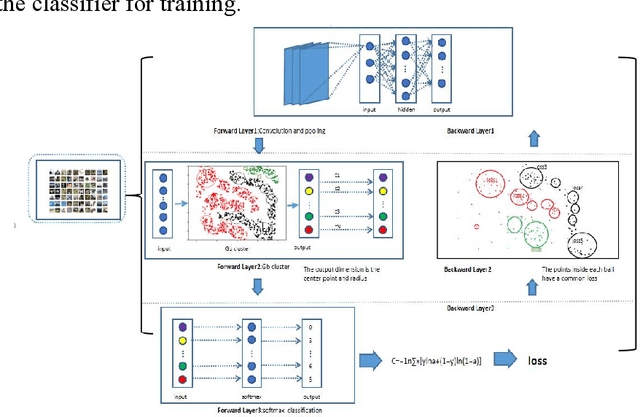

In supervised learning, the presence of noise can have a significant impact on decision making. Since many classifiers do not take label noise into account in the derivation of the loss function, including the loss functions of logistic regression, SVM, and AdaBoost, especially the AdaBoost iterative algorithm, whose core idea is to continuously increase the weight value of the misclassified samples, the weight of samples in many presence of label noise will be increased, leading to a decrease in model accuracy. In addition, the learning process of BP neural network and decision tree will also be affected by label noise. Therefore, solving the label noise problem is an important element of maintaining the robustness of the network model, which is of great practical significance. Granular ball computing is an important modeling method developed in the field of granular computing in recent years, which is an efficient, robust and scalable learning method. In this paper, we pioneered a granular ball neural network algorithm model, which adopts the idea of multi-granular to filter label noise samples during model training, solving the current problem of model instability caused by label noise in the field of deep learning, greatly reducing the proportion of label noise in training samples and improving the robustness of neural network models.