 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Stage Deep Edge Detection Based on Dense-Scale Feature Fusion and Pixel-Level Imbalance Learning
Paper and Code
Mar 17, 2022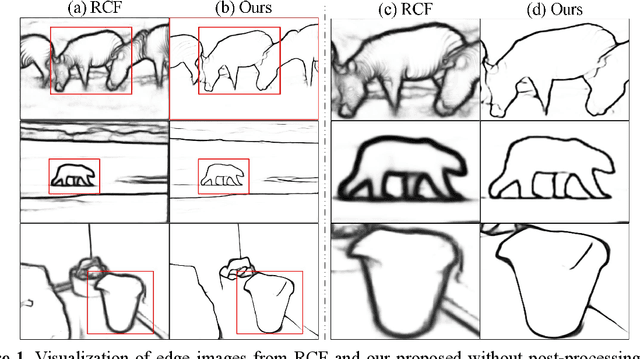
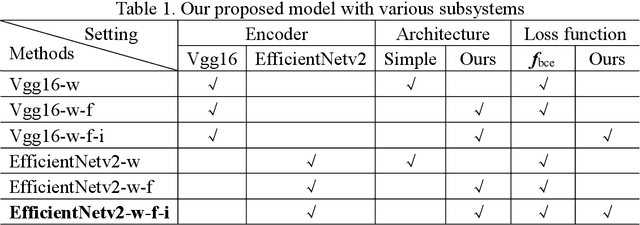
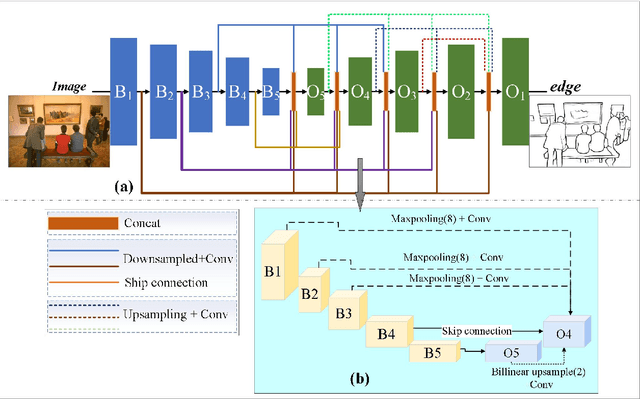
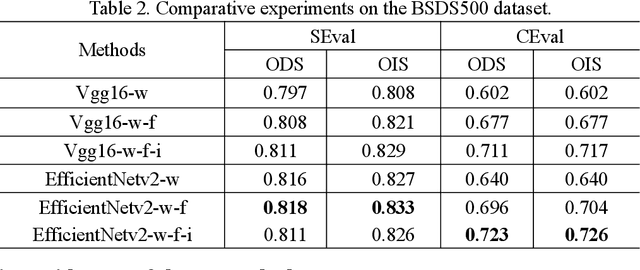
Edge detection, a basic task in the field of computer vision, is an important preprocessing operation for the recognition and understanding of a visual scene. In conventional models, the edge image generated is ambiguous, and the edge lines are also very thick, which typically necessitates the use of non-maximum suppression (NMS) and morphological thinning operations to generate clear and thin edge images. In this paper, we aim to propose a one-stage neural network model that can generate high-quality edge images without postprocessing. The proposed model adopts a classic encoder-decoder framework in which a pre-trained neural model is used as the encoder and a multi-feature-fusion mechanism that merges the features of each level with each other functions as a learnable decoder. Further, we propose a new loss function that addresses the pixel-level imbalance in the edge image by suppressing the false positive (FP) edge information near the true positive (TP) edge and the false negative (FN) non-edge. The results of experiments conducted on several benchmark datasets indicate that the proposed method achieves state-of-the-art results without using NMS and morphological thinning operations.