 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Granularity Representation Learning for Sketch-based Dynamic Face Image Retrieval
Dec 31, 2023In specific scenarios, face sketch can be used to identify a person. However, drawing a face sketch often requires exceptional skill and is time-consuming, limiting its widespread applications in actual scenarios. The new framework of sketch less face image retrieval (SLFIR)[1] attempts to overcome the barriers by providing a means for humans and machines to interact during the drawing process. Considering SLFIR problem, there is a large gap between a partial sketch with few strokes and any whole face photo, resulting in poor performance at the early stages. In this study, we propose a multigranularity (MG) representation learning (MGRL) method to address the SLFIR problem, in which we learn the representation of different granularity regions for a partial sketch, and then, by combining all MG regions of the sketches and images, the final distance was determined. In the experiments, our method outperformed state-of-the-art baselines in terms of early retrieval on two accessible datasets. Codes are available at https://github.com/ddw2AIGROUP2CQUPT/MGRL.
Sketch Less Face Image Retrieval: A New Challenge
Feb 11, 2023



In some specific scenarios, face sketch was used to identify a person. However, drawing a complete face sketch often needs skills and takes time, which hinder its widespread applicability in the practice. In this study, we proposed a new task named sketch less face image retrieval (SLFIR), in which the retrieval was carried out at each stroke and aim to retrieve the target face photo using a partial sketch with as few strokes as possible (see Fig.1). Firstly, we developed a method to generate the data of sketch with drawing process, and opened such dataset; Secondly, we proposed a two-stage method as the baseline for SLFIR that (1) A triplet network, was first adopt to learn the joint embedding space shared between the complete sketch and its target face photo; (2) Regarding the sketch drawing episode as a sequence, we designed a LSTM module to optimize the representation of the incomplete face sketch. Experiments indicate that the new framework can finish the retrieval using a partial or pool drawing sketch.
Multimodal Affective Analysis Using Hierarchical Attention Strategy with Word-Level Alignment
May 22, 2018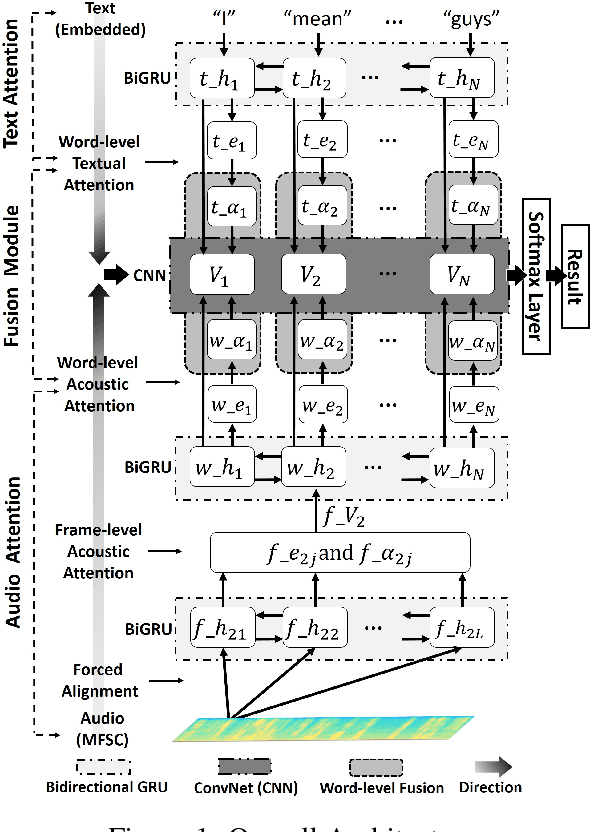
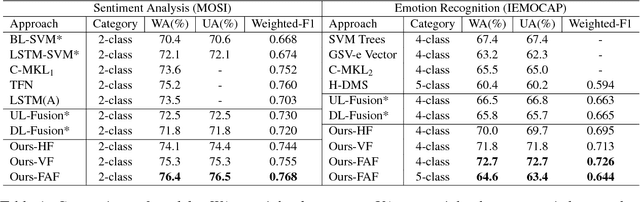
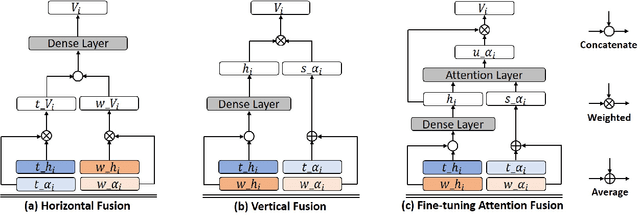
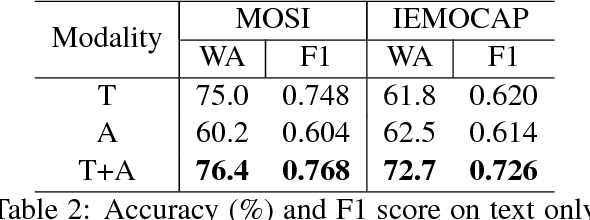
Multimodal affective computing, learning to recognize and interpret human affects and subjective information from multiple data sources, is still challenging because: (i) it is hard to extract informative features to represent human affects from heterogeneous inputs; (ii) current fusion strategies only fuse different modalities at abstract level, ignoring time-dependent interactions between modalities. Addressing such issues, we introduce a hierarchical multimodal architecture with attention and word-level fusion to classify utter-ance-level sentiment and emotion from text and audio data. Our introduced model outperforms the state-of-the-art approaches on published datasets and we demonstrated that our model is able to visualize and interpret the synchronized attention over modalities.