 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonGEMM Bench: Understanding the Performance Horizon of the Latest ML Workloads with NonGEMM Workloads
Apr 17, 2024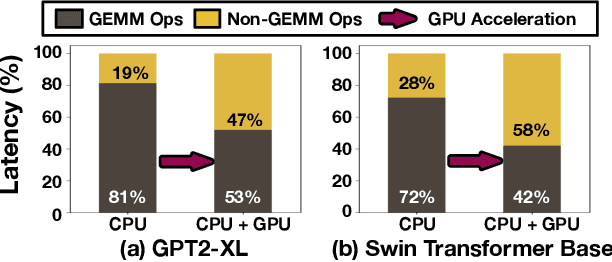
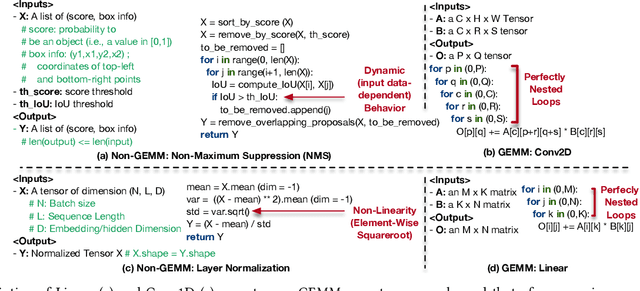
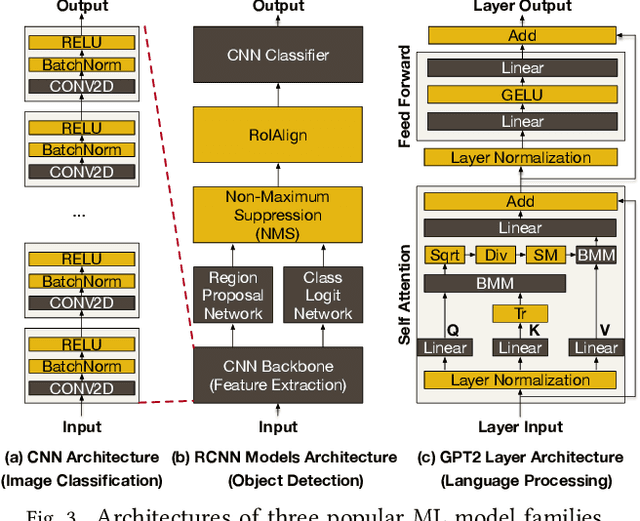
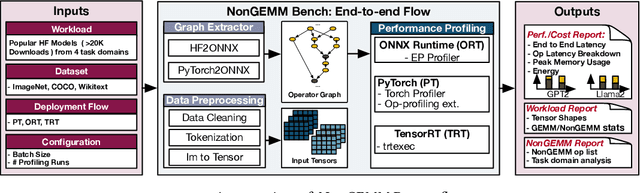
Machine Learning (ML) operators are the building blocks to design ML models with various target applications. GEneral Matrix Multiplication (GEMM) operators are the backbone of ML models. They are notorious for being computationally expensive requiring billions of multiply-and-accumulate. Therefore, significant effort has been put to study and optimize the GEMM operators in order to speed up the execution of ML models. GPUs and accelerators are widely deployed to accelerate ML workloads by optimizing the execution of GEMM operators. Nonetheless, the performance of NonGEMM operators have not been studied as thoroughly as GEMMs. Therefore, this paper describes \bench, a benchmark to study NonGEMM operators. We first construct \bench using popular ML workloads from different domains, then perform case studies on various grade GPU platforms to analyze the behavior of NonGEMM operators in GPU accelerated systems. Finally, we present some key takeaways to bridge the gap between GEMM and NonGEMM operators and to offer the community with potential new optimization directions.
Progressive Gradient Flow for Robust N:M Sparsity Training in Transformers
Feb 07, 2024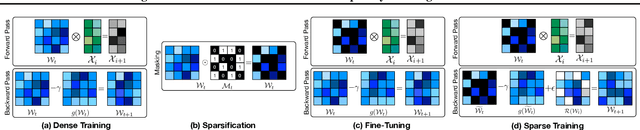


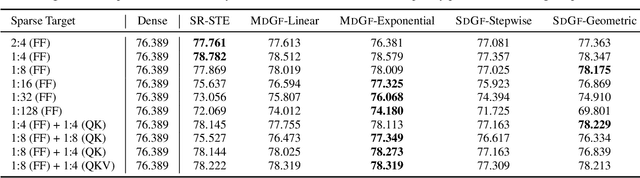
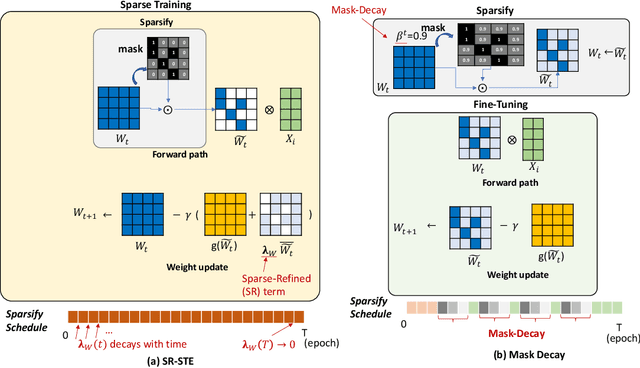
N:M Structured sparsity has garnered significant interest as a result of relatively modest overhead and improved efficiency. Additionally, this form of sparsity holds considerable appeal for reducing the memory footprint owing to their modest representation overhead. There have been efforts to develop training recipes for N:M structured sparsity, they primarily focus on low-sparsity regions ($\sim$50\%). Nonetheless, performance of models trained using these approaches tends to decline when confronted with high-sparsity regions ($>$80\%). In this work, we study the effectiveness of existing sparse training recipes at \textit{high-sparsity regions} and argue that these methods fail to sustain the model quality on par with low-sparsity regions. We demonstrate that the significant factor contributing to this disparity is the presence of elevated levels of induced noise in the gradient magnitudes. To mitigate this undesirable effect, we employ decay mechanisms to progressively restrict the flow of gradients towards pruned elements. Our approach improves the model quality by up to 2$\%$ and 5$\%$ in vision and language models at high sparsity regime, respectively. We also evaluate the trade-off between model accuracy and training compute cost in terms of FLOPs. At iso-training FLOPs, our method yields better performance compared to conventional sparse training recipes, exhibiting an accuracy improvement of up to 2$\%$. The source code is available at https://github.com/abhibambhaniya/progressive_gradient_flow_nm_sparsity.
JaxPruner: A concise library for sparsity research
May 02, 2023


This paper introduces JaxPruner, an open-source JAX-based pruning and sparse training library for machine learning research. JaxPruner aims to accelerate research on sparse neural networks by providing concise implementations of popular pruning and sparse training algorithms with minimal memory and latency overhead. Algorithms implemented in JaxPruner use a common API and work seamlessly with the popular optimization library Optax, which, in turn, enables easy integration with existing JAX based libraries. We demonstrate this ease of integration by providing examples in four different codebases: Scenic, t5x, Dopamine and FedJAX and provide baseline experiments on popular benchmarks.
Demystifying Map Space Exploration for NPUs
Oct 07, 2022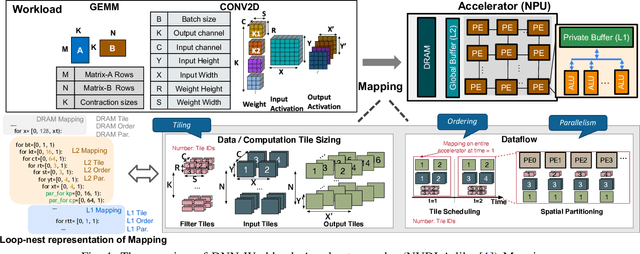
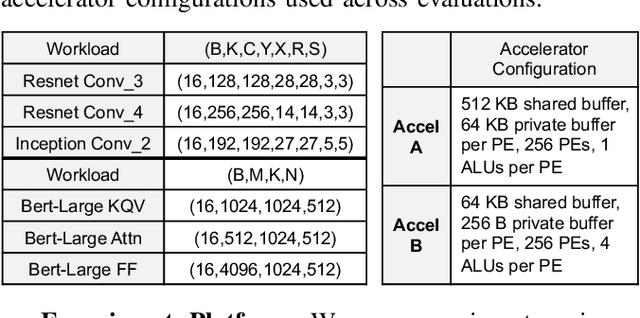
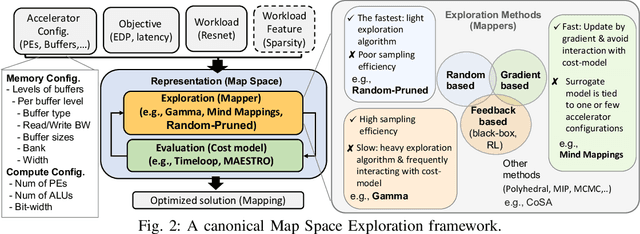
Map Space Exploration is the problem of finding optimized mappings of a Deep Neural Network (DNN) model on an accelerator. It is known to be extremely computationally expensive, and there has been active research looking at both heuristics and learning-based methods to make the problem computationally tractable. However, while there are dozens of mappers out there (all empirically claiming to find better mappings than others), the research community lacks systematic insights on how different search techniques navigate the map-space and how different mapping axes contribute to the accelerator's performance and efficiency. Such insights are crucial to developing mapping frameworks for emerging DNNs that are increasingly irregular (due to neural architecture search) and sparse, making the corresponding map spaces much more complex. In this work, rather than proposing yet another mapper, we do a first-of-its-kind apples-to-apples comparison of search techniques leveraged by different mappers. Next, we extract the learnings from our study and propose two new techniques that can augment existing mappers -- warm-start and sparsity-aware -- that demonstrate speedups, scalability, and robustness across diverse DNN models.
Training Recipe for N:M Structured Sparsity with Decaying Pruning Mask
Sep 15, 2022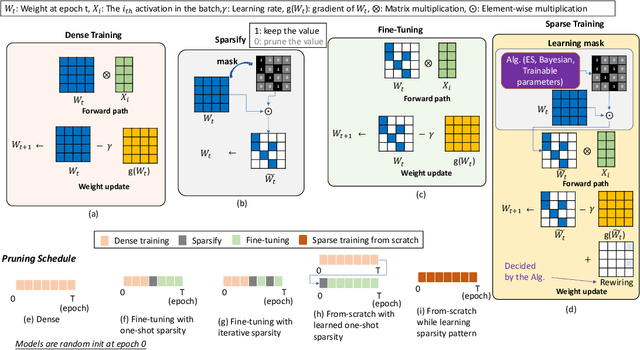


Sparsity has become one of the promising methods to compress and accelerate Deep Neural Networks (DNNs). Among different categories of sparsity, structured sparsity has gained more attention due to its efficient execution on modern accelerators. Particularly, N:M sparsity is attractive because there are already hardware accelerator architectures that can leverage certain forms of N:M structured sparsity to yield higher compute-efficiency. In this work, we focus on N:M sparsity and extensively study and evaluate various training recipes for N:M sparsity in terms of the trade-off between model accuracy and compute cost (FLOPs). Building upon this study, we propose two new decay-based pruning methods, namely "pruning mask decay" and "sparse structure decay". Our evaluations indicate that these proposed methods consistently deliver state-of-the-art (SOTA) model accuracy, comparable to unstructured sparsity, on a Transformer-based model for a translation task. The increase in the accuracy of the sparse model using the new training recipes comes at the cost of marginal increase in the total training compute (FLOPs).
DiGamma: Domain-aware Genetic Algorithm for HW-Mapping Co-optimization for DNN Accelerators
Jan 26, 2022

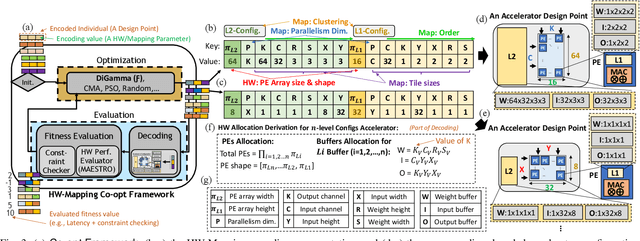

The design of DNN accelerators includes two key parts: HW resource configuration and mapping strategy. Intensive research has been conducted to optimize each of them independently. Unfortunately, optimizing for both together is extremely challenging due to the extremely large cross-coupled search space. To address this, in this paper, we propose a HW-Mapping co-optimization framework, an efficient encoding of the immense design space constructed by HW and Mapping, and a domain-aware genetic algorithm, named DiGamma, with specialized operators for improving search efficiency. We evaluate DiGamma with seven popular DNNs models with different properties. Our evaluations show DiGamma can achieve (geomean) 3.0x and 10.0x speedup, comparing to the best-performing baseline optimization algorithms, in edge and cloud settings.
DNNFuser: Generative Pre-Trained Transformer as a Generalized Mapper for Layer Fusion in DNN Accelerators
Jan 26, 2022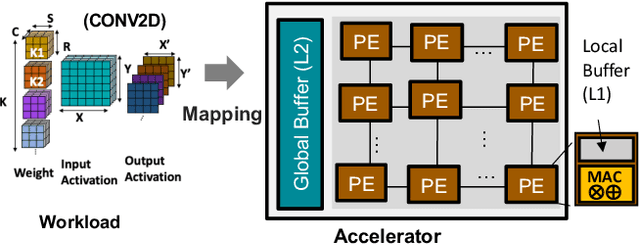



Dataflow/mapping decides the compute and energy efficiency of DNN accelerators. Many mappers have been proposed to tackle the intra-layer map-space. However, mappers for inter-layer map-space (aka layer-fusion map-space), have been rarely discussed. In this work, we propose a mapper, DNNFuser, specifically focusing on this layer-fusion map-space. While existing SOTA DNN mapping explorations rely on search-based mappers, this is the first work, to the best of our knowledge, to propose a one-shot inference-based mapper. We leverage a famous language model GPT as our DNN architecture to learn layer-fusion optimization as a sequence modeling problem. Further, the trained DNNFuser can generalize its knowledge and infer new solutions for unseen conditions. Within one inference pass, DNNFuser can infer solutions with compatible performance to the ones found by a highly optimized search-based mapper while being 66x-127x faster.
ATTACC the Quadratic Bottleneck of Attention Layers
Jul 13, 2021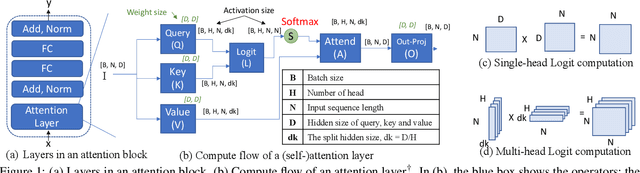
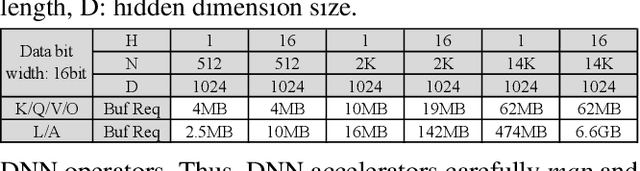
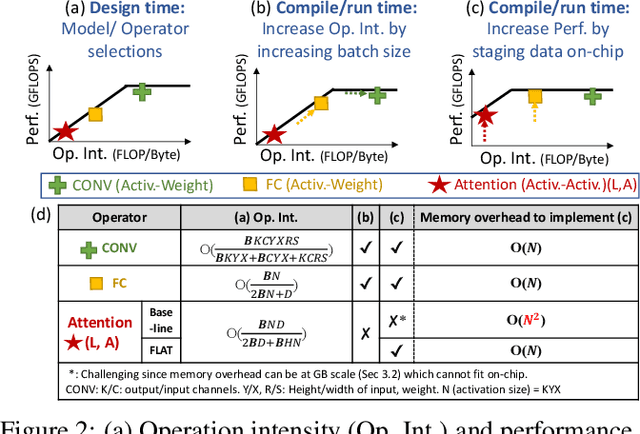
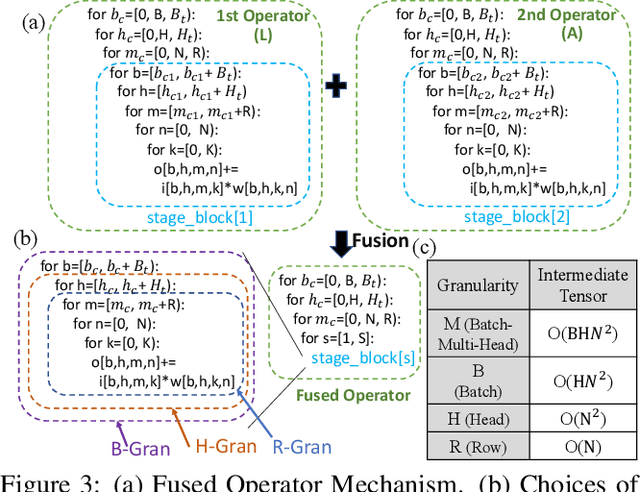
Attention mechanisms form the backbone of state-of-the-art machine learning models for a variety of tasks. Deploying them on deep neural network (DNN) accelerators, however, is prohibitively challenging especially under long sequences. Operators in attention layers exhibit limited reuse and quadratic growth in memory footprint, leading to severe memory-boundedness. This paper introduces a new attention-tailored dataflow, termed FLAT, which leverages operator fusion, loop-nest optimizations, and interleaved execution. It increases the effective memory bandwidth by efficiently utilizing the high-bandwidth, low-capacity on-chip buffer and thus achieves better run time and compute resource utilization. We term FLAT-compatible accelerators ATTACC. In our evaluation, ATTACC achieves 1.94x and 1.76x speedup and 49% and 42% of energy reduction comparing to state-of-the-art edge and cloud accelerators.
Domain-specific Genetic Algorithm for Multi-tenant DNNAccelerator Scheduling
Apr 30, 2021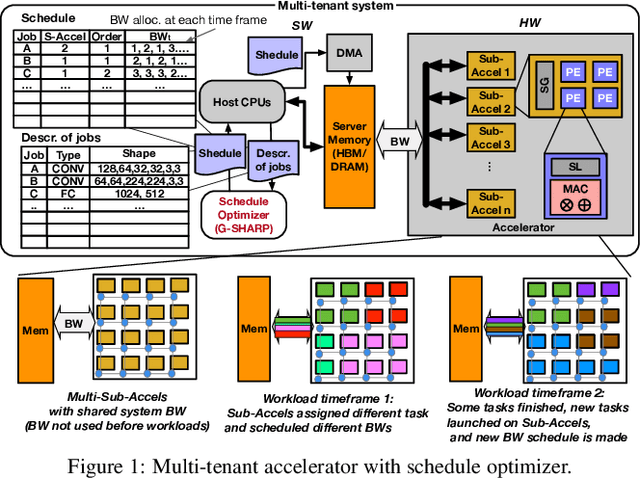
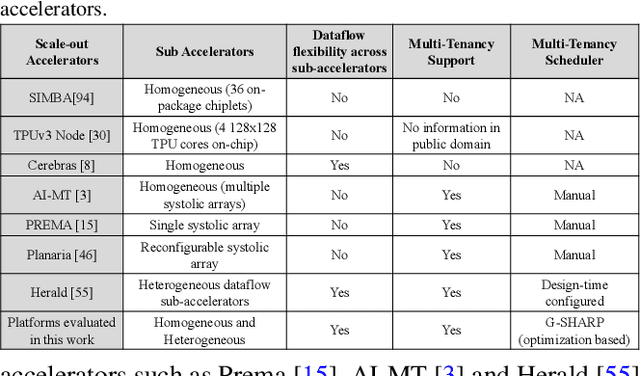
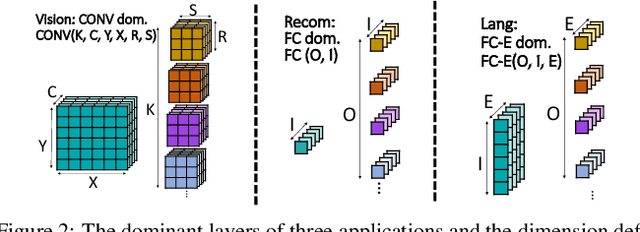

As Deep Learning continues to drive a variety of applications in datacenters and HPC, there is a growing trend towards building large accelerators with several sub-accelerator cores/chiplets. This work looks at the problem of supporting multi-tenancy on such accelerators. In particular, we focus on the problem of mapping layers from several DNNs simultaneously on an accelerator. Given the extremely large search space, we formulate the search as an optimization problem and develop a specialized genetic algorithm called G# withcustom operators to enable structured sample-efficient exploration. We quantitatively compare G# with several common heuristics, state-of-the-art optimization methods, and reinforcement learning methods across different accelerator set-tings (large/small accelerators) and different sub-accelerator configurations (homogeneous/heterogeneous), and observeG# can consistently find better solutions. Further, to enable real-time scheduling, we also demonstrate a method to generalize the learnt schedules and transfer them to the next batch of jobs, reducing schedule compute time to near zero.
ConfuciuX: Autonomous Hardware Resource Assignment for DNN Accelerators using Reinforcement Learning
Sep 04, 2020
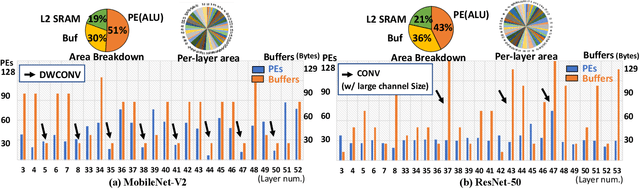


DNN accelerators provide efficiency by leveraging reuse of activations/weights/outputs during the DNN computations to reduce data movement from DRAM to the chip. The reuse is captured by the accelerator's dataflow. While there has been significant prior work in exploring and comparing various dataflows, the strategy for assigning on-chip hardware resources (i.e., compute and memory) given a dataflow that can optimize for performance/energy while meeting platform constraints of area/power for DNN(s) of interest is still relatively unexplored. The design-space of choices for balancing compute and memory explodes combinatorially, as we show in this work (e.g., as large as O(10^(72)) choices for running \mobilenet), making it infeasible to do manual-tuning via exhaustive searches. It is also difficult to come up with a specific heuristic given that different DNNs and layer types exhibit different amounts of reuse. In this paper, we propose an autonomous strategy called ConfuciuX to find optimized HW resource assignments for a given model and dataflow style. ConfuciuX leverages a reinforcement learning method, REINFORCE, to guide the search process, leveraging a detailed HW performance cost model within the training loop to estimate rewards. We also augment the RL approach with a genetic algorithm for further fine-tuning. ConfuciuX demonstrates the highest sample-efficiency for training compared to other techniques such as Bayesian optimization, genetic algorithm, simulated annealing, and other RL methods. It converges to the optimized hardware configuration 4.7 to 24 times faster than alternate techniques.