 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-specific Genetic Algorithm for Multi-tenant DNNAccelerator Scheduling
Paper and Code
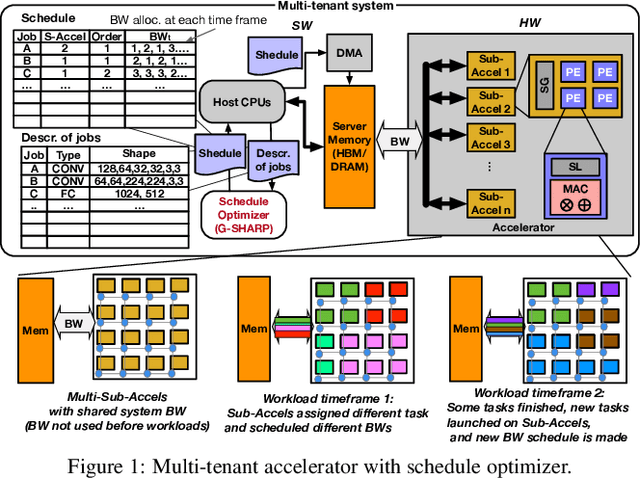
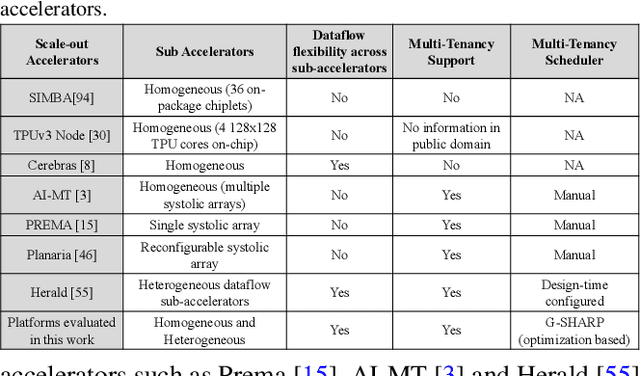
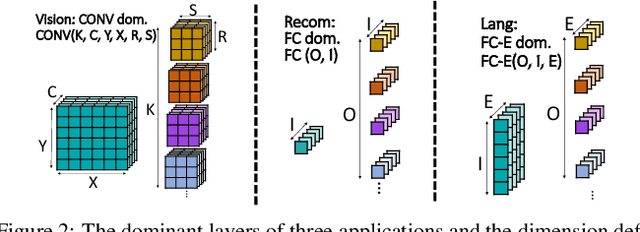

As Deep Learning continues to drive a variety of applications in datacenters and HPC, there is a growing trend towards building large accelerators with several sub-accelerator cores/chiplets. This work looks at the problem of supporting multi-tenancy on such accelerators. In particular, we focus on the problem of mapping layers from several DNNs simultaneously on an accelerator. Given the extremely large search space, we formulate the search as an optimization problem and develop a specialized genetic algorithm called G# withcustom operators to enable structured sample-efficient exploration. We quantitatively compare G# with several common heuristics, state-of-the-art optimization methods, and reinforcement learning methods across different accelerator set-tings (large/small accelerators) and different sub-accelerator configurations (homogeneous/heterogeneous), and observeG# can consistently find better solutions. Further, to enable real-time scheduling, we also demonstrate a method to generalize the learnt schedules and transfer them to the next batch of jobs, reducing schedule compute time to near zero.