 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATTACC the Quadratic Bottleneck of Attention Layers
Jul 13, 2021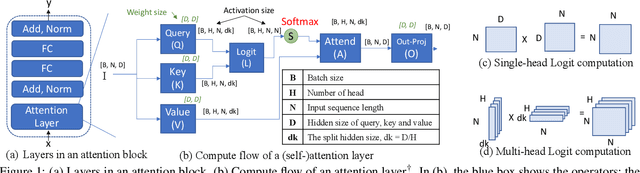
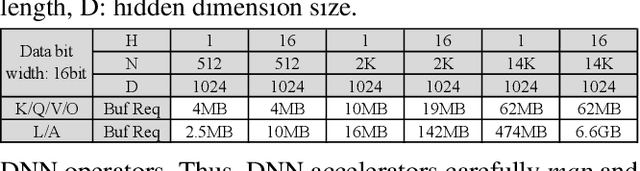
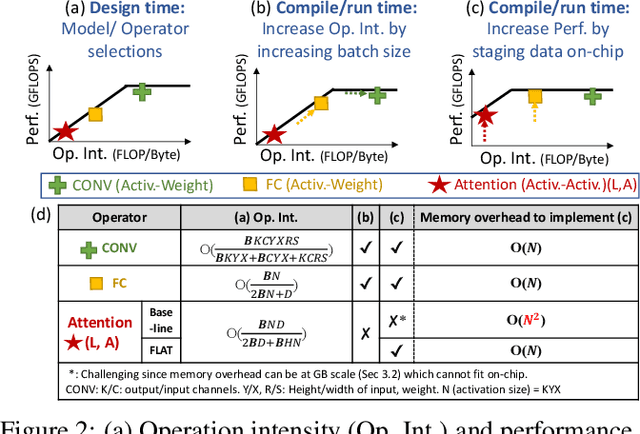
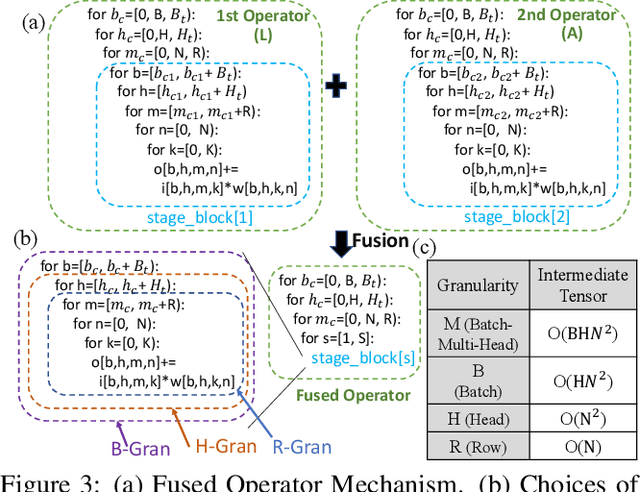
Attention mechanisms form the backbone of state-of-the-art machine learning models for a variety of tasks. Deploying them on deep neural network (DNN) accelerators, however, is prohibitively challenging especially under long sequences. Operators in attention layers exhibit limited reuse and quadratic growth in memory footprint, leading to severe memory-boundedness. This paper introduces a new attention-tailored dataflow, termed FLAT, which leverages operator fusion, loop-nest optimizations, and interleaved execution. It increases the effective memory bandwidth by efficiently utilizing the high-bandwidth, low-capacity on-chip buffer and thus achieves better run time and compute resource utilization. We term FLAT-compatible accelerators ATTACC. In our evaluation, ATTACC achieves 1.94x and 1.76x speedup and 49% and 42% of energy reduction comparing to state-of-the-art edge and cloud accelerators.