 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaShiFlex: A High-Throughput Hardened Shifter DNN Accelerator with Fine-Tuning Flexibility
Dec 14, 2025We introduce a high-throughput neural network accelerator that embeds most network layers directly in hardware, minimizing data transfer and memory usage while preserving a degree of flexibility via a small neural processing unit for the final classification layer. By leveraging power-of-two (Po2) quantization for weights, we replace multiplications with simple rewiring, effectively reducing each convolution to a series of additions. This streamlined approach offers high-throughput, energy-efficient processing, making it highly suitable for applications where model parameters remain stable, such as continuous sensing tasks at the edge or large-scale data center deployments. Furthermore, by including a strategically chosen reprogrammable final layer, our design achieves high throughput without sacrificing fine-tuning capabilities. We implement this accelerator in a 7nm ASIC flow using MobileNetV2 as a baseline and report throughput, area, accuracy, and sensitivity to quantization and pruning - demonstrating both the advantages and potential trade-offs of the proposed architecture. We find that for MobileNetV2, we can improve inference throughput by 20x over fully programmable GPUs, processing 1.21 million images per second through a full forward pass while retaining fine-tuning flexibility. If absolutely no post-deployment fine tuning is required, this advantage increases to 67x at 4 million images per second.
Characterizing the Accuracy - Efficiency Trade-off of Low-rank Decomposition in Language Models
May 10, 2024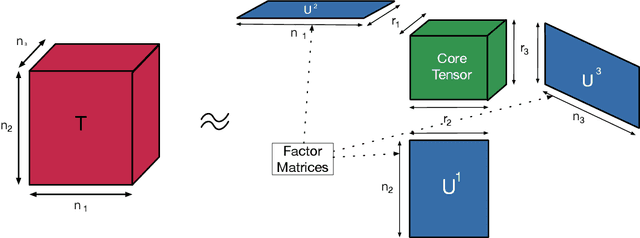


Large language models (LLMs) have emerged and presented their general problem-solving capabilities with one model. However, the model size has increased dramatically with billions of parameters to enable such broad problem-solving capabilities. In addition, due to the dominance of matrix-matrix and matrix-vector multiplications in LLMs, the compute-to-model size ratio is significantly lower than that of CNNs. This shift pushes LLMs from a computation-bound regime to a memory-bound regime. Therefore, optimizing the memory footprint and traffic is an important optimization direction for LLMs today. Model compression methods such as quantization and parameter pruning have been actively explored for achieving the memory footprint and traffic optimization. However, the accuracy-efficiency trade-off of rank pruning for LLMs is not well-understood yet. Therefore, we characterize the accuracy-efficiency trade-off of a low-rank decomposition method, specifically Tucker decomposition, on recent language models, including an open-source LLM, Llama 2. We formalize the low-rank decomposition design space and show that the decomposition design space is enormous (e.g., O($2^{37}$) for Llama2-7B). To navigate such a vast design space, we formulate the design space and perform thorough case studies of accuracy-efficiency trade-offs using six widely used LLM benchmarks on BERT and Llama 2 models. Our results show that we can achieve a 9\% model size reduction with minimal accuracy drops, which range from 4\%p to 10\%p, depending on the difficulty of the benchmark, without any retraining to recover accuracy after decomposition. The results show that low-rank decomposition can be a promising direction for LLM-based applications that require real-time service in scale (e.g., AI agent assist and real-time coding assistant), where the latency is as important as the model accuracy.
DiGamma: Domain-aware Genetic Algorithm for HW-Mapping Co-optimization for DNN Accelerators
Jan 26, 2022

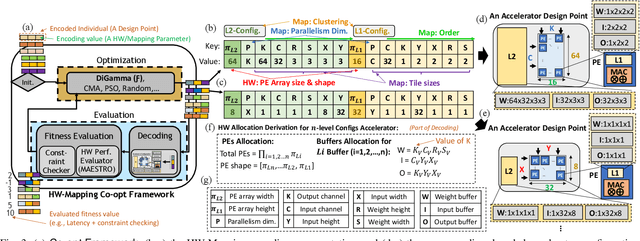

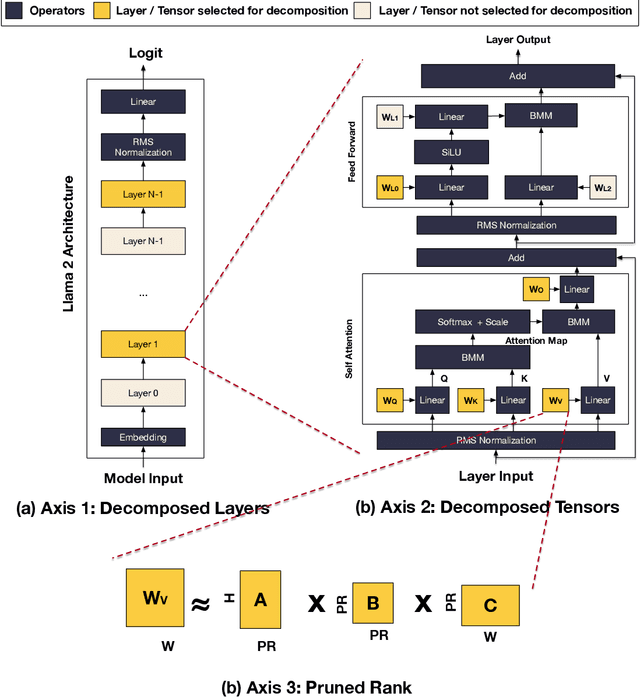
The design of DNN accelerators includes two key parts: HW resource configuration and mapping strategy. Intensive research has been conducted to optimize each of them independently. Unfortunately, optimizing for both together is extremely challenging due to the extremely large cross-coupled search space. To address this, in this paper, we propose a HW-Mapping co-optimization framework, an efficient encoding of the immense design space constructed by HW and Mapping, and a domain-aware genetic algorithm, named DiGamma, with specialized operators for improving search efficiency. We evaluate DiGamma with seven popular DNNs models with different properties. Our evaluations show DiGamma can achieve (geomean) 3.0x and 10.0x speedup, comparing to the best-performing baseline optimization algorithms, in edge and cloud settings.
Self-Adaptive Reconfigurable Arrays (SARA): Using ML to Assist Scaling GEMM Acceleration
Jan 12, 2021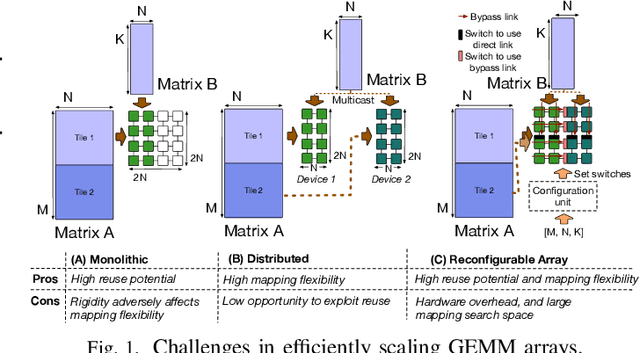
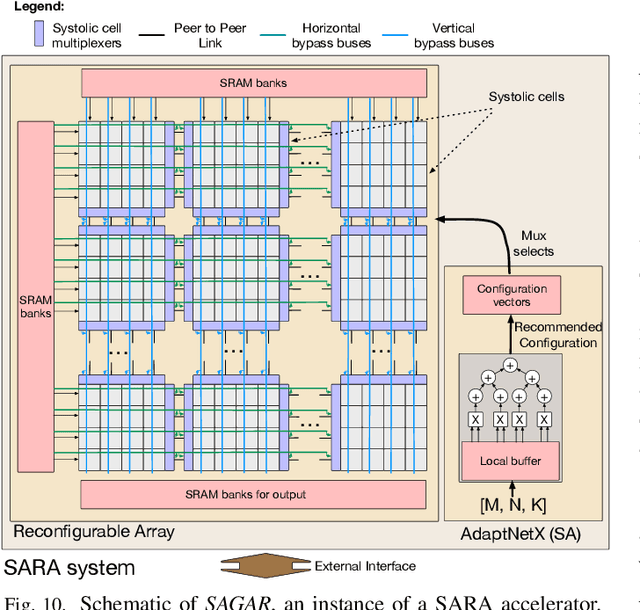
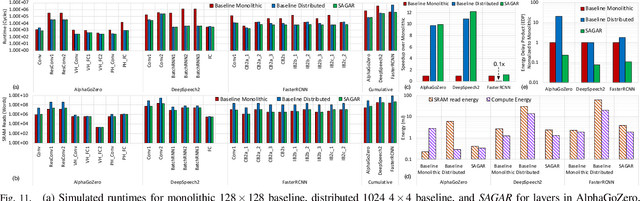
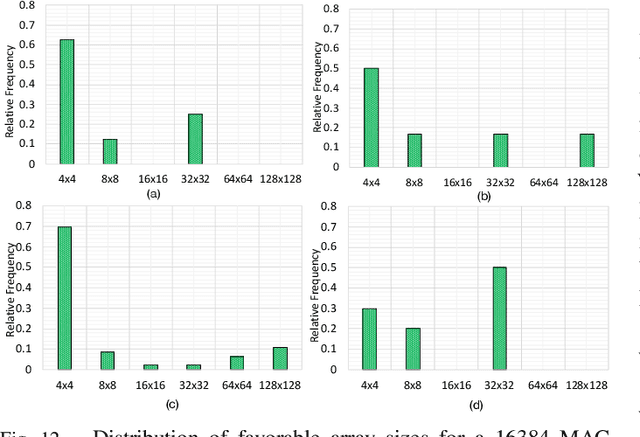
With increasing diversity in Deep Neural Network(DNN) models in terms of layer shapes and sizes, the research community has been investigating flexible/reconfigurable accelerator substrates. This line of research has opened up two challenges. The first is to determine the appropriate amount of flexibility within an accelerator array that that can trade-off the performance benefits versus the area overheads of the reconfigurability. The second is being able to determine the right configuration of the array for the current DNN model and/or layer and reconfigure the accelerator at runtime. This work introduces a new class of accelerators that we call Self Adaptive Reconfigurable Array (SARA). SARA architectures comprise of both a reconfigurable array and a hardware unit capable of determining an optimized configuration for the array at runtime. We demonstrate an instance of SARA with an accelerator we call SAGAR, which introduces a novel reconfigurable systolic array that can be configured to work as a distributed collection of smaller arrays of various sizes or as a single array with flexible aspect ratios. We also develop a novel recommendation neural network called ADAPTNET which recommends an array configuration and dataflow for the current layer parameters. ADAPTNET runs on an integrated custom hardware ADAPTNETX that runs ADAPTNET at runtime and reconfigures the array, making the entire accelerator self-sufficient. SAGAR is capable of providing the same mapping flexibility as a collection of 10244x4 arrays working as a distributed system while achieving 3.5x more power efficiency and 3.2x higher compute density Furthermore, the runtime achieved on the recommended parameters from ADAPTNET is 99.93% of the best achievable runtime.
An Analytic Model for Cost-Benefit Analysis of Dataflows in DNN Accelerators
Sep 13, 2018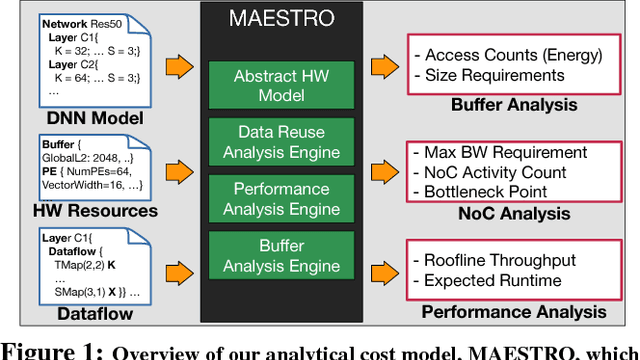
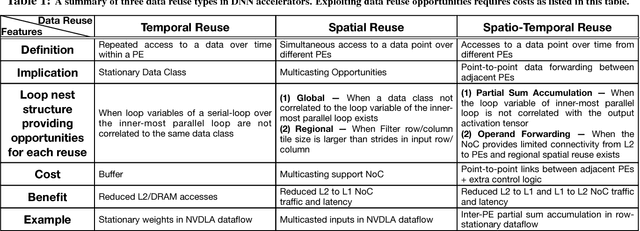
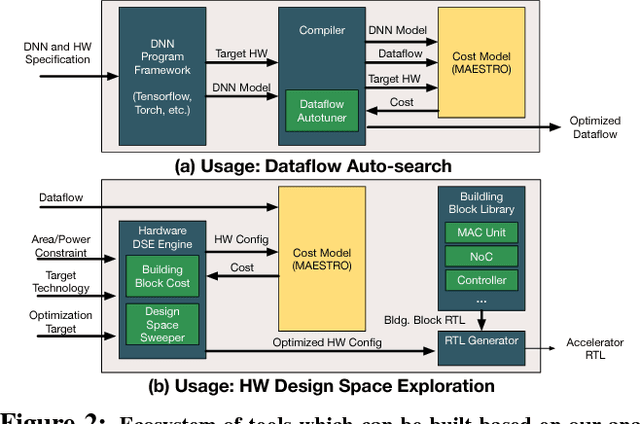

Efficiently tiling and mapping high-dimensional convolutions onto limited execution and buffering resources is a challenge faced by all deep learning accelerators today. We term each unique approach as dataflow. The dataflow determines overall throughput (utilization of the compute units) and energy-efficiency (reads, writes, and reuse of model parameters and partial sums across the accelerator's memory hierarchy). In this work, we provide a first-of-its kind framework called MAESTRO to formally describe and analyze CNN dataflows. MAESTRO uses a set of concise pragmas to describe three kinds of data reuse - spatial, temporal, and spatio-temporal. It predicts roofline performance and energy-efficiency of each dataflow when running neural network layers, and reports the hardware resources (size of buffers across the memory hierarchy, and network-on-chip (NoC) bandwidth) required to support this dataflow. Using MAESTRO, we demonstrate trade-offs between various dataflows, and demonstrate the potential benefits of a hardware substrate with a specialized NoC that can support adaptive dataflows.
UCNN: Exploiting Computational Reuse in Deep Neural Networks via Weight Repetition
Apr 18, 2018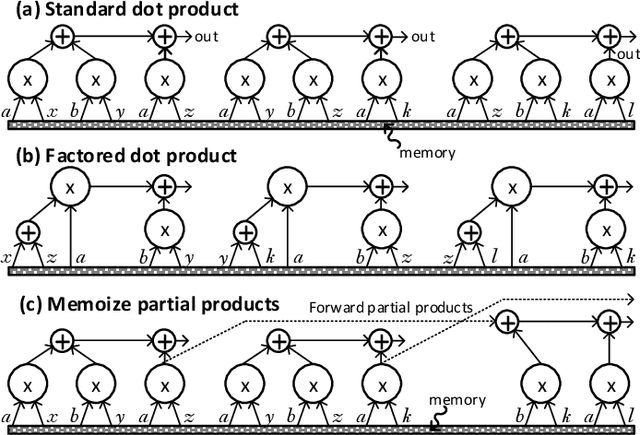
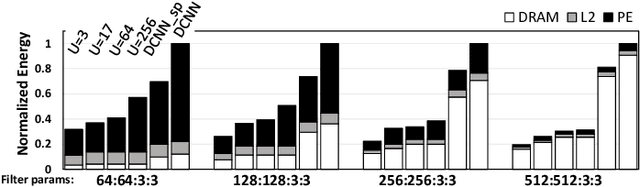
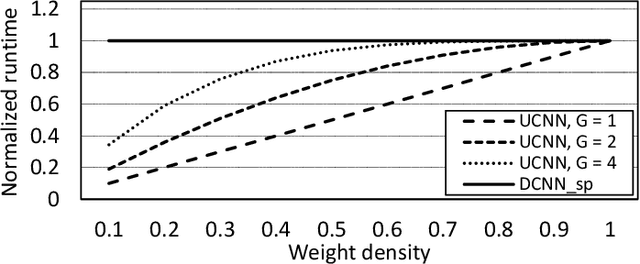
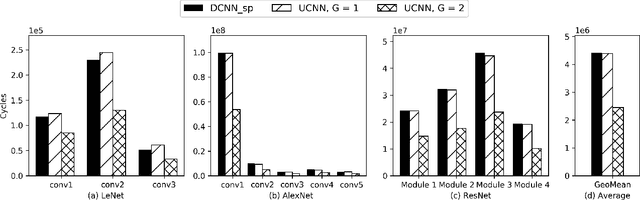
Convolutional Neural Networks (CNNs) have begun to permeate all corners of electronic society (from voice recognition to scene generation) due to their high accuracy and machine efficiency per operation. At their core, CNN computations are made up of multi-dimensional dot products between weight and input vectors. This paper studies how weight repetition ---when the same weight occurs multiple times in or across weight vectors--- can be exploited to save energy and improve performance during CNN inference. This generalizes a popular line of work to improve efficiency from CNN weight sparsity, as reducing computation due to repeated zero weights is a special case of reducing computation due to repeated weights. To exploit weight repetition, this paper proposes a new CNN accelerator called the Unique Weight CNN Accelerator (UCNN). UCNN uses weight repetition to reuse CNN sub-computations (e.g., dot products) and to reduce CNN model size when stored in off-chip DRAM ---both of which save energy. UCNN further improves performance by exploiting sparsity in weights. We evaluate UCNN with an accelerator-level cycle and energy model and with an RTL implementation of the UCNN processing element. On three contemporary CNNs, UCNN improves throughput-normalized energy consumption by 1.2x - 4x, relative to a similarly provisioned baseline accelerator that uses Eyeriss-style sparsity optimizations. At the same time, the UCNN processing element adds only 17-24% area overhead relative to the same baseline.