 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNSFlow: An End-to-End FPGA Framework with Scalable Dataflow Architecture for Neuro-Symbolic AI
Apr 29, 2025Neuro-Symbolic AI (NSAI) is an emerging paradigm that integrates neural networks with symbolic reasoning to enhance the transparency, reasoning capabilities, and data efficiency of AI systems. Recent NSAI systems have gained traction due to their exceptional performance in reasoning tasks and human-AI collaborative scenarios. Despite these algorithmic advancements, executing NSAI tasks on existing hardware (e.g., CPUs, GPUs, TPUs) remains challenging, due to their heterogeneous computing kernels, high memory intensity, and unique memory access patterns. Moreover, current NSAI algorithms exhibit significant variation in operation types and scales, making them incompatible with existing ML accelerators. These challenges highlight the need for a versatile and flexible acceleration framework tailored to NSAI workloads. In this paper, we propose NSFlow, an FPGA-based acceleration framework designed to achieve high efficiency, scalability, and versatility across NSAI systems. NSFlow features a design architecture generator that identifies workload data dependencies and creates optimized dataflow architectures, as well as a reconfigurable array with flexible compute units, re-organizable memory, and mixed-precision capabilities. Evaluating across NSAI workloads, NSFlow achieves 31x speedup over Jetson TX2, more than 2x over GPU, 8x speedup over TPU-like systolic array, and more than 3x over Xilinx DPU. NSFlow also demonstrates enhanced scalability, with only 4x runtime increase when symbolic workloads scale by 150x. To the best of our knowledge, NSFlow is the first framework to enable real-time generalizable NSAI algorithms acceleration, demonstrating a promising solution for next-generation cognitive systems.
RASA: Efficient Register-Aware Systolic Array Matrix Engine for CPU
Oct 05, 2021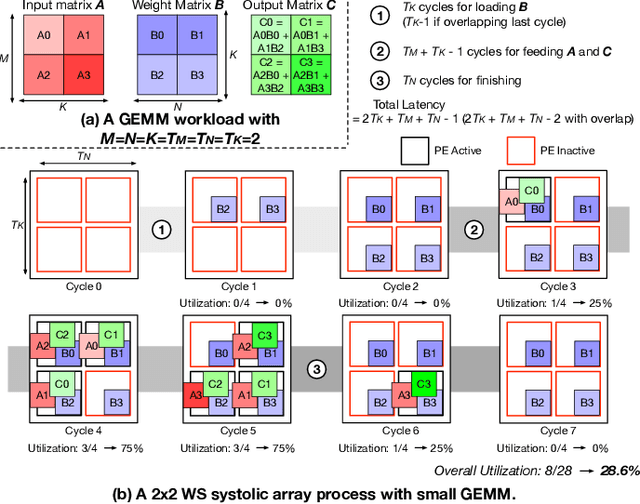
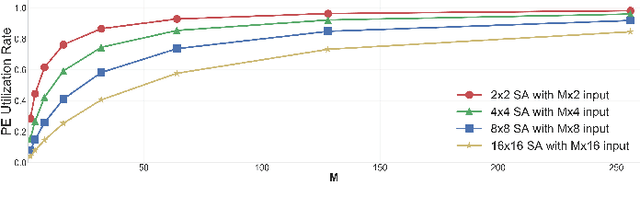
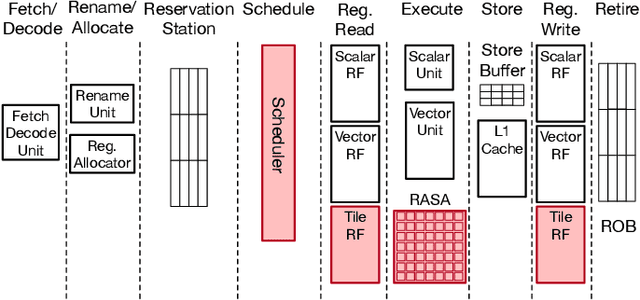
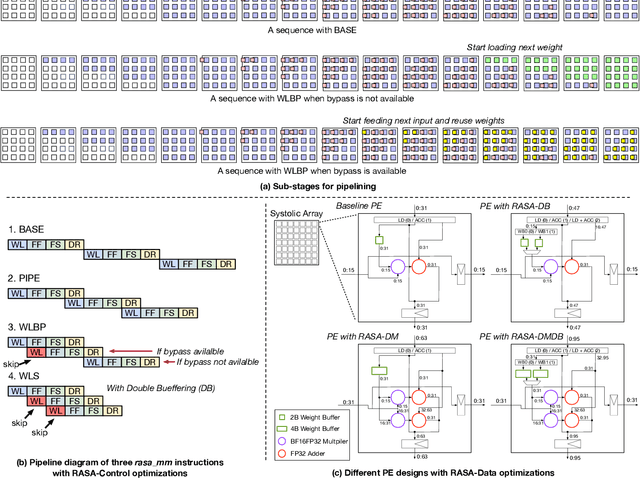
As AI-based applications become pervasive, CPU vendors are starting to incorporate matrix engines within the datapath to boost efficiency. Systolic arrays have been the premier architectural choice as matrix engines in offload accelerators. However, we demonstrate that incorporating them inside CPUs can introduce under-utilization and stalls due to limited register storage to amortize the fill and drain times of the array. To address this, we propose RASA, Register-Aware Systolic Array. We develop techniques to divide an execution stage into several sub-stages and overlap instructions to hide overheads and run them concurrently. RASA-based designs improve performance significantly with negligible area and power overhead.
AIRCHITECT: Learning Custom Architecture Design and Mapping Space
Aug 16, 2021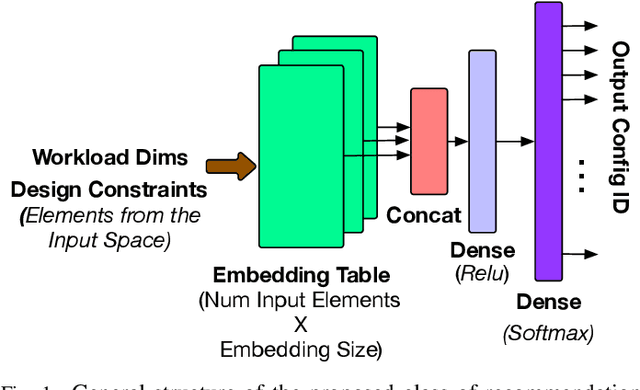
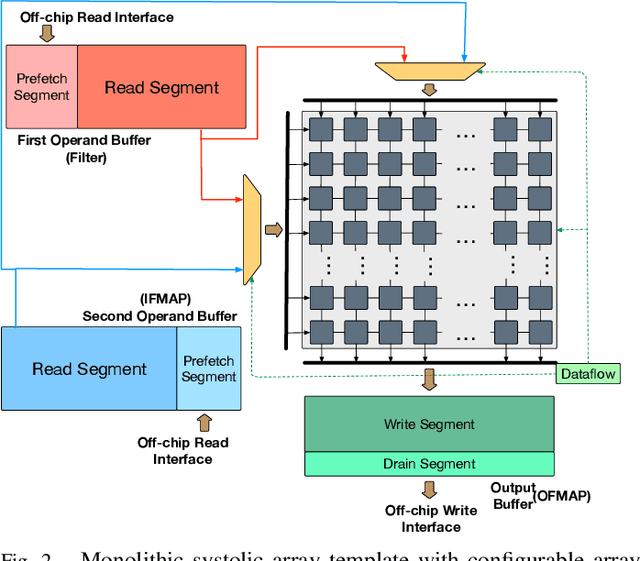
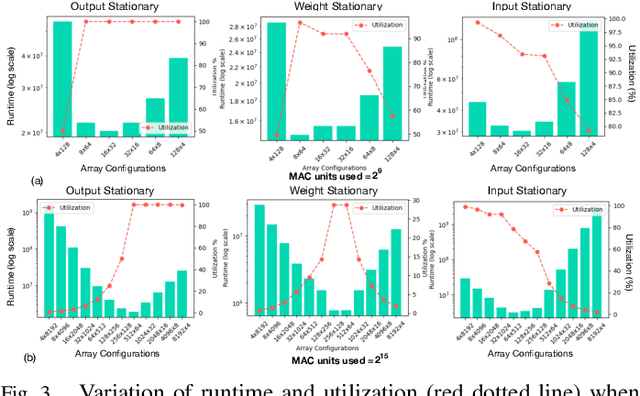
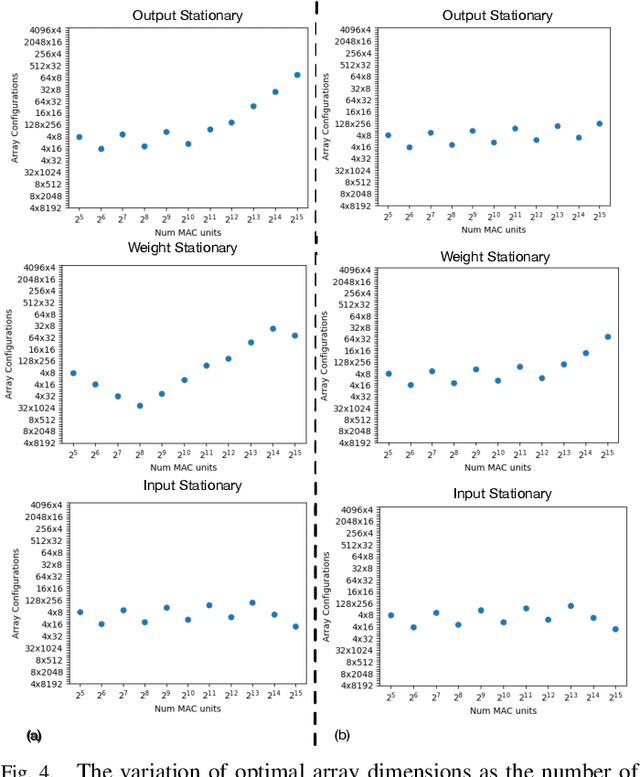
Design space exploration is an important but costly step involved in the design/deployment of custom architectures to squeeze out maximum possible performance and energy efficiency. Conventionally, optimizations require iterative sampling of the design space using simulation or heuristic tools. In this paper we investigate the possibility of learning the optimization task using machine learning and hence using the learnt model to predict optimal parameters for the design and mapping space of custom architectures, bypassing any exploration step. We use three case studies involving the optimal array design, SRAM buffer sizing, mapping, and schedule determination for systolic-array-based custom architecture design and mapping space. Within the purview of these case studies, we show that it is possible to capture the design space and train a model to "generalize" prediction the optimal design and mapping parameters when queried with workload and design constraints. We perform systematic design-aware and statistical analysis of the optimization space for our case studies and highlight the patterns in the design space. We formulate the architecture design and mapping as a machine learning problem that allows us to leverage existing ML models for training and inference. We design and train a custom network architecture called AIRCHITECT, which is capable of learning the architecture design space with as high as 94.3% test accuracy and predicting optimal configurations which achieve on average (GeoMean) of 99.9% the best possible performance on a test dataset with $10^5$ GEMM workloads.
Self-Adaptive Reconfigurable Arrays (SARA): Using ML to Assist Scaling GEMM Acceleration
Jan 12, 2021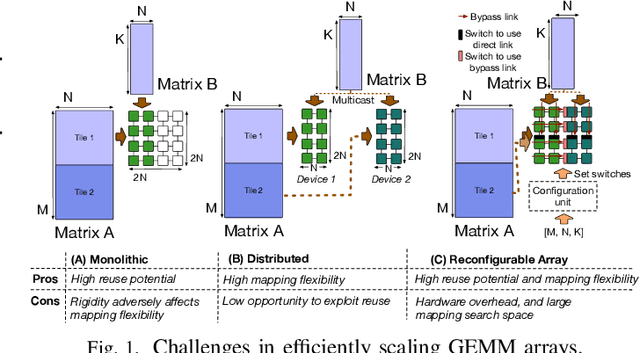
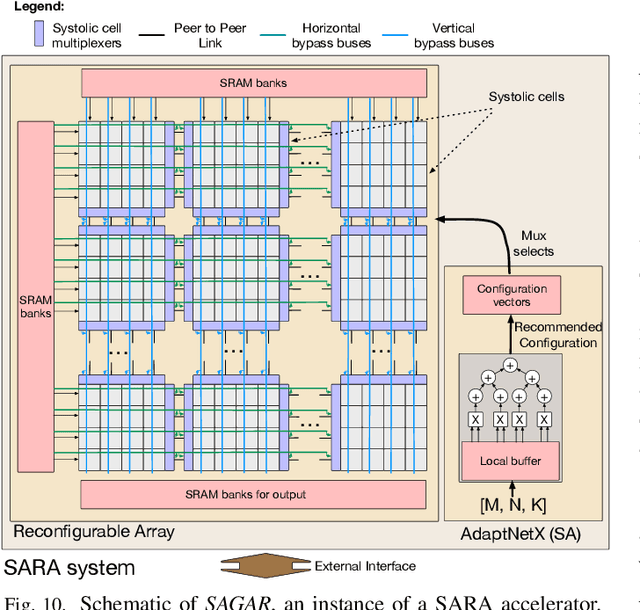
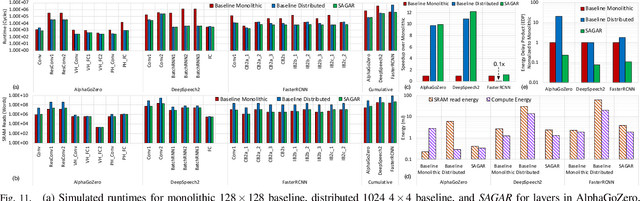
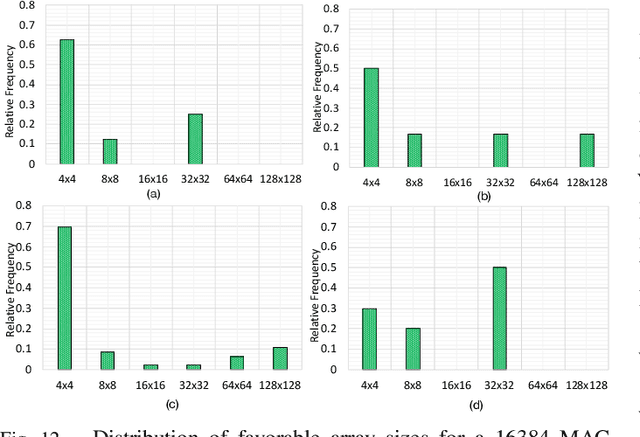
With increasing diversity in Deep Neural Network(DNN) models in terms of layer shapes and sizes, the research community has been investigating flexible/reconfigurable accelerator substrates. This line of research has opened up two challenges. The first is to determine the appropriate amount of flexibility within an accelerator array that that can trade-off the performance benefits versus the area overheads of the reconfigurability. The second is being able to determine the right configuration of the array for the current DNN model and/or layer and reconfigure the accelerator at runtime. This work introduces a new class of accelerators that we call Self Adaptive Reconfigurable Array (SARA). SARA architectures comprise of both a reconfigurable array and a hardware unit capable of determining an optimized configuration for the array at runtime. We demonstrate an instance of SARA with an accelerator we call SAGAR, which introduces a novel reconfigurable systolic array that can be configured to work as a distributed collection of smaller arrays of various sizes or as a single array with flexible aspect ratios. We also develop a novel recommendation neural network called ADAPTNET which recommends an array configuration and dataflow for the current layer parameters. ADAPTNET runs on an integrated custom hardware ADAPTNETX that runs ADAPTNET at runtime and reconfigures the array, making the entire accelerator self-sufficient. SAGAR is capable of providing the same mapping flexibility as a collection of 10244x4 arrays working as a distributed system while achieving 3.5x more power efficiency and 3.2x higher compute density Furthermore, the runtime achieved on the recommended parameters from ADAPTNET is 99.93% of the best achievable runtime.
CLAN: Continuous Learning using Asynchronous Neuroevolution on Commodity Edge Devices
Aug 27, 2020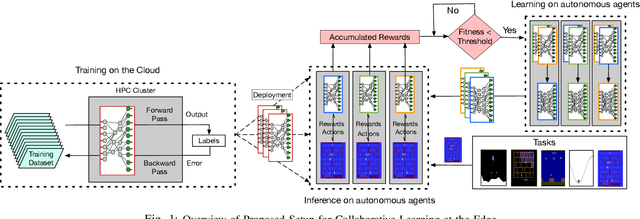
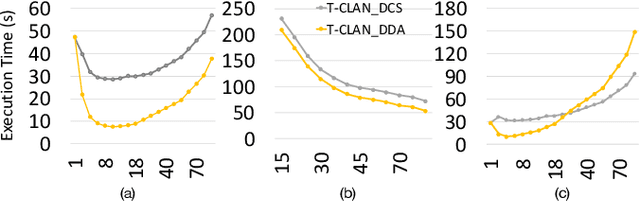

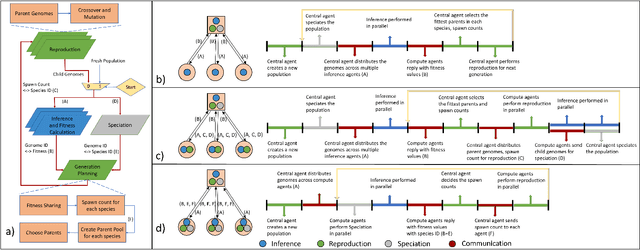
Recent advancements in machine learning algorithms, especially the development of Deep Neural Networks (DNNs) have transformed the landscape of Artificial Intelligence (AI). With every passing day, deep learning based methods are applied to solve new problems with exceptional results. The portal to the real world is the edge. The true impact of AI can only be fully realized if we can have AI agents continuously interacting with the real world and solving everyday problems. Unfortunately, high compute and memory requirements of DNNs acts a huge barrier towards this vision. Today we circumvent this problem by deploying special purpose inference hardware on the edge while procuring trained models from the cloud. This approach, however, relies on constant interaction with the cloud for transmitting all the data, training on massive GPU clusters, and downloading updated models. This is challenging for bandwidth, privacy, and constant connectivity concerns that autonomous agents may exhibit. In this paper we evaluate techniques for enabling adaptive intelligence on edge devices with zero interaction with any high-end cloud/server. We build a prototype distributed system of Raspberry Pis communicating via WiFi running NeuroEvolutionary (NE) learning and inference. We evaluate the performance of such a collaborative system and detail the compute/communication characteristics of different arrangements of the system that trade-off parallelism versus communication. Using insights from our analysis, we also propose algorithmic modifications to reduce communication by up to 3.6x during the learning phase to enhance scalability even further and match performance of higher end computing devices at scale. We believe that these insights will enable algorithm-hardware co-design efforts for enabling continuous learning on the edge.
GeneSys: Enabling Continuous Learning through Neural Network Evolution in Hardware
Sep 13, 2018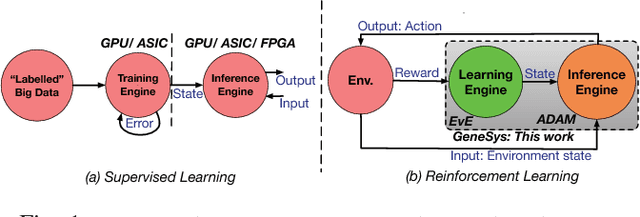
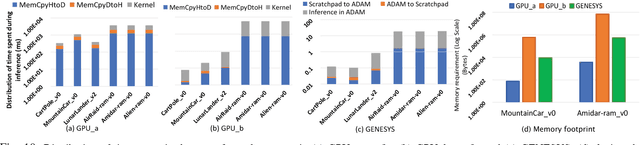
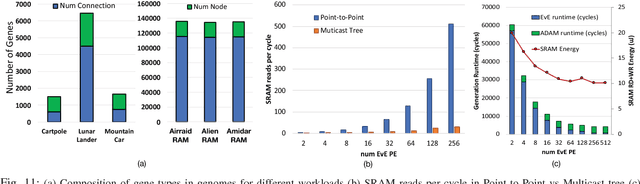
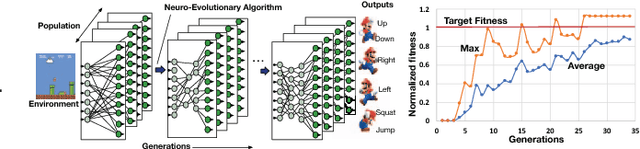
Modern deep learning systems rely on (a) a hand-tuned neural network topology, (b) massive amounts of labeled training data, and (c) extensive training over large-scale compute resources to build a system that can perform efficient image classification or speech recognition. Unfortunately, we are still far away from implementing adaptive general purpose intelligent systems which would need to learn autonomously in unknown environments and may not have access to some or any of these three components. Reinforcement learning and evolutionary algorithm (EA) based methods circumvent this problem by continuously interacting with the environment and updating the models based on obtained rewards. However, deploying these algorithms on ubiquitous autonomous agents at the edge (robots/drones) demands extremely high energy-efficiency due to (i) tight power and energy budgets, (ii) continuous/lifelong interaction with the environment, (iii) intermittent or no connectivity to the cloud to run heavy-weight processing. To address this need, we present GENESYS, an HW-SW prototype of an EA-based learning system, that comprises a closed loop learning engine called EvE and an inference engine called ADAM. EvE can evolve the topology and weights of neural networks completely in hardware for the task at hand, without requiring hand-optimization or backpropagation training. ADAM continuously interacts with the environment and is optimized for efficiently running the irregular neural networks generated by EvE. GENESYS identifies and leverages multiple unique avenues of parallelism unique to EAs that we term 'gene'- level parallelism, and 'population'-level parallelism. We ran GENESYS with a suite of environments from OpenAI gym and observed 2-5 orders of magnitude higher energy-efficiency over state-of-the-art embedded and desktop CPU and GPU systems.