 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Adaptive Reconfigurable Arrays (SARA): Using ML to Assist Scaling GEMM Acceleration
Paper and Code
Jan 12, 2021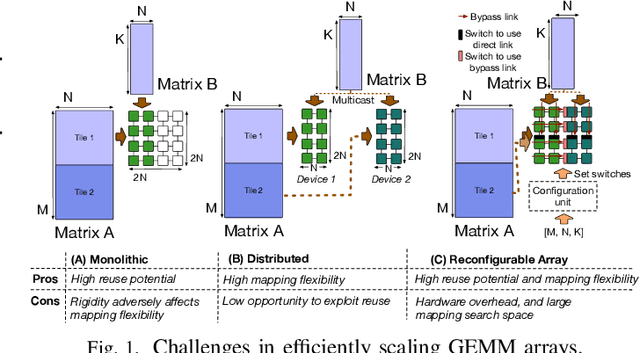
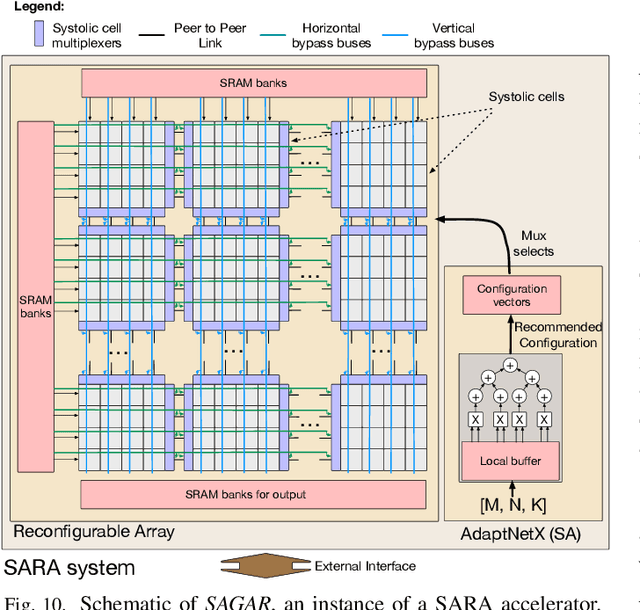
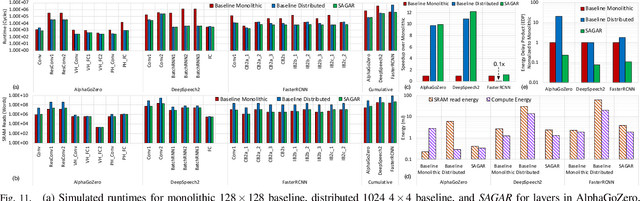
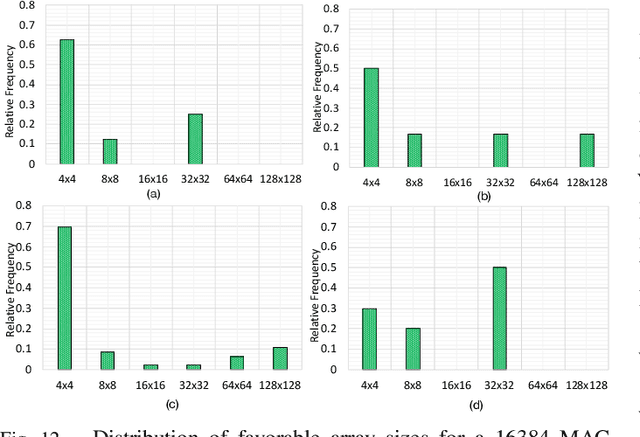
With increasing diversity in Deep Neural Network(DNN) models in terms of layer shapes and sizes, the research community has been investigating flexible/reconfigurable accelerator substrates. This line of research has opened up two challenges. The first is to determine the appropriate amount of flexibility within an accelerator array that that can trade-off the performance benefits versus the area overheads of the reconfigurability. The second is being able to determine the right configuration of the array for the current DNN model and/or layer and reconfigure the accelerator at runtime. This work introduces a new class of accelerators that we call Self Adaptive Reconfigurable Array (SARA). SARA architectures comprise of both a reconfigurable array and a hardware unit capable of determining an optimized configuration for the array at runtime. We demonstrate an instance of SARA with an accelerator we call SAGAR, which introduces a novel reconfigurable systolic array that can be configured to work as a distributed collection of smaller arrays of various sizes or as a single array with flexible aspect ratios. We also develop a novel recommendation neural network called ADAPTNET which recommends an array configuration and dataflow for the current layer parameters. ADAPTNET runs on an integrated custom hardware ADAPTNETX that runs ADAPTNET at runtime and reconfigures the array, making the entire accelerator self-sufficient. SAGAR is capable of providing the same mapping flexibility as a collection of 10244x4 arrays working as a distributed system while achieving 3.5x more power efficiency and 3.2x higher compute density Furthermore, the runtime achieved on the recommended parameters from ADAPTNET is 99.93% of the best achievable runtime.