 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
Training Video Foundation Models with NVIDIA NeMo
Mar 17, 2025Video Foundation Models (VFMs) have recently been used to simulate the real world to train physical AI systems and develop creative visual experiences. However, there are significant challenges in training large-scale, high quality VFMs that can generate high-quality videos. We present a scalable, open-source VFM training pipeline with NVIDIA NeMo, providing accelerated video dataset curation, multimodal data loading, and parallelized video diffusion model training and inference. We also provide a comprehensive performance analysis highlighting best practices for efficient VFM training and inference.
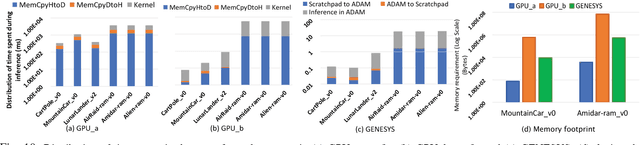
CLAN: Continuous Learning using Asynchronous Neuroevolution on Commodity Edge Devices
Aug 27, 2020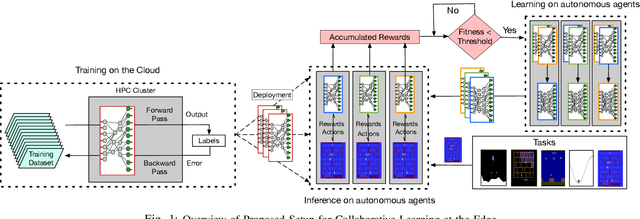
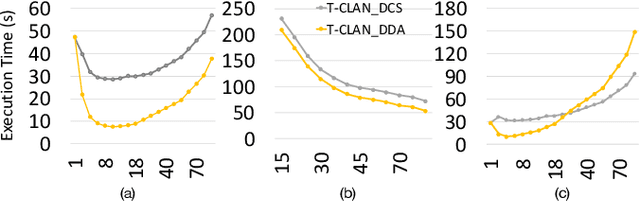

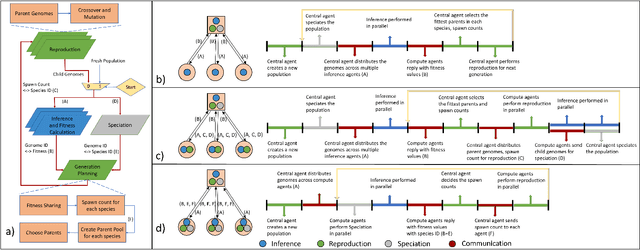
Recent advancements in machine learning algorithms, especially the development of Deep Neural Networks (DNNs) have transformed the landscape of Artificial Intelligence (AI). With every passing day, deep learning based methods are applied to solve new problems with exceptional results. The portal to the real world is the edge. The true impact of AI can only be fully realized if we can have AI agents continuously interacting with the real world and solving everyday problems. Unfortunately, high compute and memory requirements of DNNs acts a huge barrier towards this vision. Today we circumvent this problem by deploying special purpose inference hardware on the edge while procuring trained models from the cloud. This approach, however, relies on constant interaction with the cloud for transmitting all the data, training on massive GPU clusters, and downloading updated models. This is challenging for bandwidth, privacy, and constant connectivity concerns that autonomous agents may exhibit. In this paper we evaluate techniques for enabling adaptive intelligence on edge devices with zero interaction with any high-end cloud/server. We build a prototype distributed system of Raspberry Pis communicating via WiFi running NeuroEvolutionary (NE) learning and inference. We evaluate the performance of such a collaborative system and detail the compute/communication characteristics of different arrangements of the system that trade-off parallelism versus communication. Using insights from our analysis, we also propose algorithmic modifications to reduce communication by up to 3.6x during the learning phase to enhance scalability even further and match performance of higher end computing devices at scale. We believe that these insights will enable algorithm-hardware co-design efforts for enabling continuous learning on the edge.
GeneSys: Enabling Continuous Learning through Neural Network Evolution in Hardware
Sep 13, 2018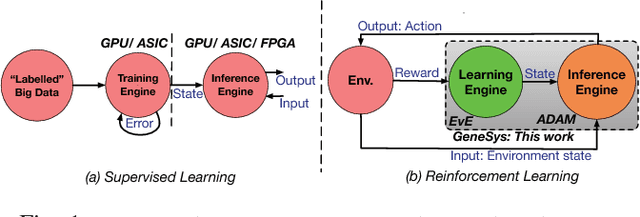
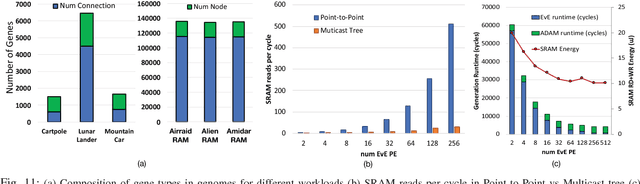
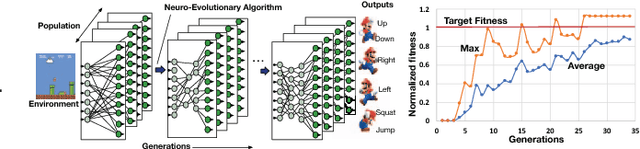
Modern deep learning systems rely on (a) a hand-tuned neural network topology, (b) massive amounts of labeled training data, and (c) extensive training over large-scale compute resources to build a system that can perform efficient image classification or speech recognition. Unfortunately, we are still far away from implementing adaptive general purpose intelligent systems which would need to learn autonomously in unknown environments and may not have access to some or any of these three components. Reinforcement learning and evolutionary algorithm (EA) based methods circumvent this problem by continuously interacting with the environment and updating the models based on obtained rewards. However, deploying these algorithms on ubiquitous autonomous agents at the edge (robots/drones) demands extremely high energy-efficiency due to (i) tight power and energy budgets, (ii) continuous/lifelong interaction with the environment, (iii) intermittent or no connectivity to the cloud to run heavy-weight processing. To address this need, we present GENESYS, an HW-SW prototype of an EA-based learning system, that comprises a closed loop learning engine called EvE and an inference engine called ADAM. EvE can evolve the topology and weights of neural networks completely in hardware for the task at hand, without requiring hand-optimization or backpropagation training. ADAM continuously interacts with the environment and is optimized for efficiently running the irregular neural networks generated by EvE. GENESYS identifies and leverages multiple unique avenues of parallelism unique to EAs that we term 'gene'- level parallelism, and 'population'-level parallelism. We ran GENESYS with a suite of environments from OpenAI gym and observed 2-5 orders of magnitude higher energy-efficiency over state-of-the-art embedded and desktop CPU and GPU systems.