 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecuring Virtual Reality Experiences: Unveiling and Tackling Cybersickness Attacks with Explainable AI
Mar 17, 2025The synergy between virtual reality (VR) and artificial intelligence (AI), specifically deep learning (DL)-based cybersickness detection models, has ushered in unprecedented advancements in immersive experiences by automatically detecting cybersickness severity and adaptively various mitigation techniques, offering a smooth and comfortable VR experience. While this DL-enabled cybersickness detection method provides promising solutions for enhancing user experiences, it also introduces new risks since these models are vulnerable to adversarial attacks; a small perturbation of the input data that is visually undetectable to human observers can fool the cybersickness detection model and trigger unexpected mitigation, thus disrupting user immersive experiences (UIX) and even posing safety risks. In this paper, we present a new type of VR attack, i.e., a cybersickness attack, which successfully stops the triggering of cybersickness mitigation by fooling DL-based cybersickness detection models and dramatically hinders the UIX. Next, we propose a novel explainable artificial intelligence (XAI)-guided cybersickness attack detection framework to detect such attacks in VR to ensure UIX and a comfortable VR experience. We evaluate the proposed attack and the detection framework using two state-of-the-art open-source VR cybersickness datasets: Simulation 2021 and Gameplay dataset. Finally, to verify the effectiveness of our proposed method, we implement the attack and the XAI-based detection using a testbed with a custom-built VR roller coaster simulation with an HTC Vive Pro Eye headset and perform a user study. Our study shows that such an attack can dramatically hinder the UIX. However, our proposed XAI-guided cybersickness attack detection can successfully detect cybersickness attacks and trigger the proper mitigation, effectively reducing VR cybersickness.
AIRCHITECT: Learning Custom Architecture Design and Mapping Space
Aug 16, 2021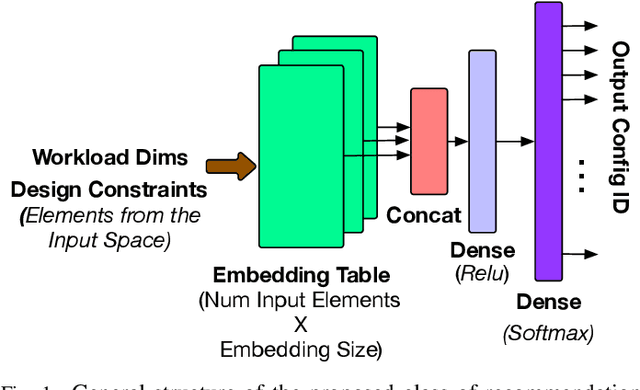
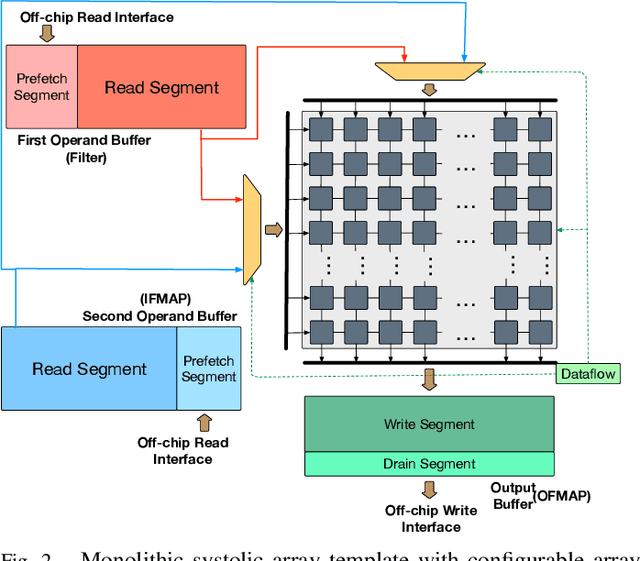
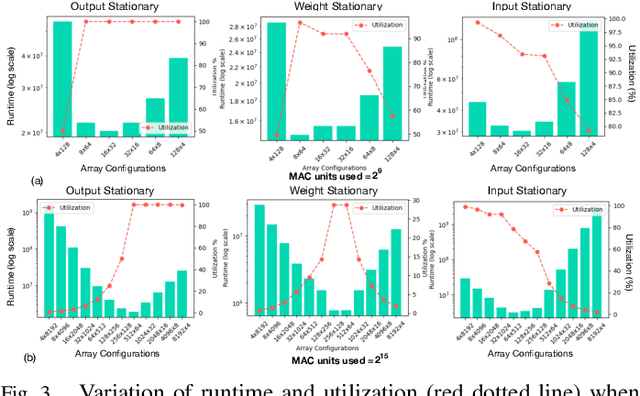
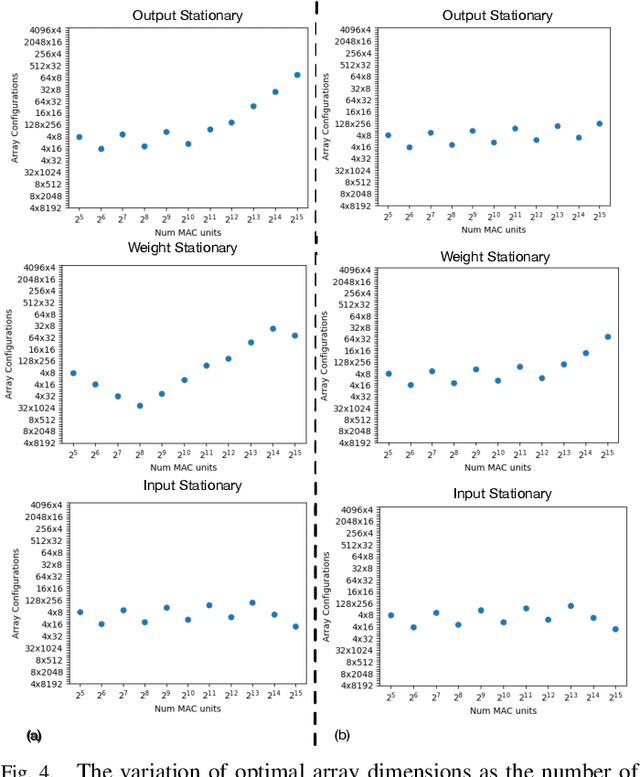
Design space exploration is an important but costly step involved in the design/deployment of custom architectures to squeeze out maximum possible performance and energy efficiency. Conventionally, optimizations require iterative sampling of the design space using simulation or heuristic tools. In this paper we investigate the possibility of learning the optimization task using machine learning and hence using the learnt model to predict optimal parameters for the design and mapping space of custom architectures, bypassing any exploration step. We use three case studies involving the optimal array design, SRAM buffer sizing, mapping, and schedule determination for systolic-array-based custom architecture design and mapping space. Within the purview of these case studies, we show that it is possible to capture the design space and train a model to "generalize" prediction the optimal design and mapping parameters when queried with workload and design constraints. We perform systematic design-aware and statistical analysis of the optimization space for our case studies and highlight the patterns in the design space. We formulate the architecture design and mapping as a machine learning problem that allows us to leverage existing ML models for training and inference. We design and train a custom network architecture called AIRCHITECT, which is capable of learning the architecture design space with as high as 94.3% test accuracy and predicting optimal configurations which achieve on average (GeoMean) of 99.9% the best possible performance on a test dataset with $10^5$ GEMM workloads.
Direct Spatial Implementation of Sparse Matrix Multipliers for Reservoir Computing
Jan 21, 2021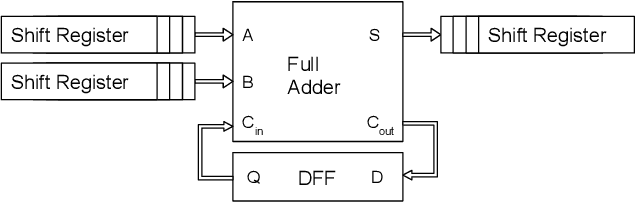
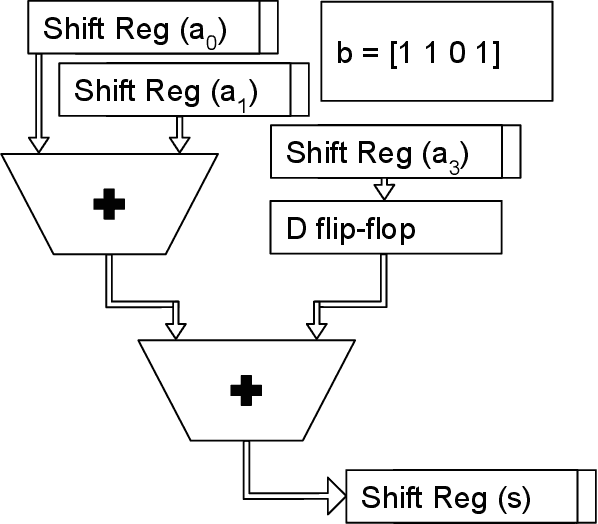
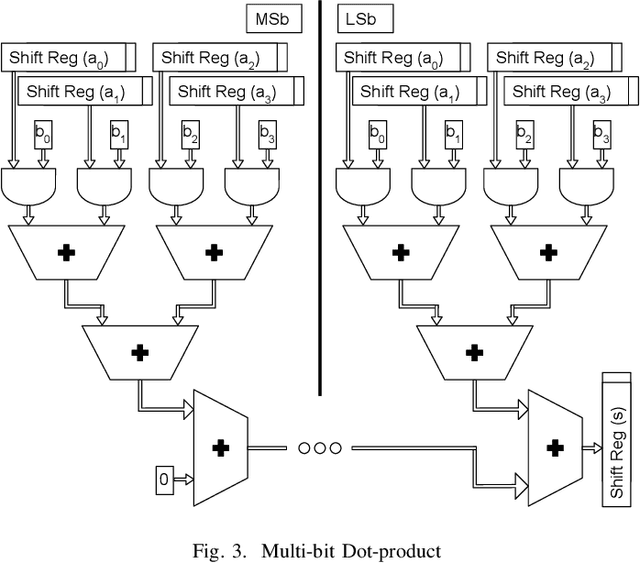
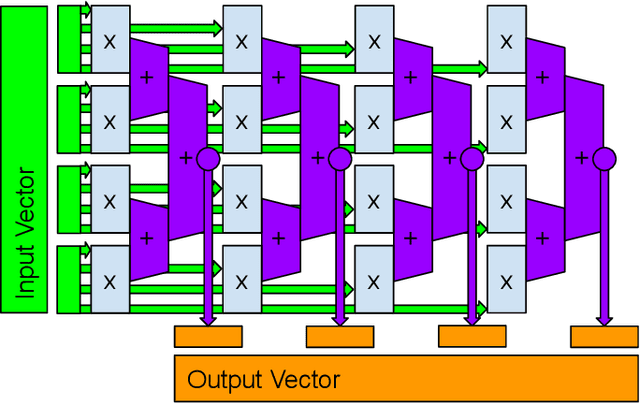
Reservoir computing systems rely on the recurrent multiplication of a very large, sparse, fixed matrix. We argue that direct spatial implementation of these fixed matrices minimizes the work performed in the computation, and allows for significant reduction in latency and power through constant propagation and logic minimization. Bit-serial arithmetic enables massive static matrices to be implemented. We present the structure of our bit-serial matrix multiplier, and evaluate using canonical signed digit representation to further reduce logic utilization. We have implemented these matrices on a large FPGA and provide a cost model that is simple and extensible. These FPGA implementations, on average, reduce latency by 50x up to 86x versus GPU libraries. Comparing against a recent sparse DNN accelerator, we measure a 4.1x to 47x reduction in latency depending on matrix dimension and sparsity. Throughput of the FPGA solution is also competitive for a wide range of matrix dimensions and batch sizes. Finally, we discuss ways these techniques could be deployed in ASICs, making them applicable for dynamic sparse matrix computations.