 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analytic Model for Cost-Benefit Analysis of Dataflows in DNN Accelerators
Paper and Code
Sep 13, 2018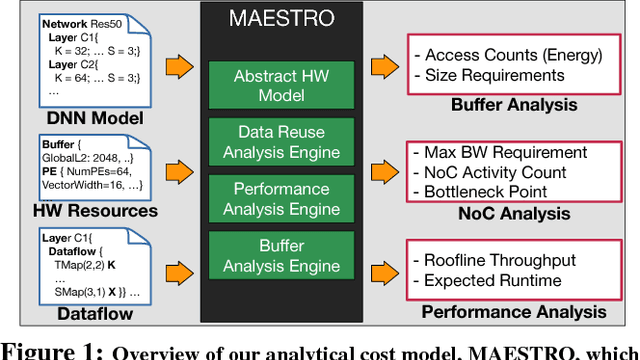
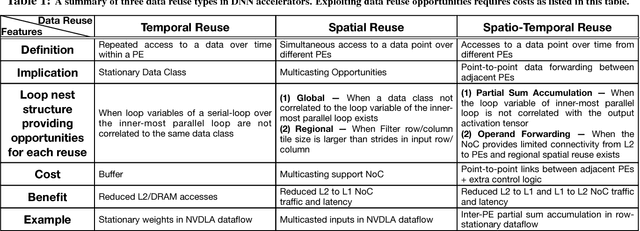
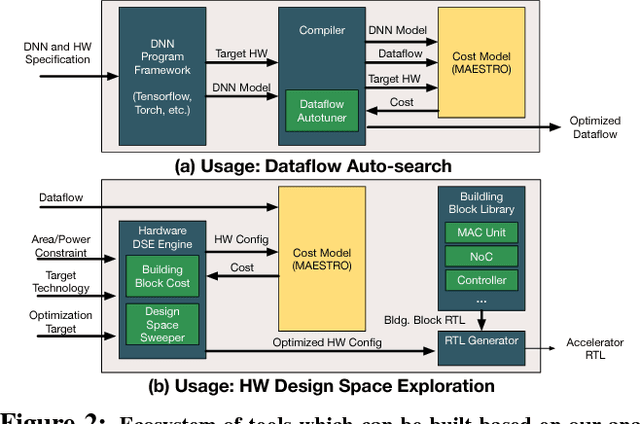

Efficiently tiling and mapping high-dimensional convolutions onto limited execution and buffering resources is a challenge faced by all deep learning accelerators today. We term each unique approach as dataflow. The dataflow determines overall throughput (utilization of the compute units) and energy-efficiency (reads, writes, and reuse of model parameters and partial sums across the accelerator's memory hierarchy). In this work, we provide a first-of-its kind framework called MAESTRO to formally describe and analyze CNN dataflows. MAESTRO uses a set of concise pragmas to describe three kinds of data reuse - spatial, temporal, and spatio-temporal. It predicts roofline performance and energy-efficiency of each dataflow when running neural network layers, and reports the hardware resources (size of buffers across the memory hierarchy, and network-on-chip (NoC) bandwidth) required to support this dataflow. Using MAESTRO, we demonstrate trade-offs between various dataflows, and demonstrate the potential benefits of a hardware substrate with a specialized NoC that can support adaptive dataflows.