 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind Mappings: Enabling Efficient Algorithm-Accelerator Mapping Space Search
Mar 02, 2021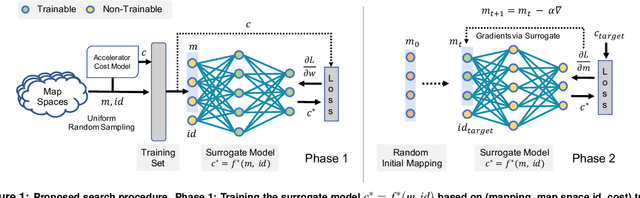
Modern day computing increasingly relies on specialization to satiate growing performance and efficiency requirements. A core challenge in designing such specialized hardware architectures is how to perform mapping space search, i.e., search for an optimal mapping from algorithm to hardware. Prior work shows that choosing an inefficient mapping can lead to multiplicative-factor efficiency overheads. Additionally, the search space is not only large but also non-convex and non-smooth, precluding advanced search techniques. As a result, previous works are forced to implement mapping space search using expert choices or sub-optimal search heuristics. This work proposes Mind Mappings, a novel gradient-based search method for algorithm-accelerator mapping space search. The key idea is to derive a smooth, differentiable approximation to the otherwise non-smooth, non-convex search space. With a smooth, differentiable approximation, we can leverage efficient gradient-based search algorithms to find high-quality mappings. We extensively compare Mind Mappings to black-box optimization schemes used in prior work. When tasked to find mappings for two important workloads (CNN and MTTKRP), the proposed search finds mappings that achieve an average $1.40\times$, $1.76\times$, and $1.29\times$ (when run for a fixed number of steps) and $3.16\times$, $4.19\times$, and $2.90\times$ (when run for a fixed amount of time) better energy-delay product (EDP) relative to Simulated Annealing, Genetic Algorithms and Reinforcement Learning, respectively. Meanwhile, Mind Mappings returns mappings with only $5.32\times$ higher EDP than a possibly unachievable theoretical lower-bound, indicating proximity to the global optima.
HarDNN: Feature Map Vulnerability Evaluation in CNNs
Feb 25, 2020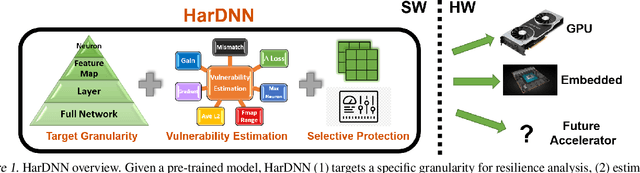
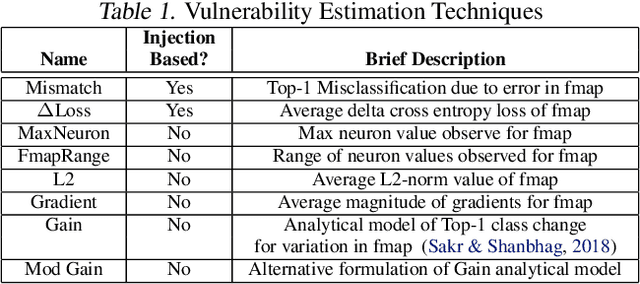
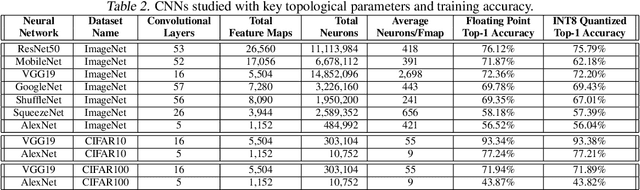
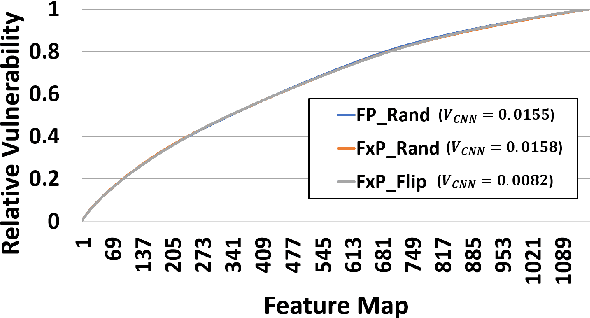
As Convolutional Neural Networks (CNNs) are increasingly being employed in safety-critical applications, it is important that they behave reliably in the face of hardware errors. Transient hardware errors may percolate undesirable state during execution, resulting in software-manifested errors which can adversely affect high-level decision making. This paper presents HarDNN, a software-directed approach to identify vulnerable computations during a CNN inference and selectively protect them based on their propensity towards corrupting the inference output in the presence of a hardware error. We show that HarDNN can accurately estimate relative vulnerability of a feature map (fmap) in CNNs using a statistical error injection campaign, and explore heuristics for fast vulnerability assessment. Based on these results, we analyze the tradeoff between error coverage and computational overhead that the system designers can use to employ selective protection. Results show that the improvement in resilience for the added computation is superlinear with HarDNN. For example, HarDNN improves SqueezeNet's resilience by 10x with just 30% additional computations.
Morph: Flexible Acceleration for 3D CNN-based Video Understanding
Oct 16, 2018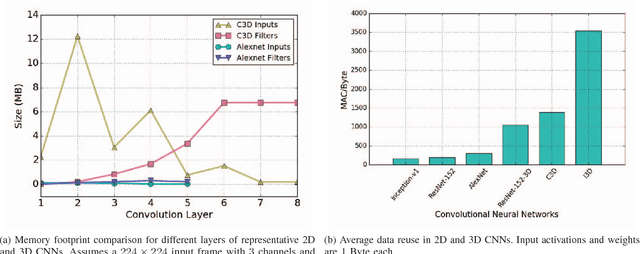
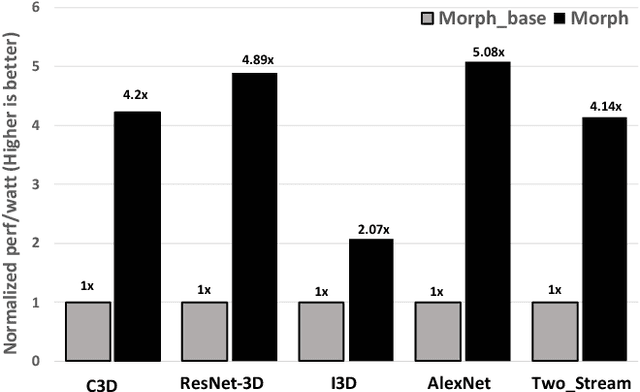
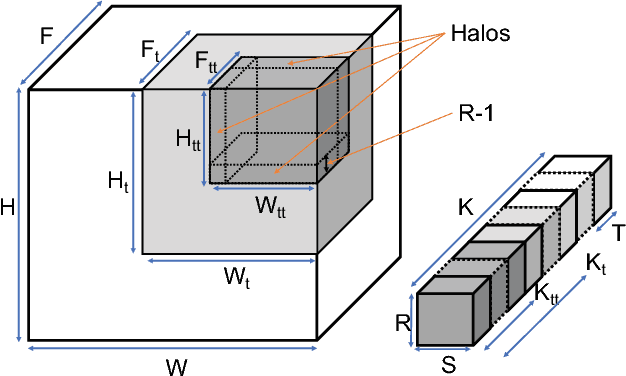
The past several years have seen both an explosion in the use of Convolutional Neural Networks (CNNs) and the design of accelerators to make CNN inference practical. In the architecture community, the lion share of effort has targeted CNN inference for image recognition. The closely related problem of video recognition has received far less attention as an accelerator target. This is surprising, as video recognition is more computationally intensive than image recognition, and video traffic is predicted to be the majority of internet traffic in the coming years. This paper fills the gap between algorithmic and hardware advances for video recognition by providing a design space exploration and flexible architecture for accelerating 3D Convolutional Neural Networks (3D CNNs) - the core kernel in modern video understanding. When compared to (2D) CNNs used for image recognition, efficiently accelerating 3D CNNs poses a significant engineering challenge due to their large (and variable over time) memory footprint and higher dimensionality. To address these challenges, we design a novel accelerator, called Morph, that can adaptively support different spatial and temporal tiling strategies depending on the needs of each layer of each target 3D CNN. We codesign a software infrastructure alongside the Morph hardware to find good-fit parameters to control the hardware. Evaluated on state-of-the-art 3D CNNs, Morph achieves up to 3.4x (2.5x average) reduction in energy consumption and improves performance/watt by up to 5.1x (4x average) compared to a baseline 3D CNN accelerator, with an area overhead of 5%. Morph further achieves a 15.9x average energy reduction on 3D CNNs when compared to Eyeriss.
UCNN: Exploiting Computational Reuse in Deep Neural Networks via Weight Repetition
Apr 18, 2018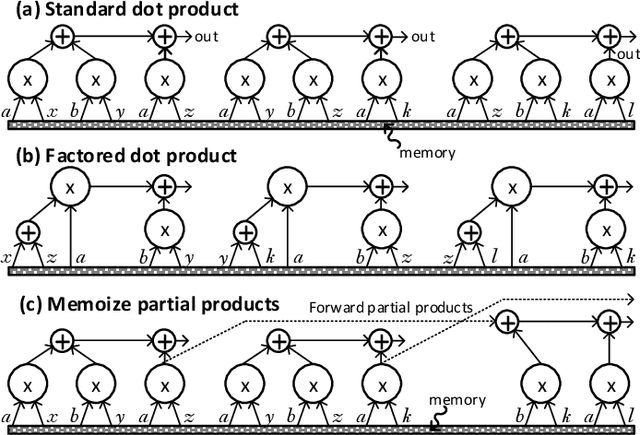
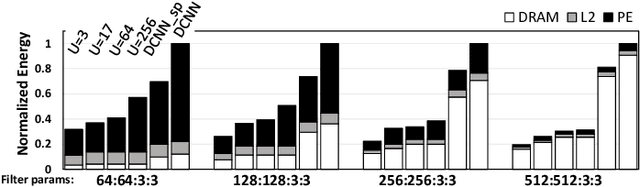
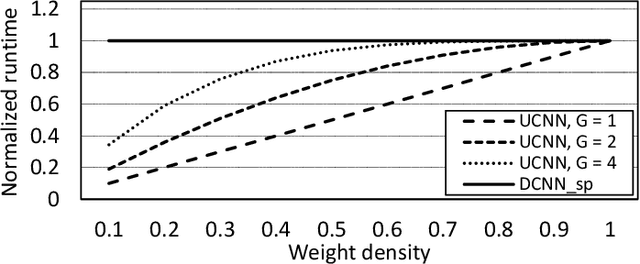
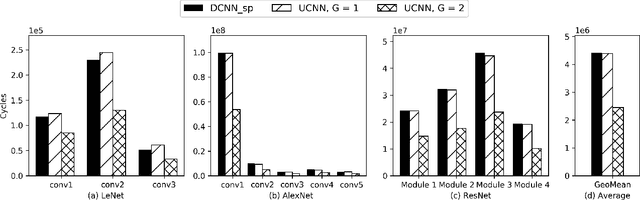
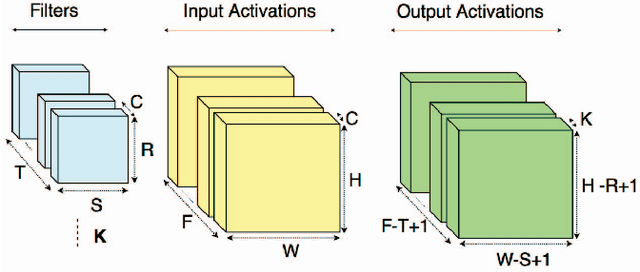
Convolutional Neural Networks (CNNs) have begun to permeate all corners of electronic society (from voice recognition to scene generation) due to their high accuracy and machine efficiency per operation. At their core, CNN computations are made up of multi-dimensional dot products between weight and input vectors. This paper studies how weight repetition ---when the same weight occurs multiple times in or across weight vectors--- can be exploited to save energy and improve performance during CNN inference. This generalizes a popular line of work to improve efficiency from CNN weight sparsity, as reducing computation due to repeated zero weights is a special case of reducing computation due to repeated weights. To exploit weight repetition, this paper proposes a new CNN accelerator called the Unique Weight CNN Accelerator (UCNN). UCNN uses weight repetition to reuse CNN sub-computations (e.g., dot products) and to reduce CNN model size when stored in off-chip DRAM ---both of which save energy. UCNN further improves performance by exploiting sparsity in weights. We evaluate UCNN with an accelerator-level cycle and energy model and with an RTL implementation of the UCNN processing element. On three contemporary CNNs, UCNN improves throughput-normalized energy consumption by 1.2x - 4x, relative to a similarly provisioned baseline accelerator that uses Eyeriss-style sparsity optimizations. At the same time, the UCNN processing element adds only 17-24% area overhead relative to the same baseline.