 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI+HW 2035: Shaping the Next Decade
Mar 05, 2026Artificial intelligence (AI) and hardware (HW) are advancing at unprecedented rates, yet their trajectories have become inseparably intertwined. The global research community lacks a cohesive, long-term vision to strategically coordinate the development of AI and HW. This fragmentation constrains progress toward holistic, sustainable, and adaptive AI systems capable of learning, reasoning, and operating efficiently across cloud, edge, and physical environments. The future of AI depends not only on scaling intelligence, but on scaling efficiency, achieving exponential gains in intelligence per joule, rather than unbounded compute consumption. Addressing this grand challenge requires rethinking the entire computing stack. This vision paper lays out a 10-year roadmap for AI+HW co-design and co-development, spanning algorithms, architectures, systems, and sustainability. We articulate key insights that redefine scaling around energy efficiency, system-level integration, and cross-layer optimization. We identify key challenges and opportunities, candidly assess potential obstacles and pitfalls, and propose integrated solutions grounded in algorithmic innovation, hardware advances, and software abstraction. Looking ahead, we define what success means in 10 years: achieving a 1000x improvement in efficiency for AI training and inference; enabling energy-aware, self-optimizing systems that seamlessly span cloud, edge, and physical AI; democratizing access to advanced AI infrastructure; and embedding human-centric principles into the design of intelligent systems. Finally, we outline concrete action items for academia, industry, government, and the broader community, calling for coordinated national initiatives, shared infrastructure, workforce development, cross-agency collaboration, and sustained public-private partnerships to ensure that AI+HW co-design becomes a unifying long-term mission.
FedERL: Federated Efficient and Robust Learning for Common Corruptions
Aug 24, 2025Federated learning (FL) accelerates the deployment of deep learning models on edge devices while preserving data privacy. However, FL systems face challenges due to client-side constraints on computational resources, and from a lack of robustness to common corruptions such as noise, blur, and weather effects. Existing robust training methods are computationally expensive and unsuitable for resource-constrained clients. We propose FedERL, federated efficient and robust learning, as the first work to explicitly address corruption robustness under time and energy constraints on the client side. At its core, FedERL employs a novel data-agnostic robust training (DART) method on the server to enhance robustness without access to the training data. In doing so, FedERL ensures zero robustness overhead for clients. Extensive experiments demonstrate FedERL's ability to handle common corruptions at a fraction of the time and energy cost of traditional robust training methods. In scenarios with limited time and energy budgets, FedERL surpasses the performance of traditional robust training, establishing it as a practical and scalable solution for real-world FL applications.
Growing Efficient Accurate and Robust Neural Networks on the Edge
Oct 10, 2024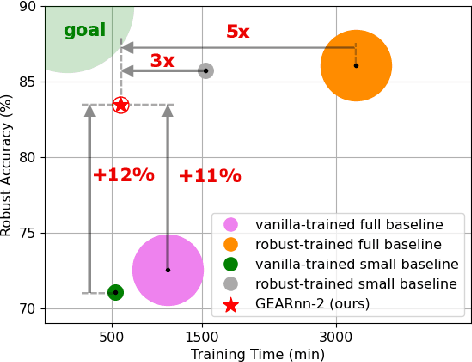
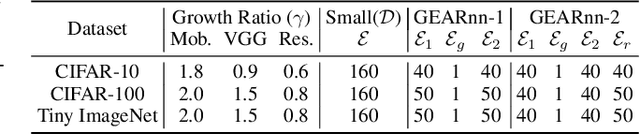
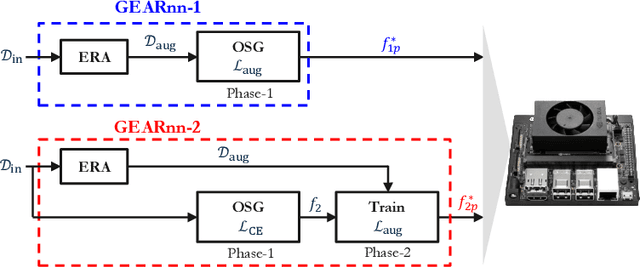
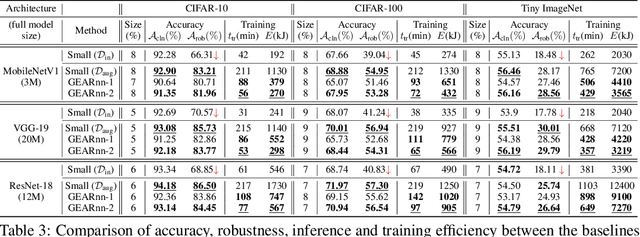
The ubiquitous deployment of deep learning systems on resource-constrained Edge devices is hindered by their high computational complexity coupled with their fragility to out-of-distribution (OOD) data, especially to naturally occurring common corruptions. Current solutions rely on the Cloud to train and compress models before deploying to the Edge. This incurs high energy and latency costs in transmitting locally acquired field data to the Cloud while also raising privacy concerns. We propose GEARnn (Growing Efficient, Accurate, and Robust neural networks) to grow and train robust networks in-situ, i.e., completely on the Edge device. Starting with a low-complexity initial backbone network, GEARnn employs One-Shot Growth (OSG) to grow a network satisfying the memory constraints of the Edge device using clean data, and robustifies the network using Efficient Robust Augmentation (ERA) to obtain the final network. We demonstrate results on a NVIDIA Jetson Xavier NX, and analyze the trade-offs between accuracy, robustness, model size, energy consumption, and training time. Our results demonstrate the construction of efficient, accurate, and robust networks entirely on an Edge device.
DBQ: A Differentiable Branch Quantizer for Lightweight Deep Neural Networks
Jul 19, 2020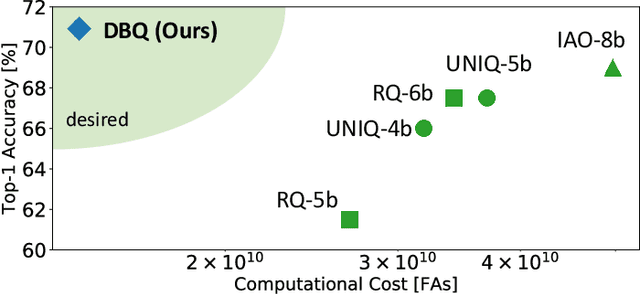
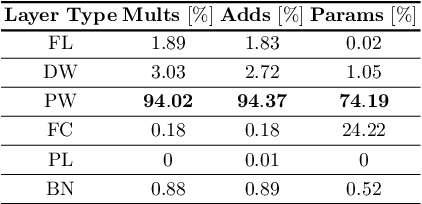

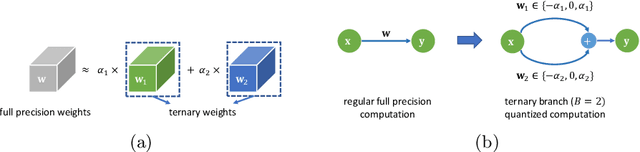
Deep neural networks have achieved state-of-the art performance on various computer vision tasks. However, their deployment on resource-constrained devices has been hindered due to their high computational and storage complexity. While various complexity reduction techniques, such as lightweight network architecture design and parameter quantization, have been successful in reducing the cost of implementing these networks, these methods have often been considered orthogonal. In reality, existing quantization techniques fail to replicate their success on lightweight architectures such as MobileNet. To this end, we present a novel fully differentiable non-uniform quantizer that can be seamlessly mapped onto efficient ternary-based dot product engines. We conduct comprehensive experiments on CIFAR-10, ImageNet, and Visual Wake Words datasets. The proposed quantizer (DBQ) successfully tackles the daunting task of aggressively quantizing lightweight networks such as MobileNetV1, MobileNetV2, and ShuffleNetV2. DBQ achieves state-of-the art results with minimal training overhead and provides the best (pareto-optimal) accuracy-complexity trade-off.
HarDNN: Feature Map Vulnerability Evaluation in CNNs
Feb 25, 2020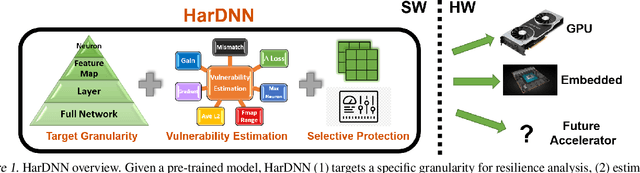
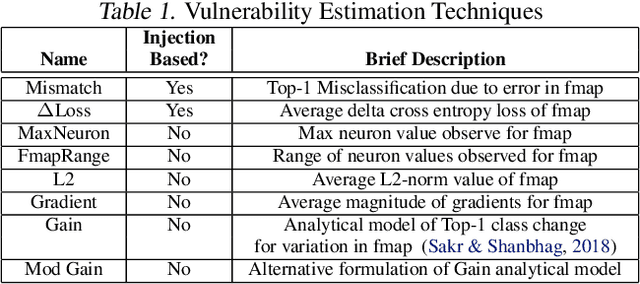
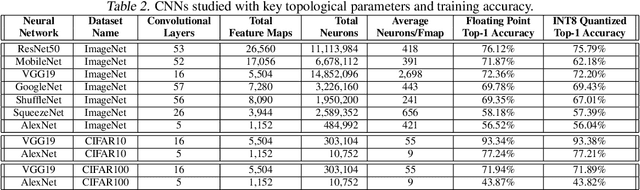
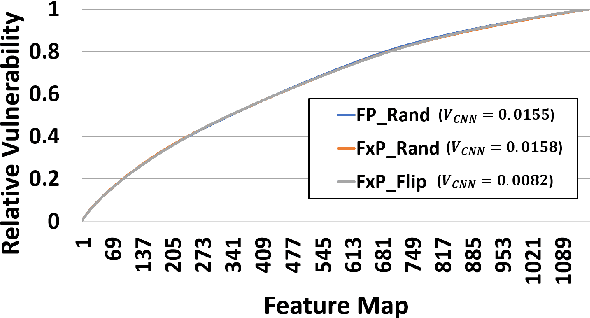
As Convolutional Neural Networks (CNNs) are increasingly being employed in safety-critical applications, it is important that they behave reliably in the face of hardware errors. Transient hardware errors may percolate undesirable state during execution, resulting in software-manifested errors which can adversely affect high-level decision making. This paper presents HarDNN, a software-directed approach to identify vulnerable computations during a CNN inference and selectively protect them based on their propensity towards corrupting the inference output in the presence of a hardware error. We show that HarDNN can accurately estimate relative vulnerability of a feature map (fmap) in CNNs using a statistical error injection campaign, and explore heuristics for fast vulnerability assessment. Based on these results, we analyze the tradeoff between error coverage and computational overhead that the system designers can use to employ selective protection. Results show that the improvement in resilience for the added computation is superlinear with HarDNN. For example, HarDNN improves SqueezeNet's resilience by 10x with just 30% additional computations.
Accumulation Bit-Width Scaling For Ultra-Low Precision Training Of Deep Networks
Jan 19, 2019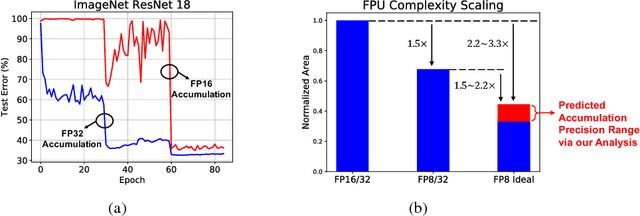
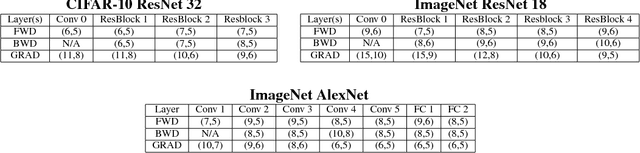
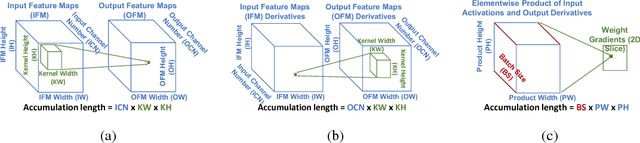
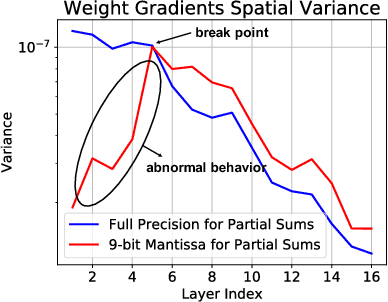
Efforts to reduce the numerical precision of computations in deep learning training have yielded systems that aggressively quantize weights and activations, yet employ wide high-precision accumulators for partial sums in inner-product operations to preserve the quality of convergence. The absence of any framework to analyze the precision requirements of partial sum accumulations results in conservative design choices. This imposes an upper-bound on the reduction of complexity of multiply-accumulate units. We present a statistical approach to analyze the impact of reduced accumulation precision on deep learning training. Observing that a bad choice for accumulation precision results in loss of information that manifests itself as a reduction in variance in an ensemble of partial sums, we derive a set of equations that relate this variance to the length of accumulation and the minimum number of bits needed for accumulation. We apply our analysis to three benchmark networks: CIFAR-10 ResNet 32, ImageNet ResNet 18 and ImageNet AlexNet. In each case, with accumulation precision set in accordance with our proposed equations, the networks successfully converge to the single precision floating-point baseline. We also show that reducing accumulation precision further degrades the quality of the trained network, proving that our equations produce tight bounds. Overall this analysis enables precise tailoring of computation hardware to the application, yielding area- and power-optimal systems.
Per-Tensor Fixed-Point Quantization of the Back-Propagation Algorithm
Dec 31, 2018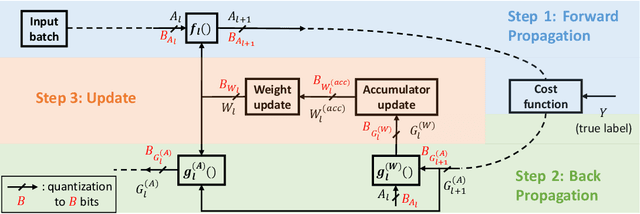
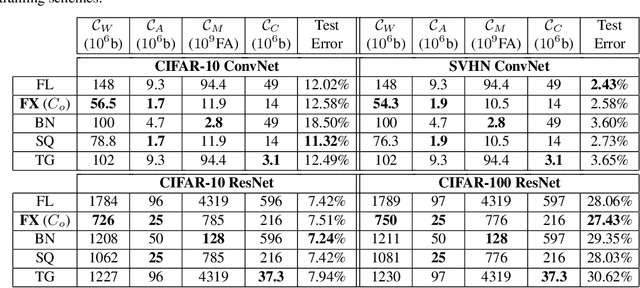
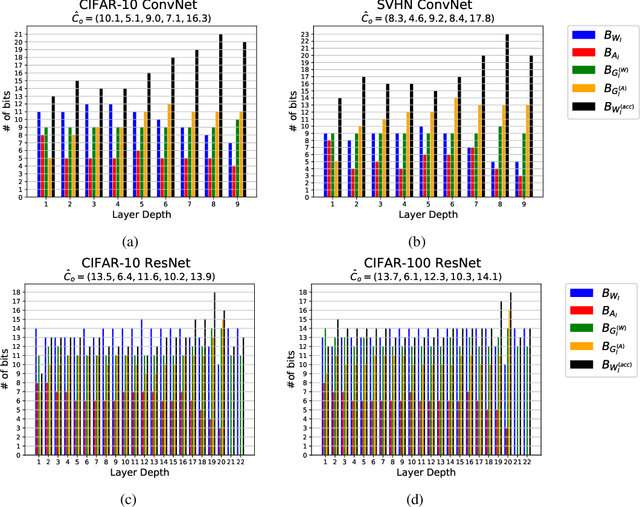
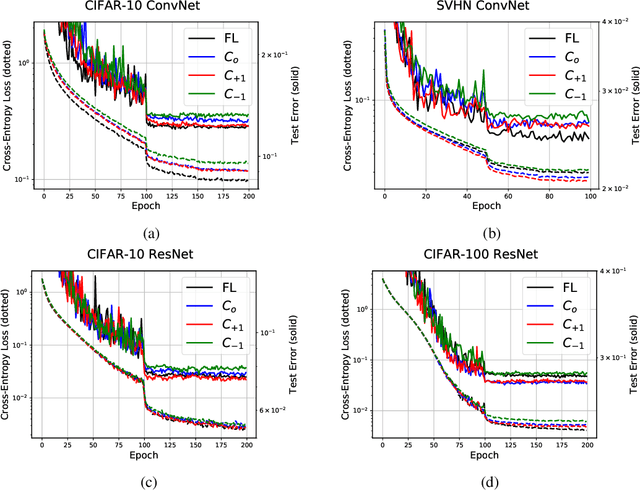
The high computational and parameter complexity of neural networks makes their training very slow and difficult to deploy on energy and storage-constrained computing systems. Many network complexity reduction techniques have been proposed including fixed-point implementation. However, a systematic approach for designing full fixed-point training and inference of deep neural networks remains elusive. We describe a precision assignment methodology for neural network training in which all network parameters, i.e., activations and weights in the feedforward path, gradients and weight accumulators in the feedback path, are assigned close to minimal precision. The precision assignment is derived analytically and enables tracking the convergence behavior of the full precision training, known to converge a priori. Thus, our work leads to a systematic methodology of determining suitable precision for fixed-point training. The near optimality (minimality) of the resulting precision assignment is validated empirically for four networks on the CIFAR-10, CIFAR-100, and SVHN datasets. The complexity reduction arising from our approach is compared with other fixed-point neural network designs.
Understanding the Energy and Precision Requirements for Online Learning
Aug 26, 2016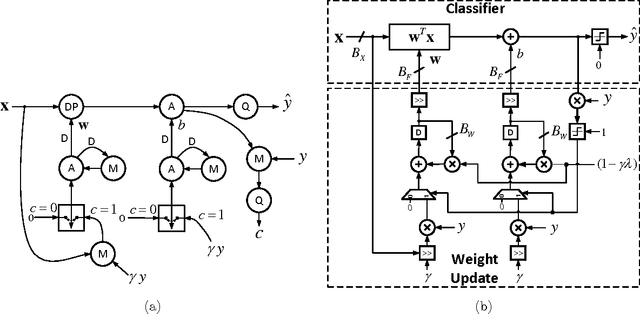
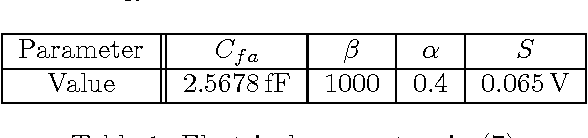
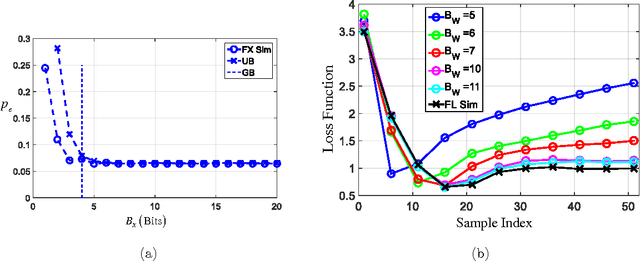
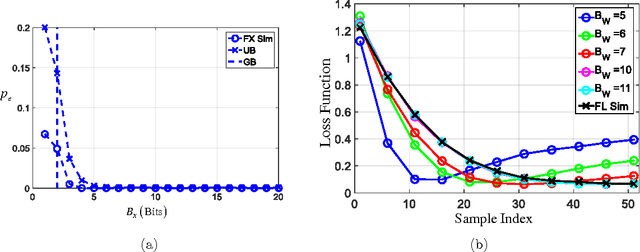
It is well-known that the precision of data, hyperparameters, and internal representations employed in learning systems directly impacts its energy, throughput, and latency. The precision requirements for the training algorithm are also important for systems that learn on-the-fly. Prior work has shown that the data and hyperparameters can be quantized heavily without incurring much penalty in classification accuracy when compared to floating point implementations. These works suffer from two key limitations. First, they assume uniform precision for the classifier and for the training algorithm and thus miss out on the opportunity to further reduce precision. Second, prior works are empirical studies. In this article, we overcome both these limitations by deriving analytical lower bounds on the precision requirements of the commonly employed stochastic gradient descent (SGD) on-line learning algorithm in the specific context of a support vector machine (SVM). Lower bounds on the data precision are derived in terms of the the desired classification accuracy and precision of the hyperparameters used in the classifier. Additionally, lower bounds on the hyperparameter precision in the SGD training algorithm are obtained. These bounds are validated using both synthetic and the UCI breast cancer dataset. Additionally, the impact of these precisions on the energy consumption of a fixed-point SVM with on-line training is studied.
Error-Resilient Machine Learning in Near Threshold Voltage via Classifier Ensemble
Jul 03, 2016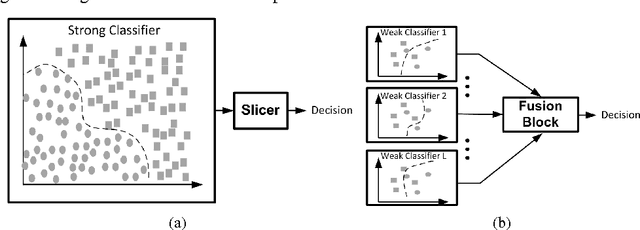
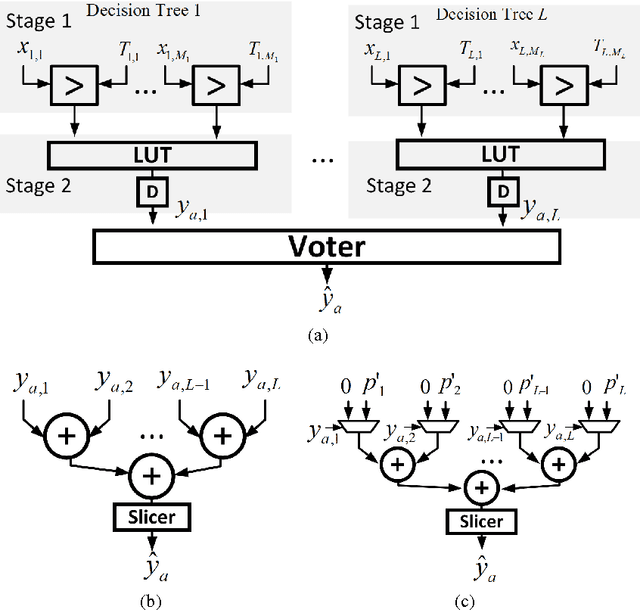
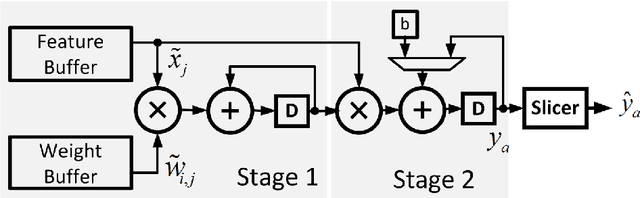
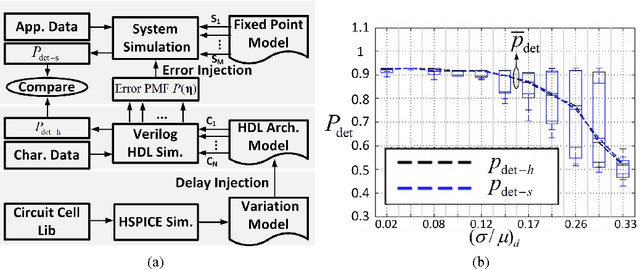
In this paper, we present the design of error-resilient machine learning architectures by employing a distributed machine learning framework referred to as classifier ensemble (CE). CE combines several simple classifiers to obtain a strong one. In contrast, centralized machine learning employs a single complex block. We compare the random forest (RF) and the support vector machine (SVM), which are representative techniques from the CE and centralized frameworks, respectively. Employing the dataset from UCI machine learning repository and architectural-level error models in a commercial 45 nm CMOS process, it is demonstrated that RF-based architectures are significantly more robust than SVM architectures in presence of timing errors due to process variations in near-threshold voltage (NTV) regions (0.3 V - 0.7 V). In particular, the RF architecture exhibits a detection accuracy (P_{det}) that varies by 3.2% while maintaining a median P_{det} > 0.9 at a gate level delay variation of 28.9% . In comparison, SVM exhibits a P_{det} that varies by 16.8%. Additionally, we propose an error weighted voting technique that incorporates the timing error statistics of the NTV circuit fabric to further enhance robustness. Simulation results confirm that the error weighted voting achieves a P_{det} that varies by only 1.4%, which is 12X lower compared to SVM.