 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSAM: Singular Subspace Alignment for Merging Multimodal Large Language Models
Mar 23, 2026Multimodal large language models (MLLMs) achieve strong performance by jointly processing inputs from multiple modalities, such as vision, audio, and language. However, building such models or extending them to new modalities often requires large paired datasets and substantial computational resources. Since many pretrained MLLMs (e.g., vision-language or audio-language) are publicly available, we ask whether we can merge them into a single MLLM that can handle multiple modalities? Merging MLLMs with different input modalities remains challenging, partly because of differences in the learned representations and interference between their parameter spaces. To address these challenges, we propose Singular Subspace Alignment and Merging (SSAM), a training-free model merging framework that unifies independently trained specialist MLLMs into a single model capable of handling any combination of input modalities. SSAM maintains modality-specific parameter updates separately and identifies a shared low-rank subspace for language-related parameter updates, aligns them within this subspace, and merges them to preserve complementary knowledge while minimizing parameter interference. Without using any multimodal training data, SSAM achieves state-of-the-art performance across four datasets, surpassing prior training-free merging methods and even jointly trained multimodal models. These results demonstrate that aligning models in parameter space provides a scalable and resource-efficient alternative to conventional joint multimodal training.
Hierarchical and Multimodal Data for Daily Activity Understanding
Apr 24, 2025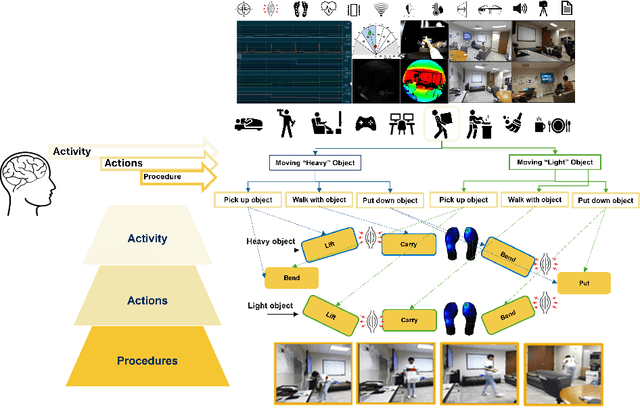


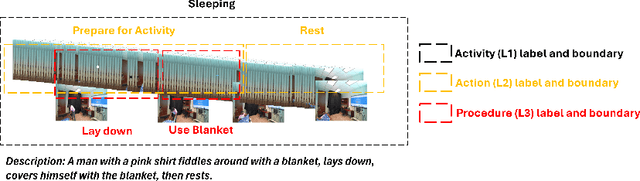
Daily Activity Recordings for Artificial Intelligence (DARai, pronounced "Dahr-ree") is a multimodal, hierarchically annotated dataset constructed to understand human activities in real-world settings. DARai consists of continuous scripted and unscripted recordings of 50 participants in 10 different environments, totaling over 200 hours of data from 20 sensors including multiple camera views, depth and radar sensors, wearable inertial measurement units (IMUs), electromyography (EMG), insole pressure sensors, biomonitor sensors, and gaze tracker. To capture the complexity in human activities, DARai is annotated at three levels of hierarchy: (i) high-level activities (L1) that are independent tasks, (ii) lower-level actions (L2) that are patterns shared between activities, and (iii) fine-grained procedures (L3) that detail the exact execution steps for actions. The dataset annotations and recordings are designed so that 22.7% of L2 actions are shared between L1 activities and 14.2% of L3 procedures are shared between L2 actions. The overlap and unscripted nature of DARai allows counterfactual activities in the dataset. Experiments with various machine learning models showcase the value of DARai in uncovering important challenges in human-centered applications. Specifically, we conduct unimodal and multimodal sensor fusion experiments for recognition, temporal localization, and future action anticipation across all hierarchical annotation levels. To highlight the limitations of individual sensors, we also conduct domain-variant experiments that are enabled by DARai's multi-sensor and counterfactual activity design setup. The code, documentation, and dataset are available at the dedicated DARai website: https://alregib.ece.gatech.edu/software-and-datasets/darai-daily-activity-recordings-for-artificial-intelligence-and-machine-learning/
U2A: Unified Unimodal Adaptation for Robust and Efficient Multimodal Learning
Jan 29, 2025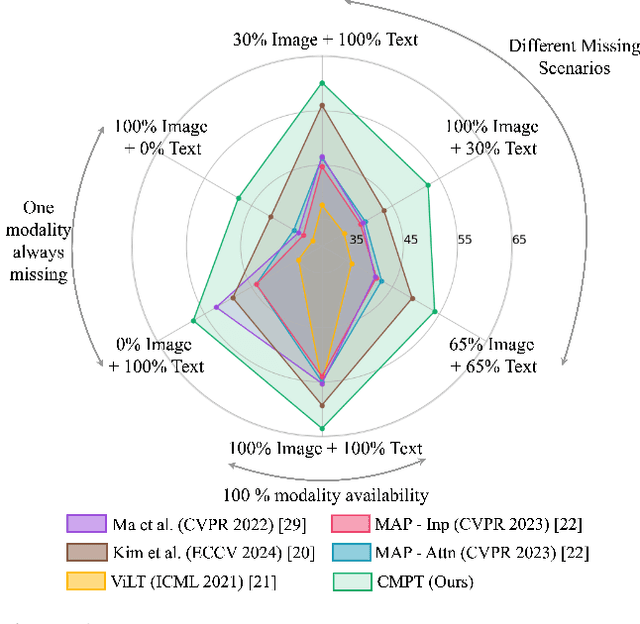
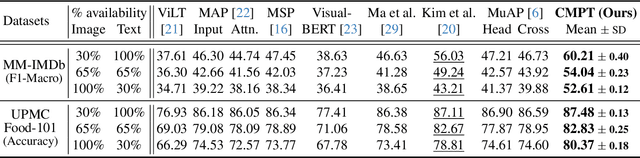
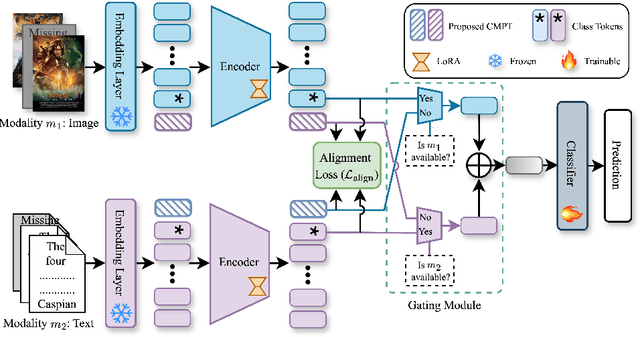
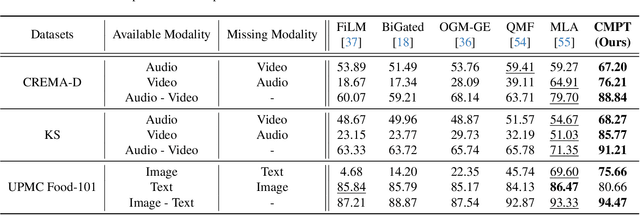
Multimodal learning often relies on designing new models and complex training strategies to achieve optimal performance. We present Unified Unimodal Adaptation (U2A), which jointly fine-tunes pretrained unimodal encoders using low-rank adaptation (LoRA) for various multimodal tasks. Our method significantly reduces the number of learnable parameters and eliminates the need for complex training strategies, such as alternating training, gradient modifications, or unimodal fine-tuning. To address missing modalities during both training and testing, we introduce Mask Tokens (MT), which generate missing modality features from available modalities using a single token per modality. This simplifies the process, removing the need for specialized feature estimation or prompt-tuning methods. Our evaluation demonstrates that U2A matches or outperforms state-of-the-art methods in both complete and missing modality settings, showcasing strong performance and robustness across various modalities, tasks, and datasets. We also analyze and report the effectiveness of Mask Tokens in different missing modality scenarios. Overall, our method provides a robust, flexible, and efficient solution for multimodal learning, with minimal computational overhead.
MMP: Towards Robust Multi-Modal Learning with Masked Modality Projection
Oct 03, 2024



Multimodal learning seeks to combine data from multiple input sources to enhance the performance of different downstream tasks. In real-world scenarios, performance can degrade substantially if some input modalities are missing. Existing methods that can handle missing modalities involve custom training or adaptation steps for each input modality combination. These approaches are either tied to specific modalities or become computationally expensive as the number of input modalities increases. In this paper, we propose Masked Modality Projection (MMP), a method designed to train a single model that is robust to any missing modality scenario. We achieve this by randomly masking a subset of modalities during training and learning to project available input modalities to estimate the tokens for the masked modalities. This approach enables the model to effectively learn to leverage the information from the available modalities to compensate for the missing ones, enhancing missing modality robustness. We conduct a series of experiments with various baseline models and datasets to assess the effectiveness of this strategy. Experiments demonstrate that our approach improves robustness to different missing modality scenarios, outperforming existing methods designed for missing modalities or specific modality combinations.
Compressing GANs using Knowledge Distillation
Feb 01, 2019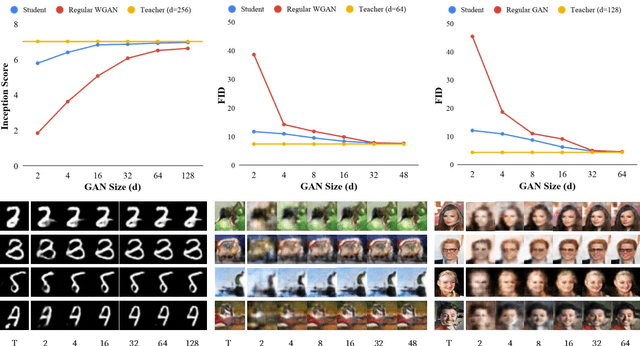
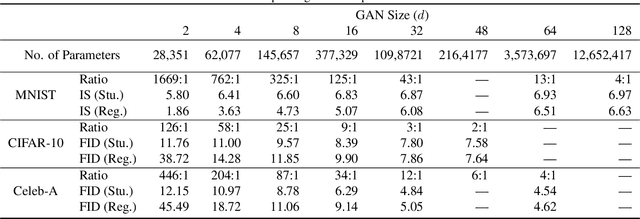
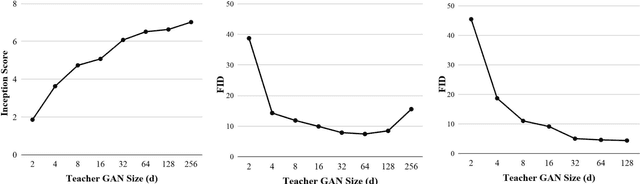
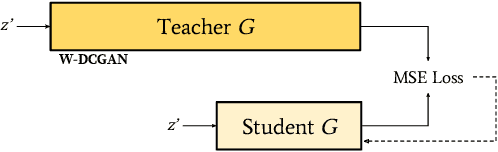
Generative Adversarial Networks (GANs) have been used in several machine learning tasks such as domain transfer, super resolution, and synthetic data generation. State-of-the-art GANs often use tens of millions of parameters, making them expensive to deploy for applications in low SWAP (size, weight, and power) hardware, such as mobile devices, and for applications with real time capabilities. There has been no work found to reduce the number of parameters used in GANs. Therefore, we propose a method to compress GANs using knowledge distillation techniques, in which a smaller "student" GAN learns to mimic a larger "teacher" GAN. We show that the distillation methods used on MNIST, CIFAR-10, and Celeb-A datasets can compress teacher GANs at ratios of 1669:1, 58:1, and 87:1, respectively, while retaining the quality of the generated image. From our experiments, we observe a qualitative limit for GAN's compression. Moreover, we observe that, with a fixed parameter budget, compressed GANs outperform GANs trained using standard training methods. We conjecture that this is partially owing to the optimization landscape of over-parameterized GANs which allows efficient training using alternating gradient descent. Thus, training an over-parameterized GAN followed by our proposed compression scheme provides a high quality generative model with a small number of parameters.
Understanding the Energy and Precision Requirements for Online Learning
Aug 26, 2016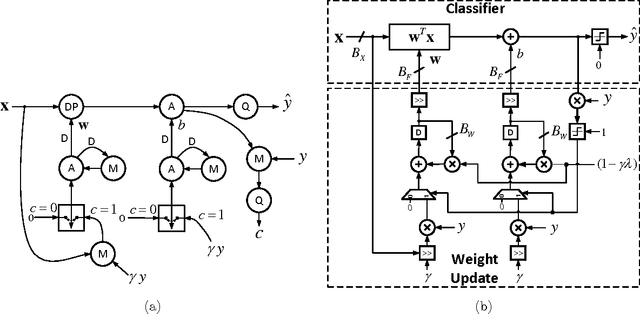
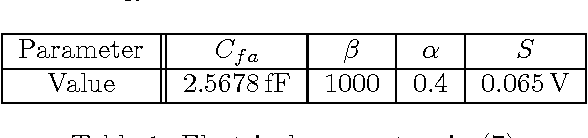
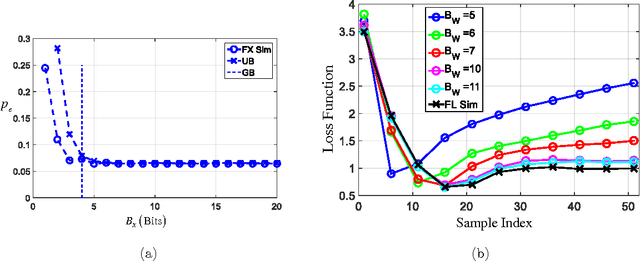
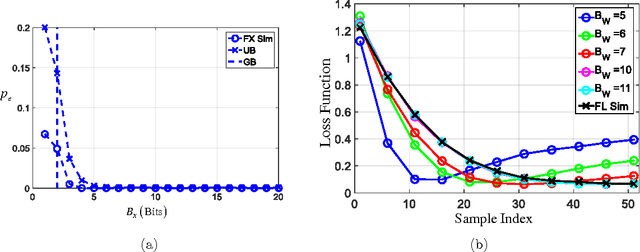
It is well-known that the precision of data, hyperparameters, and internal representations employed in learning systems directly impacts its energy, throughput, and latency. The precision requirements for the training algorithm are also important for systems that learn on-the-fly. Prior work has shown that the data and hyperparameters can be quantized heavily without incurring much penalty in classification accuracy when compared to floating point implementations. These works suffer from two key limitations. First, they assume uniform precision for the classifier and for the training algorithm and thus miss out on the opportunity to further reduce precision. Second, prior works are empirical studies. In this article, we overcome both these limitations by deriving analytical lower bounds on the precision requirements of the commonly employed stochastic gradient descent (SGD) on-line learning algorithm in the specific context of a support vector machine (SVM). Lower bounds on the data precision are derived in terms of the the desired classification accuracy and precision of the hyperparameters used in the classifier. Additionally, lower bounds on the hyperparameter precision in the SGD training algorithm are obtained. These bounds are validated using both synthetic and the UCI breast cancer dataset. Additionally, the impact of these precisions on the energy consumption of a fixed-point SVM with on-line training is studied.