 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU2A: Unified Unimodal Adaptation for Robust and Efficient Multimodal Learning
Jan 29, 2025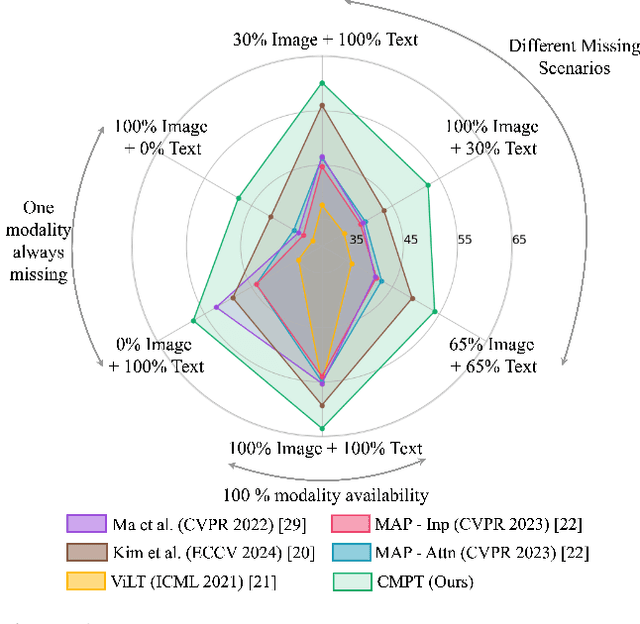
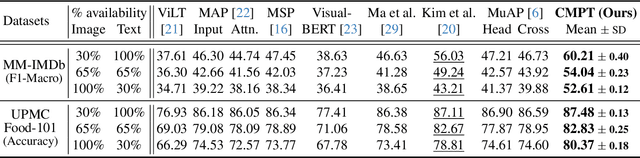
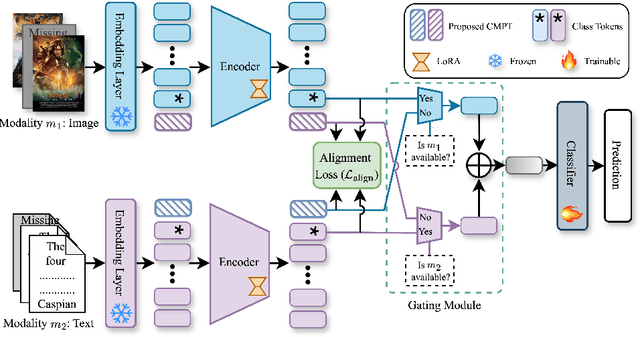
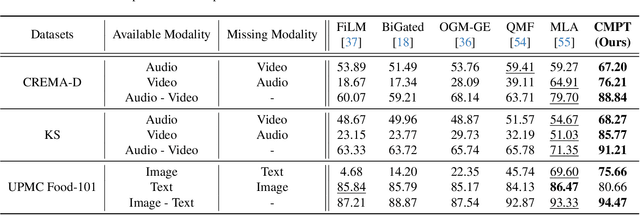
Multimodal learning often relies on designing new models and complex training strategies to achieve optimal performance. We present Unified Unimodal Adaptation (U2A), which jointly fine-tunes pretrained unimodal encoders using low-rank adaptation (LoRA) for various multimodal tasks. Our method significantly reduces the number of learnable parameters and eliminates the need for complex training strategies, such as alternating training, gradient modifications, or unimodal fine-tuning. To address missing modalities during both training and testing, we introduce Mask Tokens (MT), which generate missing modality features from available modalities using a single token per modality. This simplifies the process, removing the need for specialized feature estimation or prompt-tuning methods. Our evaluation demonstrates that U2A matches or outperforms state-of-the-art methods in both complete and missing modality settings, showcasing strong performance and robustness across various modalities, tasks, and datasets. We also analyze and report the effectiveness of Mask Tokens in different missing modality scenarios. Overall, our method provides a robust, flexible, and efficient solution for multimodal learning, with minimal computational overhead.
MMP: Towards Robust Multi-Modal Learning with Masked Modality Projection
Oct 03, 2024



Multimodal learning seeks to combine data from multiple input sources to enhance the performance of different downstream tasks. In real-world scenarios, performance can degrade substantially if some input modalities are missing. Existing methods that can handle missing modalities involve custom training or adaptation steps for each input modality combination. These approaches are either tied to specific modalities or become computationally expensive as the number of input modalities increases. In this paper, we propose Masked Modality Projection (MMP), a method designed to train a single model that is robust to any missing modality scenario. We achieve this by randomly masking a subset of modalities during training and learning to project available input modalities to estimate the tokens for the masked modalities. This approach enables the model to effectively learn to leverage the information from the available modalities to compensate for the missing ones, enhancing missing modality robustness. We conduct a series of experiments with various baseline models and datasets to assess the effectiveness of this strategy. Experiments demonstrate that our approach improves robustness to different missing modality scenarios, outperforming existing methods designed for missing modalities or specific modality combinations.