 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSAM: Singular Subspace Alignment for Merging Multimodal Large Language Models
Mar 23, 2026Multimodal large language models (MLLMs) achieve strong performance by jointly processing inputs from multiple modalities, such as vision, audio, and language. However, building such models or extending them to new modalities often requires large paired datasets and substantial computational resources. Since many pretrained MLLMs (e.g., vision-language or audio-language) are publicly available, we ask whether we can merge them into a single MLLM that can handle multiple modalities? Merging MLLMs with different input modalities remains challenging, partly because of differences in the learned representations and interference between their parameter spaces. To address these challenges, we propose Singular Subspace Alignment and Merging (SSAM), a training-free model merging framework that unifies independently trained specialist MLLMs into a single model capable of handling any combination of input modalities. SSAM maintains modality-specific parameter updates separately and identifies a shared low-rank subspace for language-related parameter updates, aligns them within this subspace, and merges them to preserve complementary knowledge while minimizing parameter interference. Without using any multimodal training data, SSAM achieves state-of-the-art performance across four datasets, surpassing prior training-free merging methods and even jointly trained multimodal models. These results demonstrate that aligning models in parameter space provides a scalable and resource-efficient alternative to conventional joint multimodal training.
DualSwinFusionSeg: Multimodal Martian Landslide Segmentation via Dual Swin Transformer with Multi-Scale Fusion and UNet++
Mar 14, 2026Automated segmentation of Martian landslides, particularly in tectonically active regions such as Valles Marineris,is important for planetary geology, hazard assessment, and future robotic exploration. However, detecting landslides from planetary imagery is challenging due to the heterogeneous nature of available sensing modalities and the limited number of labeled samples. Each observation combines RGB imagery with geophysical measurements such as digital elevation models, slope maps, thermal inertia, and contextual grayscale imagery, which differ significantly in resolution and statistical properties. To address these challenges, we propose DualSwinFusionSeg, a multimodal segmentation architecture that separates modality-specific feature extraction and performs multi-scale cross-modal fusion. The model employs two parallel Swin Transformer V2 encoders to independently process RGB and auxiliary geophysical inputs, producing hierarchical feature representations. Corresponding features from the two streams are fused at multiple scales and decoded using a UNet++ decoder with dense nested skip connections to preserve fine boundary details. Extensive ablation studies evaluate modality contributions, loss functions, decoder architectures, and fusion strategies. Experiments on the MMLSv2 dataset from the PBVS 2026 Mars-LS Challenge show that modality-specific encoders and simple concatenation-based fusion improve segmentation accuracy under limited training data. The final model achieves 0.867 mIoU and 0.905 F1 on the development benchmark and 0.783 mIoU on the held-out test set, demonstrating strong performance for multimodal planetary surface segmentation.
U2A: Unified Unimodal Adaptation for Robust and Efficient Multimodal Learning
Jan 29, 2025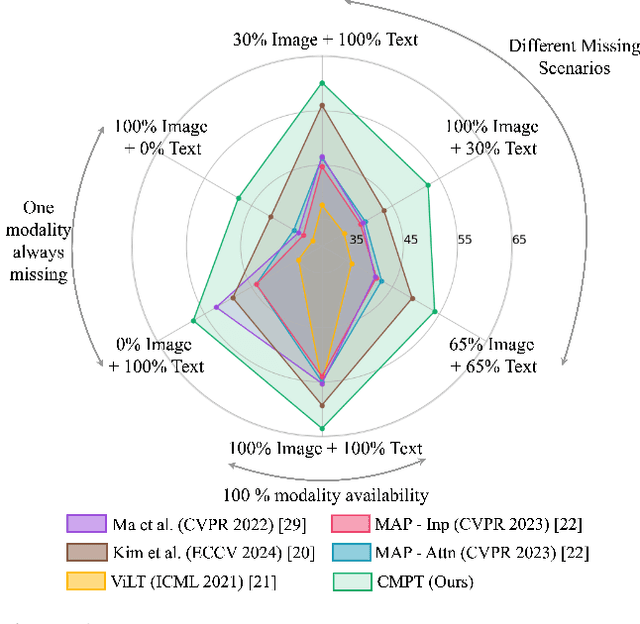
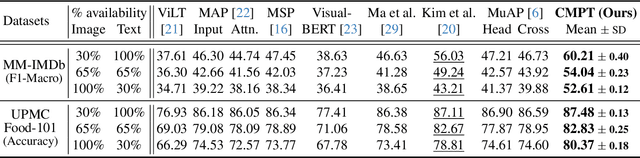
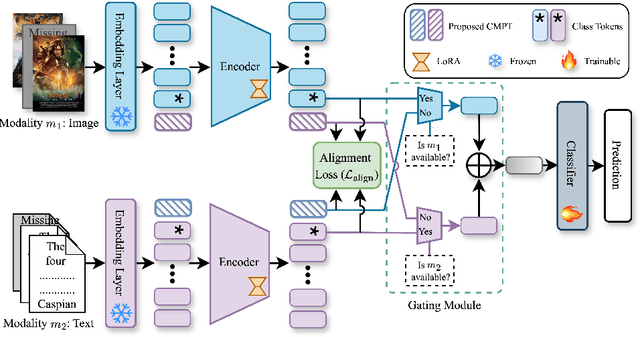
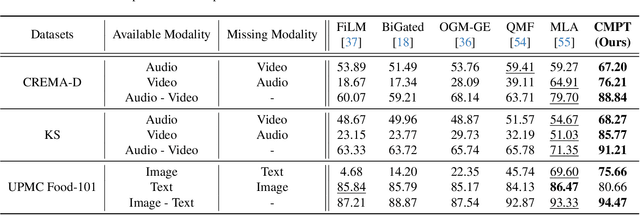
Multimodal learning often relies on designing new models and complex training strategies to achieve optimal performance. We present Unified Unimodal Adaptation (U2A), which jointly fine-tunes pretrained unimodal encoders using low-rank adaptation (LoRA) for various multimodal tasks. Our method significantly reduces the number of learnable parameters and eliminates the need for complex training strategies, such as alternating training, gradient modifications, or unimodal fine-tuning. To address missing modalities during both training and testing, we introduce Mask Tokens (MT), which generate missing modality features from available modalities using a single token per modality. This simplifies the process, removing the need for specialized feature estimation or prompt-tuning methods. Our evaluation demonstrates that U2A matches or outperforms state-of-the-art methods in both complete and missing modality settings, showcasing strong performance and robustness across various modalities, tasks, and datasets. We also analyze and report the effectiveness of Mask Tokens in different missing modality scenarios. Overall, our method provides a robust, flexible, and efficient solution for multimodal learning, with minimal computational overhead.
MMP: Towards Robust Multi-Modal Learning with Masked Modality Projection
Oct 03, 2024



Multimodal learning seeks to combine data from multiple input sources to enhance the performance of different downstream tasks. In real-world scenarios, performance can degrade substantially if some input modalities are missing. Existing methods that can handle missing modalities involve custom training or adaptation steps for each input modality combination. These approaches are either tied to specific modalities or become computationally expensive as the number of input modalities increases. In this paper, we propose Masked Modality Projection (MMP), a method designed to train a single model that is robust to any missing modality scenario. We achieve this by randomly masking a subset of modalities during training and learning to project available input modalities to estimate the tokens for the masked modalities. This approach enables the model to effectively learn to leverage the information from the available modalities to compensate for the missing ones, enhancing missing modality robustness. We conduct a series of experiments with various baseline models and datasets to assess the effectiveness of this strategy. Experiments demonstrate that our approach improves robustness to different missing modality scenarios, outperforming existing methods designed for missing modalities or specific modality combinations.
Model, Analyze, and Comprehend User Interactions and Various Attributes within a Social Media Platform
Mar 23, 2024How can we effectively model, analyze, and comprehend user interactions and various attributes within a social media platform based on post-comment relationship? In this study, we propose a novel graph-based approach to model and analyze user interactions within a social media platform based on post-comment relationship. We construct a user interaction graph from social media data and analyze it to gain insights into community dynamics, user behavior, and content preferences. Our investigation reveals that while 56.05% of the active users are strongly connected within the community, only 0.8% of them significantly contribute to its dynamics. Moreover, we observe temporal variations in community activity, with certain periods experiencing heightened engagement. Additionally, our findings highlight a correlation between user activity and popularity showing that more active users are generally more popular. Alongside these, a preference for positive and informative content is also observed where 82.41% users preferred positive and informative content. Overall, our study provides a comprehensive framework for understanding and managing online communities, leveraging graph-based techniques to gain valuable insights into user behavior and community dynamics.
Robust Multimodal Learning with Missing Modalities via Parameter-Efficient Adaptation
Oct 13, 2023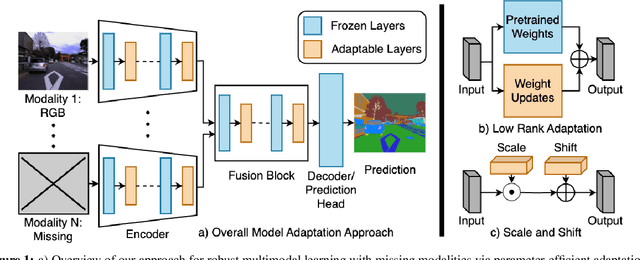
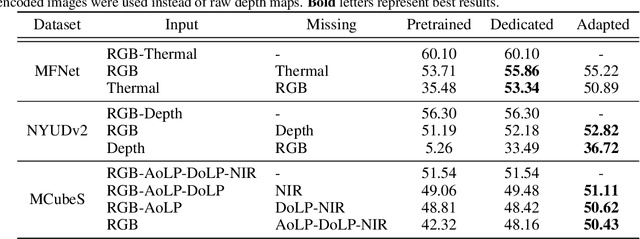
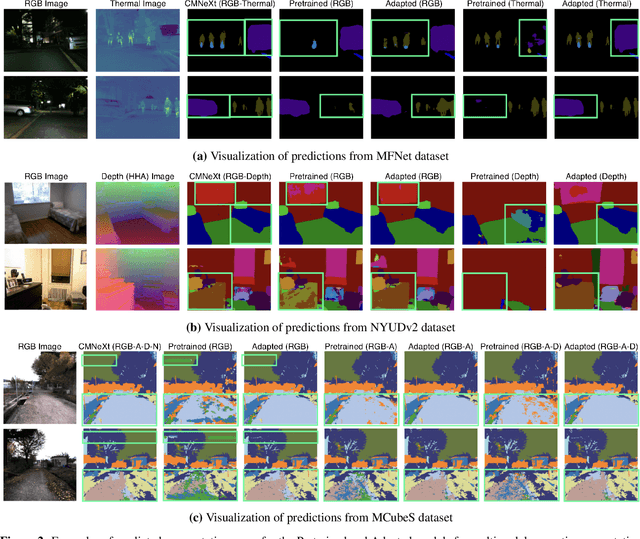
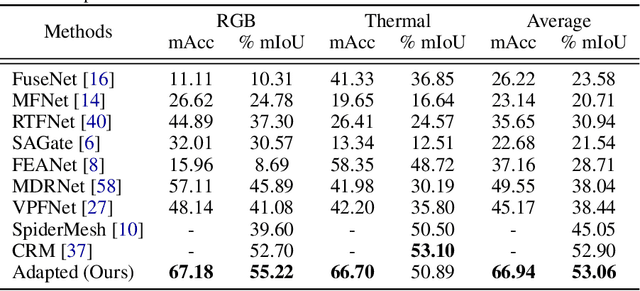
Multimodal learning seeks to utilize data from multiple sources to improve the overall performance of downstream tasks. It is desirable for redundancies in the data to make multimodal systems robust to missing or corrupted observations in some correlated modalities. However, we observe that the performance of several existing multimodal networks significantly deteriorates if one or multiple modalities are absent at test time. To enable robustness to missing modalities, we propose simple and parameter-efficient adaptation procedures for pretrained multimodal networks. In particular, we exploit low-rank adaptation and modulation of intermediate features to compensate for the missing modalities. We demonstrate that such adaptation can partially bridge performance drop due to missing modalities and outperform independent, dedicated networks trained for the available modality combinations in some cases. The proposed adaptation requires extremely small number of parameters (e.g., fewer than 0.7% of the total parameters in most experiments). We conduct a series of experiments to highlight the robustness of our proposed method using diverse datasets for RGB-thermal and RGB-Depth semantic segmentation, multimodal material segmentation, and multimodal sentiment analysis tasks. Our proposed method demonstrates versatility across various tasks and datasets, and outperforms existing methods for robust multimodal learning with missing modalities.
Multimodal Transformer for Material Segmentation
Sep 11, 2023Leveraging information across diverse modalities is known to enhance performance on multimodal segmentation tasks. However, effectively fusing information from different modalities remains challenging due to the unique characteristics of each modality. In this paper, we propose a novel fusion strategy that can effectively fuse information from different combinations of four different modalities: RGB, Angle of Linear Polarization (AoLP), Degree of Linear Polarization (DoLP) and Near-Infrared (NIR). We also propose a new model named Multi-Modal Segmentation Transformer (MMSFormer) that incorporates the proposed fusion strategy to perform multimodal material segmentation. MMSFormer achieves 52.05% mIoU outperforming the current state-of-the-art on Multimodal Material Segmentation (MCubeS) dataset. For instance, our method provides significant improvement in detecting gravel (+10.4%) and human (+9.1%) classes. Ablation studies show that different modules in the fusion block are crucial for overall model performance. Furthermore, our ablation studies also highlight the capacity of different input modalities to improve performance in the identification of different types of materials. The code and pretrained models will be made available at https://github.com/csiplab/MMSFormer.