 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning at the ImageNet Scale
Nov 25, 2021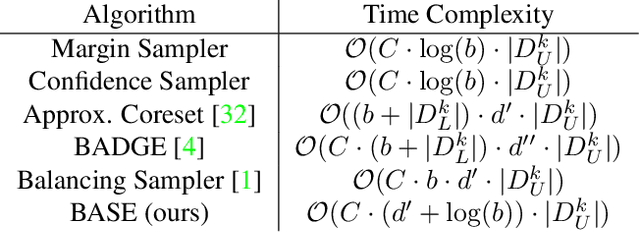
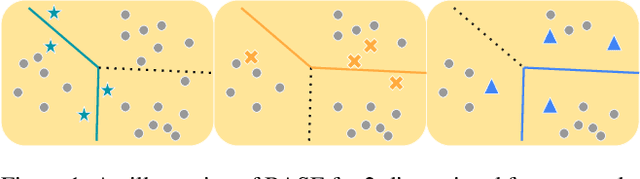

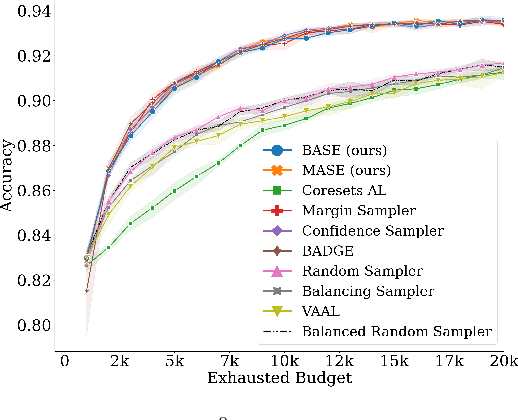
Active learning (AL) algorithms aim to identify an optimal subset of data for annotation, such that deep neural networks (DNN) can achieve better performance when trained on this labeled subset. AL is especially impactful in industrial scale settings where data labeling costs are high and practitioners use every tool at their disposal to improve model performance. The recent success of self-supervised pretraining (SSP) highlights the importance of harnessing abundant unlabeled data to boost model performance. By combining AL with SSP, we can make use of unlabeled data while simultaneously labeling and training on particularly informative samples. In this work, we study a combination of AL and SSP on ImageNet. We find that performance on small toy datasets -- the typical benchmark setting in the literature -- is not representative of performance on ImageNet due to the class imbalanced samples selected by an active learner. Among the existing baselines we test, popular AL algorithms across a variety of small and large scale settings fail to outperform random sampling. To remedy the class-imbalance problem, we propose Balanced Selection (BASE), a simple, scalable AL algorithm that outperforms random sampling consistently by selecting more balanced samples for annotation than existing methods. Our code is available at: https://github.com/zeyademam/active_learning .
Certifying Strategyproof Auction Networks
Jun 15, 2020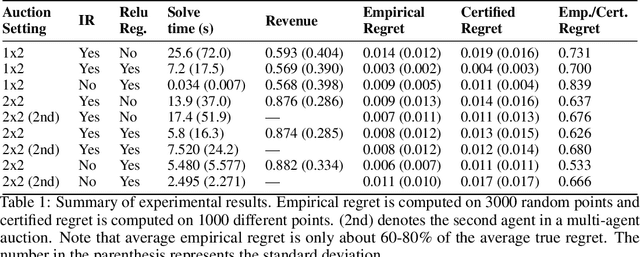
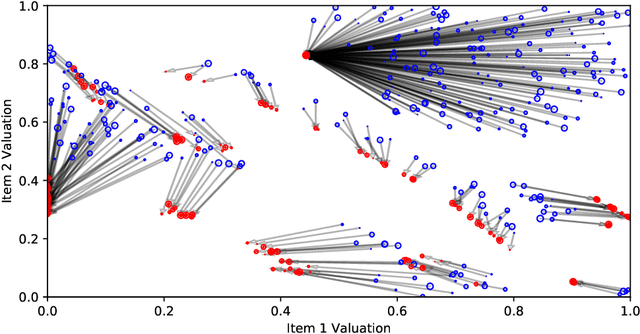
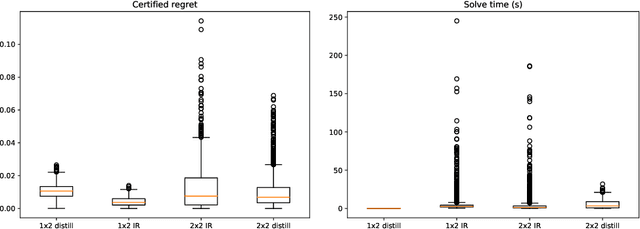

Optimal auctions maximize a seller's expected revenue subject to individual rationality and strategyproofness for the buyers. Myerson's seminal work in 1981 settled the case of auctioning a single item; however, subsequent decades of work have yielded little progress moving beyond a single item, leaving the design of revenue-maximizing auctions as a central open problem in the field of mechanism design. A recent thread of work in "differentiable economics" has used tools from modern deep learning to instead learn good mechanisms. We focus on the RegretNet architecture, which can represent auctions with arbitrary numbers of items and participants; it is trained to be empirically strategyproof, but the property is never exactly verified leaving potential loopholes for market participants to exploit. We propose ways to explicitly verify strategyproofness under a particular valuation profile using techniques from the neural network verification literature. Doing so requires making several modifications to the RegretNet architecture in order to represent it exactly in an integer program. We train our network and produce certificates in several settings, including settings for which the optimal strategyproof mechanism is not known.
Certified Defenses for Adversarial Patches
Mar 14, 2020
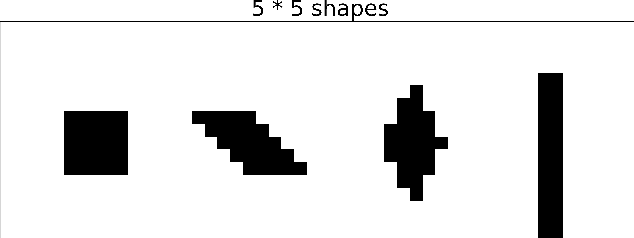

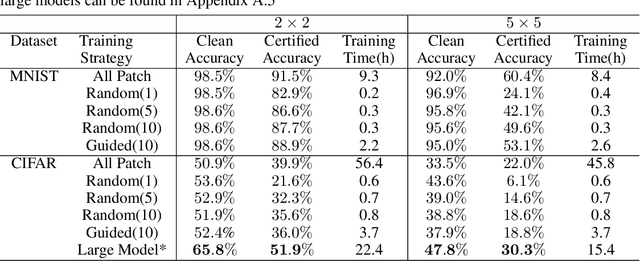
Adversarial patch attacks are among one of the most practical threat models against real-world computer vision systems. This paper studies certified and empirical defenses against patch attacks. We begin with a set of experiments showing that most existing defenses, which work by pre-processing input images to mitigate adversarial patches, are easily broken by simple white-box adversaries. Motivated by this finding, we propose the first certified defense against patch attacks, and propose faster methods for its training. Furthermore, we experiment with different patch shapes for testing, obtaining surprisingly good robustness transfer across shapes, and present preliminary results on certified defense against sparse attacks. Our complete implementation can be found on: https://github.com/Ping-C/certifiedpatchdefense.
WITCHcraft: Efficient PGD attacks with random step size
Nov 18, 2019



State-of-the-art adversarial attacks on neural networks use expensive iterative methods and numerous random restarts from different initial points. Iterative FGSM-based methods without restarts trade off performance for computational efficiency because they do not adequately explore the image space and are highly sensitive to the choice of step size. We propose a variant of Projected Gradient Descent (PGD) that uses a random step size to improve performance without resorting to expensive random restarts. Our method, Wide Iterative Stochastic crafting (WITCHcraft), achieves results superior to the classical PGD attack on the CIFAR-10 and MNIST data sets but without additional computational cost. This simple modification of PGD makes crafting attacks more economical, which is important in situations like adversarial training where attacks need to be crafted in real time.
Compressing GANs using Knowledge Distillation
Feb 01, 2019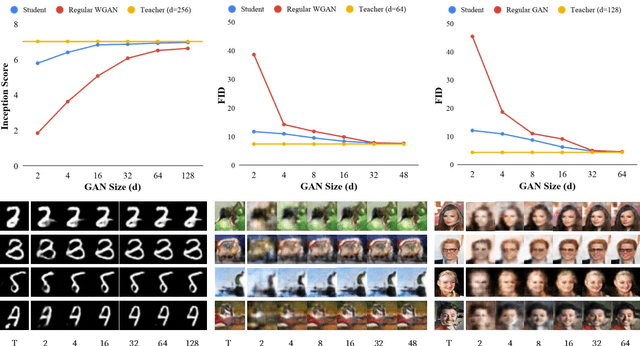
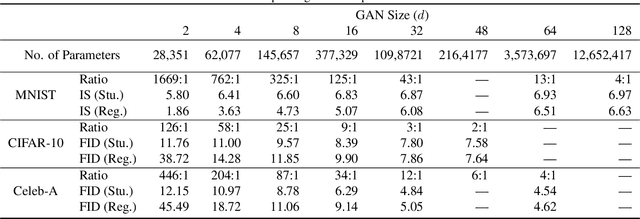
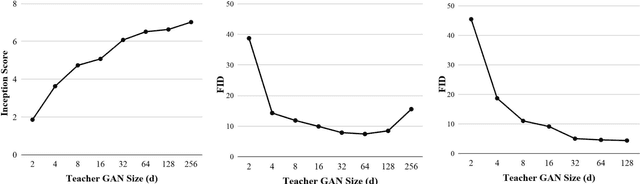
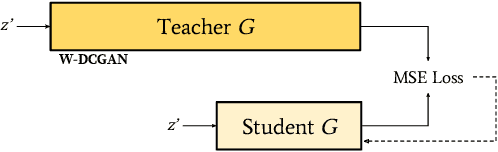
Generative Adversarial Networks (GANs) have been used in several machine learning tasks such as domain transfer, super resolution, and synthetic data generation. State-of-the-art GANs often use tens of millions of parameters, making them expensive to deploy for applications in low SWAP (size, weight, and power) hardware, such as mobile devices, and for applications with real time capabilities. There has been no work found to reduce the number of parameters used in GANs. Therefore, we propose a method to compress GANs using knowledge distillation techniques, in which a smaller "student" GAN learns to mimic a larger "teacher" GAN. We show that the distillation methods used on MNIST, CIFAR-10, and Celeb-A datasets can compress teacher GANs at ratios of 1669:1, 58:1, and 87:1, respectively, while retaining the quality of the generated image. From our experiments, we observe a qualitative limit for GAN's compression. Moreover, we observe that, with a fixed parameter budget, compressed GANs outperform GANs trained using standard training methods. We conjecture that this is partially owing to the optimization landscape of over-parameterized GANs which allows efficient training using alternating gradient descent. Thus, training an over-parameterized GAN followed by our proposed compression scheme provides a high quality generative model with a small number of parameters.