 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeumann eigenmaps for landmark embedding
Feb 10, 2025We present Neumann eigenmaps (NeuMaps), a novel approach for enhancing the standard diffusion map embedding using landmarks, i.e distinguished samples within the dataset. By interpreting these landmarks as a subgraph of the larger data graph, NeuMaps are obtained via the eigendecomposition of a renormalized Neumann Laplacian. We show that NeuMaps offer two key advantages: (1) they provide a computationally efficient embedding that accurately recovers the diffusion distance associated with the reflecting random walk on the subgraph, and (2) they naturally incorporate the Nystr\"om extension within the diffusion map framework through the discrete Neumann boundary condition. Through examples in digit classification and molecular dynamics, we demonstrate that NeuMaps not only improve upon existing landmark-based embedding methods but also enhance the stability of diffusion map embeddings to the removal of highly significant points.
Input layer regularization and automated regularization hyperparameter tuning for myelin water estimation using deep learning
Jan 30, 2025We propose a novel deep learning method which combines classical regularization with data augmentation for estimating myelin water fraction (MWF) in the brain via biexponential analysis. Our aim is to design an accurate deep learning technique for analysis of signals arising in magnetic resonance relaxometry. In particular, we study the biexponential model, one of the signal models used for MWF estimation. We greatly extend our previous work on \emph{input layer regularization (ILR)} in several ways. We now incorporate optimal regularization parameter selection via a dedicated neural network or generalized cross validation (GCV) on a signal-by-signal, or pixel-by-pixel, basis to form the augmented input signal, and now incorporate estimation of MWF, rather than just exponential time constants, into the analysis. On synthetically generated data, our proposed deep learning architecture outperformed both classical methods and a conventional multi-layer perceptron. On in vivo brain data, our architecture again outperformed other comparison methods, with GCV proving to be somewhat superior to a NN for regularization parameter selection. Thus, ILR improves estimation of MWF within the biexponential model. In addition, classical methods such as GCV may be combined with deep learning to optimize MWF imaging in the human brain.
Hyperspectral Reconstruction of Skin Through Fusion of Scattering Transform Features
Apr 15, 2024Hyperspectral imagery (HSI) is an established technique with an array of applications, but its use is limited due to both practical and technical issues associated with spectral devices. The goal of the ICASSP 2024 'Hyper-Skin' Challenge is to extract skin HSI from matching RGB images and an infrared band. To address this problem we propose a model using features of the scattering transform - a type of convolutional neural network with predefined filters. Our model matches and inverts those features, rather than the pixel values, reducing the complexity of matching while grouping similar features together, resulting in an improved learning process.
Frame Quantization of Neural Networks
Apr 11, 2024We present a post-training quantization algorithm with error estimates relying on ideas originating from frame theory. Specifically, we use first-order Sigma-Delta ($\Sigma\Delta$) quantization for finite unit-norm tight frames to quantize weight matrices and biases in a neural network. In our scenario, we derive an error bound between the original neural network and the quantized neural network in terms of step size and the number of frame elements. We also demonstrate how to leverage the redundancy of frames to achieve a quantized neural network with higher accuracy.
Emergence of the SVD as an interpretable factorization in deep learning for inverse problems
Jan 18, 2023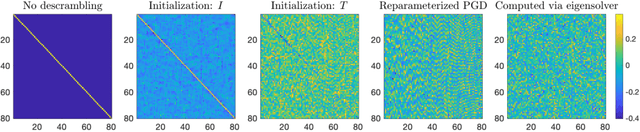

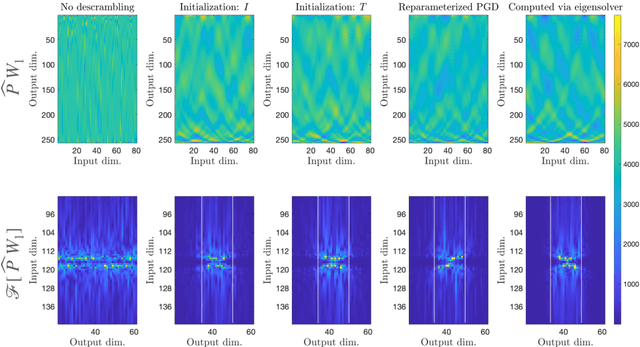
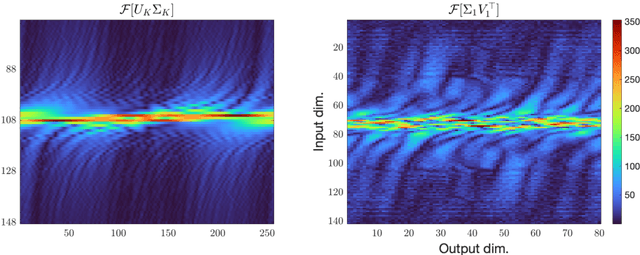
We demonstrate the emergence of weight matrix singular value decomposition (SVD) in interpreting neural networks (NNs) for parameter estimation from noisy signals. The SVD appears naturally as a consequence of initial application of a descrambling transform - a recently-developed technique for addressing interpretability in NNs \cite{amey2021neural}. We find that within the class of noisy parameter estimation problems, the SVD may be the means by which networks memorize the signal model. We substantiate our theoretical findings with empirical evidence from both linear and non-linear settings. Our results also illuminate the connections between a mathematical theory of semantic development \cite{saxe2019mathematical} and neural network interpretability.
Active Learning at the ImageNet Scale
Nov 25, 2021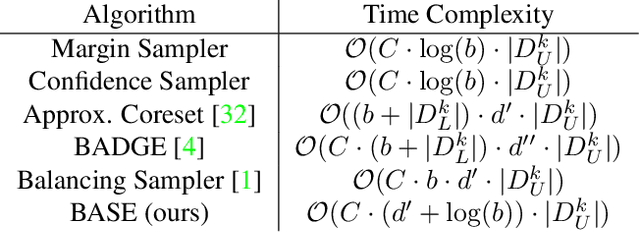
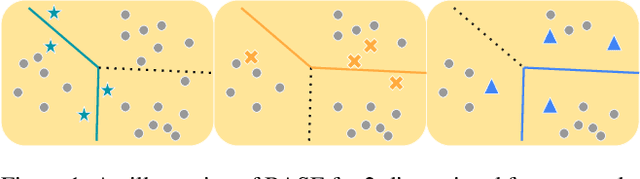

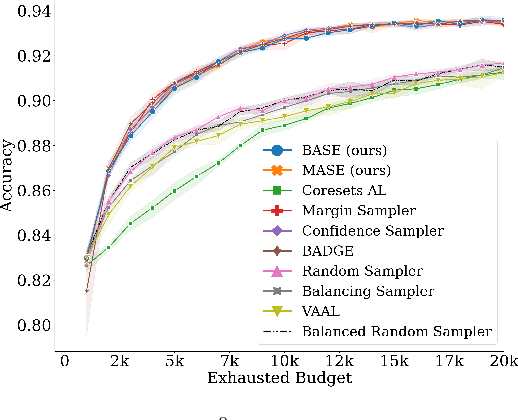
Active learning (AL) algorithms aim to identify an optimal subset of data for annotation, such that deep neural networks (DNN) can achieve better performance when trained on this labeled subset. AL is especially impactful in industrial scale settings where data labeling costs are high and practitioners use every tool at their disposal to improve model performance. The recent success of self-supervised pretraining (SSP) highlights the importance of harnessing abundant unlabeled data to boost model performance. By combining AL with SSP, we can make use of unlabeled data while simultaneously labeling and training on particularly informative samples. In this work, we study a combination of AL and SSP on ImageNet. We find that performance on small toy datasets -- the typical benchmark setting in the literature -- is not representative of performance on ImageNet due to the class imbalanced samples selected by an active learner. Among the existing baselines we test, popular AL algorithms across a variety of small and large scale settings fail to outperform random sampling. To remedy the class-imbalance problem, we propose Balanced Selection (BASE), a simple, scalable AL algorithm that outperforms random sampling consistently by selecting more balanced samples for annotation than existing methods. Our code is available at: https://github.com/zeyademam/active_learning .
Exploring the high dimensional geometry of HSI features
Mar 01, 2021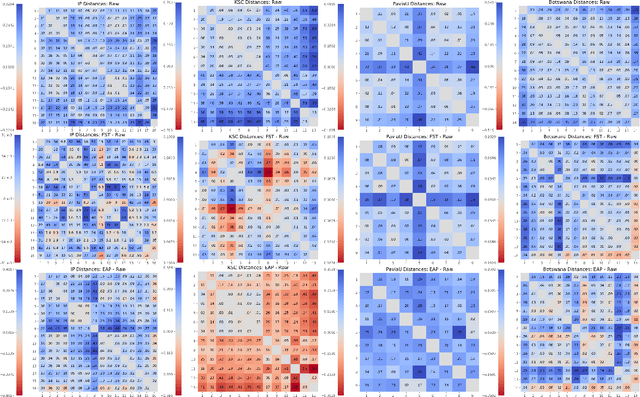

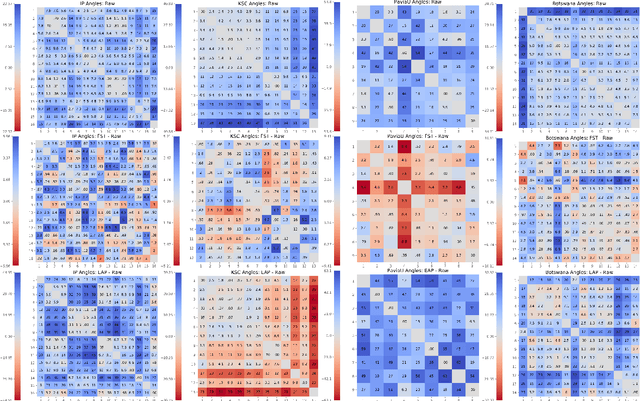

We explore feature space geometries induced by the 3-D Fourier scattering transform and deep neural network with extended attribute profiles on four standard hyperspectral images. We examine the distances and angles of class means, the variability of classes, and their low-dimensional structures. These statistics are compared to that of raw features, and our results provide insight into the vastly different properties of these two methods. We also explore a connection with the newly observed deep learning phenomenon of neural collapse.
Maximal function pooling with applications
Mar 01, 2021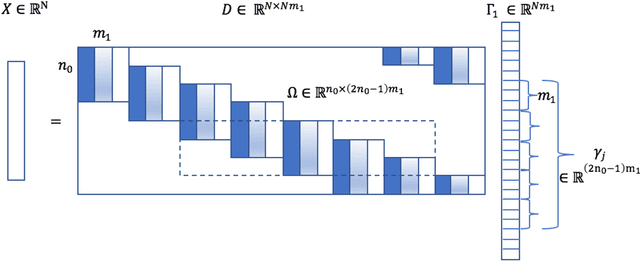

Inspired by the Hardy-Littlewood maximal function, we propose a novel pooling strategy which is called maxfun pooling. It is presented both as a viable alternative to some of the most popular pooling functions, such as max pooling and average pooling, and as a way of interpolating between these two algorithms. We demonstrate the features of maxfun pooling with two applications: first in the context of convolutional sparse coding, and then for image classification.
Cortical Features for Defense Against Adversarial Audio Attacks
Jan 30, 2021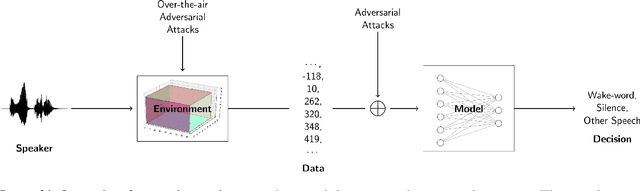
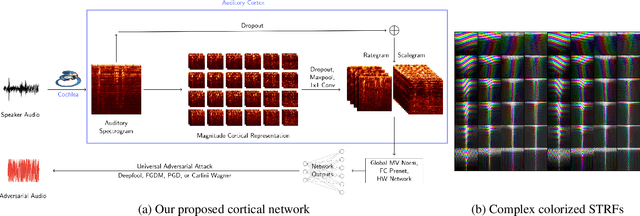

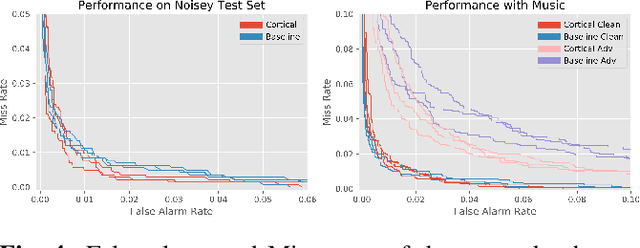
We propose using a computational model of the auditory cortex as a defense against adversarial attacks on audio. We apply several white-box iterative optimization-based adversarial attacks to an implementation of Amazon Alexa's HW network, and a modified version of this network with an integrated cortical representation, and show that the cortical features help defend against universal adversarial examples. At the same level of distortion, the adversarial noises found for the cortical network are always less effective for universal audio attacks. We make our code publicly available at https://github.com/ilyakava/py3fst.
Witches' Brew: Industrial Scale Data Poisoning via Gradient Matching
Sep 04, 2020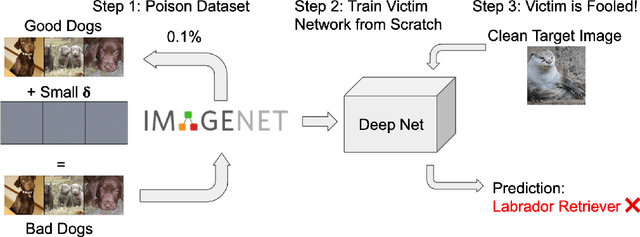
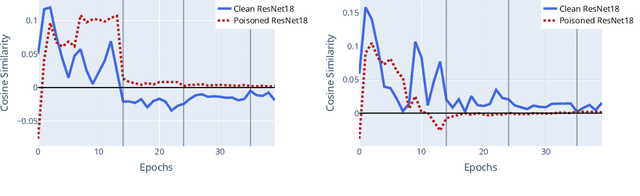
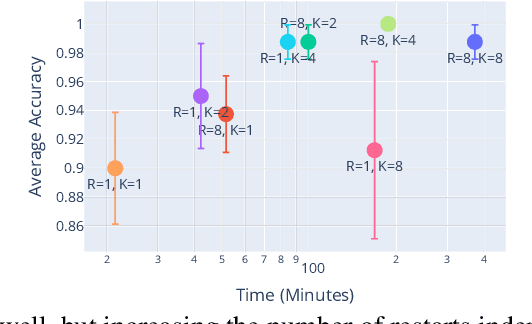

Data Poisoning attacks involve an attacker modifying training data to maliciouslycontrol a model trained on this data. Previous poisoning attacks against deep neural networks have been limited in scope and success, working only in simplified settings or being prohibitively expensive for large datasets. In this work, we focus on a particularly malicious poisoning attack that is both "from scratch" and"clean label", meaning we analyze an attack that successfully works against new, randomly initialized models, and is nearly imperceptible to humans, all while perturbing only a small fraction of the training data. The central mechanism of this attack is matching the gradient direction of malicious examples. We analyze why this works, supplement with practical considerations. and show its threat to real-world practitioners, finding that it is the first poisoning method to cause targeted misclassification in modern deep networks trained from scratch on a full-sized, poisoned ImageNet dataset. Finally we demonstrate the limitations of existing defensive strategies against such an attack, concluding that data poisoning is a credible threat, even for large-scale deep learning systems.