 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural collapse in the orthoplex regime
Mar 21, 2026When training a neural network for classification, the feature vectors of the training set are known to collapse to the vertices of a regular simplex, provided the dimension $d$ of the feature space and the number $n$ of classes satisfies $n\leq d+1$. This phenomenon is known as neural collapse. For other applications like language models, one instead takes $n\gg d$. Here, the neural collapse phenomenon still occurs, but with different emergent geometric figures. We characterize these geometric figures in the orthoplex regime where $d+2\leq n\leq 2d$. The techniques in our analysis primarily involve Radon's theorem and convexity.
Curse of Dimensionality in Neural Network Optimization
Feb 07, 2025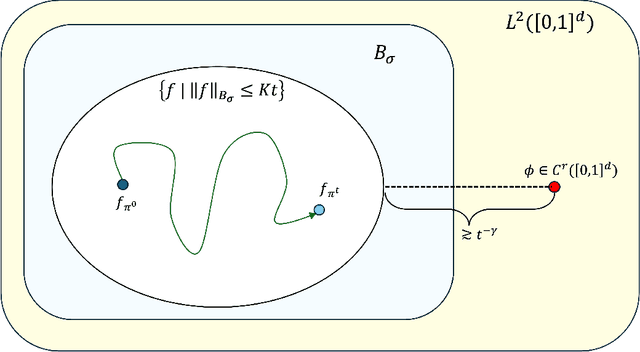
The curse of dimensionality in neural network optimization under the mean-field regime is studied. It is demonstrated that when a shallow neural network with a Lipschitz continuous activation function is trained using either empirical or population risk to approximate a target function that is $r$ times continuously differentiable on $[0,1]^d$, the population risk may not decay at a rate faster than $t^{-\frac{4r}{d-2r}}$, where $t$ is an analog of the total number of optimization iterations. This result highlights the presence of the curse of dimensionality in the optimization computation required to achieve a desired accuracy. Instead of analyzing parameter evolution directly, the training dynamics are examined through the evolution of the parameter distribution under the 2-Wasserstein gradient flow. Furthermore, it is established that the curse of dimensionality persists when a locally Lipschitz continuous activation function is employed, where the Lipschitz constant in $[-x,x]$ is bounded by $O(x^\delta)$ for any $x \in \mathbb{R}$. In this scenario, the population risk is shown to decay at a rate no faster than $t^{-\frac{(4+2\delta)r}{d-2r}}$. To the best of our knowledge, this work is the first to analyze the impact of function smoothness on the curse of dimensionality in neural network optimization theory.
Frame Quantization of Neural Networks
Apr 11, 2024We present a post-training quantization algorithm with error estimates relying on ideas originating from frame theory. Specifically, we use first-order Sigma-Delta ($\Sigma\Delta$) quantization for finite unit-norm tight frames to quantize weight matrices and biases in a neural network. In our scenario, we derive an error bound between the original neural network and the quantized neural network in terms of step size and the number of frame elements. We also demonstrate how to leverage the redundancy of frames to achieve a quantized neural network with higher accuracy.