 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Contrastive Learning for Time Series Representation
Oct 20, 2024



Understanding events in time series is an important task in a variety of contexts. However, human analysis and labeling are expensive and time-consuming. Therefore, it is advantageous to learn embeddings for moments in time series in an unsupervised way, which allows for good performance in classification or detection tasks after later minimal human labeling. In this paper, we propose dynamic contrastive learning (DynaCL), an unsupervised contrastive representation learning framework for time series that uses temporal adjacent steps to define positive pairs. DynaCL adopts N-pair loss to dynamically treat all samples in a batch as positive or negative pairs, enabling efficient training and addressing the challenges of complicated sampling of positives. We demonstrate that DynaCL embeds instances from time series into semantically meaningful clusters, which allows superior performance on downstream tasks on a variety of public time series datasets. Our findings also reveal that high scores on unsupervised clustering metrics do not guarantee that the representations are useful in downstream tasks.
Execute Order 66: Targeted Data Poisoning for Reinforcement Learning
Jan 03, 2022
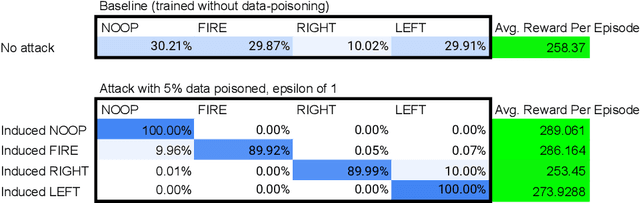

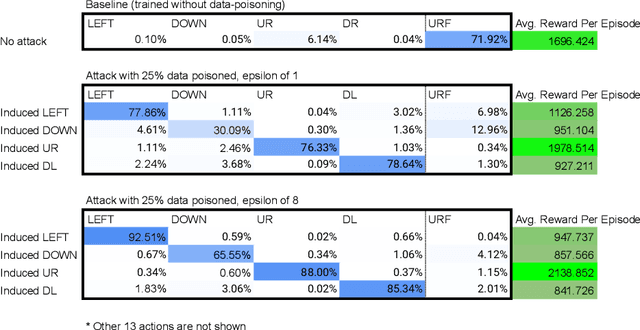
Data poisoning for reinforcement learning has historically focused on general performance degradation, and targeted attacks have been successful via perturbations that involve control of the victim's policy and rewards. We introduce an insidious poisoning attack for reinforcement learning which causes agent misbehavior only at specific target states - all while minimally modifying a small fraction of training observations without assuming any control over policy or reward. We accomplish this by adapting a recent technique, gradient alignment, to reinforcement learning. We test our method and demonstrate success in two Atari games of varying difficulty.
Probabilistic Deep Learning to Quantify Uncertainty in Air Quality Forecasting
Dec 05, 2021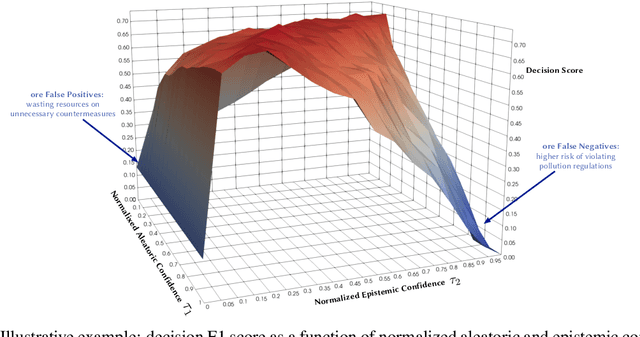
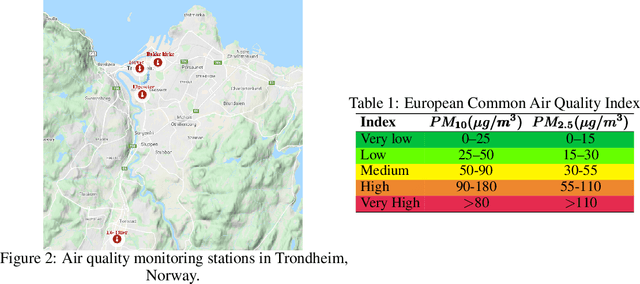
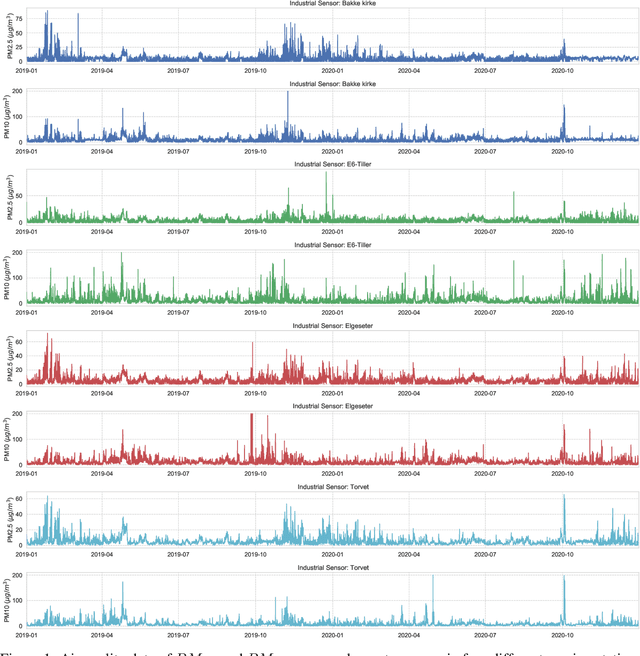
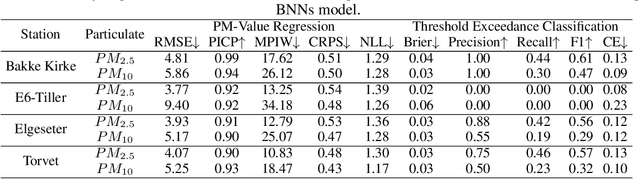
Data-driven forecasts of air quality have recently achieved more accurate short-term predictions. Despite their success, most of the current data-driven solutions lack proper quantifications of model uncertainty that communicate how much to trust the forecasts. Recently, several practical tools to estimate uncertainty have been developed in probabilistic deep learning. However, there have not been empirical applications and extensive comparisons of these tools in the domain of air quality forecasts. Therefore, this work applies state-of-the-art techniques of uncertainty quantification in a real-world setting of air quality forecasts. Through extensive experiments, we describe training probabilistic models and evaluate their predictive uncertainties based on empirical performance, reliability of confidence estimate, and practical applicability. We also propose improving these models using "free" adversarial training and exploiting temporal and spatial correlation inherent in air quality data. Our experiments demonstrate that the proposed models perform better than previous works in quantifying uncertainty in data-driven air quality forecasts. Overall, Bayesian neural networks provide a more reliable uncertainty estimate but can be challenging to implement and scale. Other scalable methods, such as deep ensemble, Monte Carlo (MC) dropout, and stochastic weight averaging-Gaussian (SWAG), can perform well if applied correctly but with different tradeoffs and slight variations in performance metrics. Finally, our results show the practical impact of uncertainty estimation and demonstrate that, indeed, probabilistic models are more suitable for making informed decisions. Code and dataset are available at \url{https://github.com/Abdulmajid-Murad/deep_probabilistic_forecast}
LowKey: Leveraging Adversarial Attacks to Protect Social Media Users from Facial Recognition
Jan 25, 2021

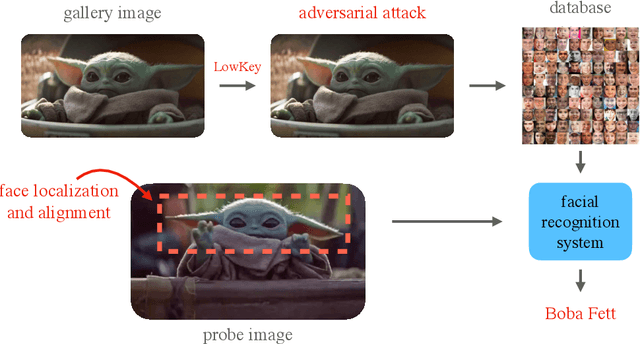
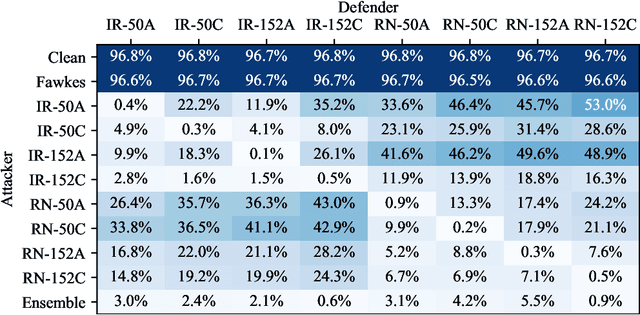
Facial recognition systems are increasingly deployed by private corporations, government agencies, and contractors for consumer services and mass surveillance programs alike. These systems are typically built by scraping social media profiles for user images. Adversarial perturbations have been proposed for bypassing facial recognition systems. However, existing methods fail on full-scale systems and commercial APIs. We develop our own adversarial filter that accounts for the entire image processing pipeline and is demonstrably effective against industrial-grade pipelines that include face detection and large scale databases. Additionally, we release an easy-to-use webtool that significantly degrades the accuracy of Amazon Rekognition and the Microsoft Azure Face Recognition API, reducing the accuracy of each to below 1%.
FLAG: Adversarial Data Augmentation for Graph Neural Networks
Oct 19, 2020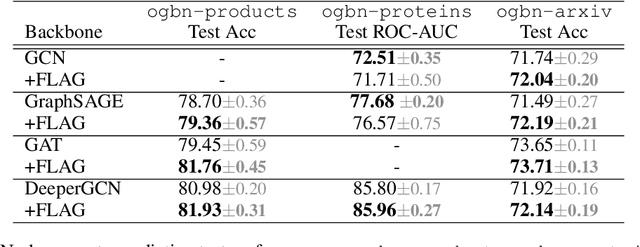
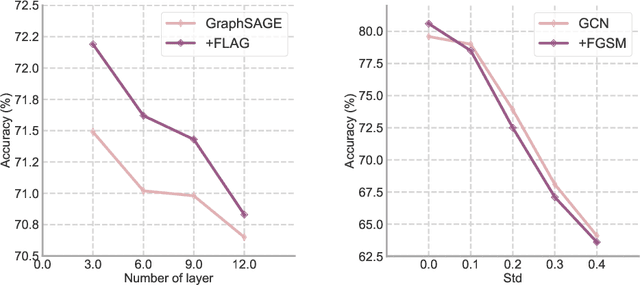

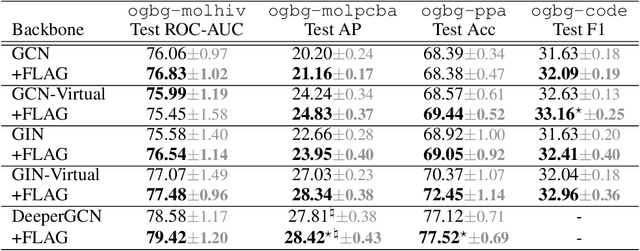
Data augmentation helps neural networks generalize better, but it remains an open question how to effectively augment graph data to enhance the performance of GNNs (Graph Neural Networks). While most existing graph regularizers focus on augmenting graph topological structures by adding/removing edges, we offer a novel direction to augment in the input node feature space for better performance. We propose a simple but effective solution, FLAG (Free Large-scale Adversarial Augmentation on Graphs), which iteratively augments node features with gradient-based adversarial perturbations during training, and boosts performance at test time. Empirically, FLAG can be easily implemented with a dozen lines of code and is flexible enough to function with any GNN backbone, on a wide variety of large-scale datasets, and in both transductive and inductive settings. Without modifying a model's architecture or training setup, FLAG yields a consistent and salient performance boost across both node and graph classification tasks. Using FLAG, we reach state-of-the-art performance on the large-scale ogbg-molpcba, ogbg-ppa, and ogbg-code datasets.
Information-Driven Adaptive Sensing Based on Deep Reinforcement Learning
Oct 08, 2020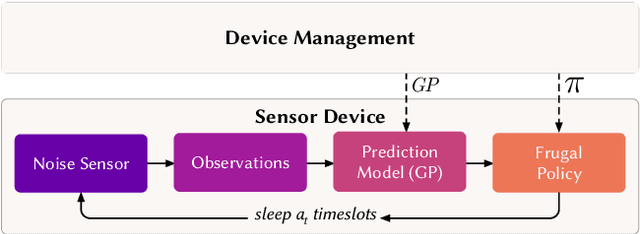
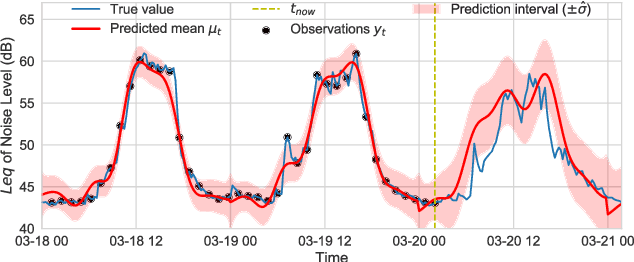
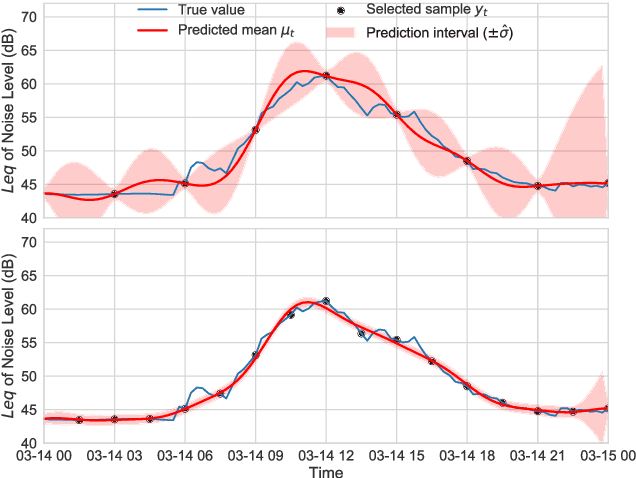
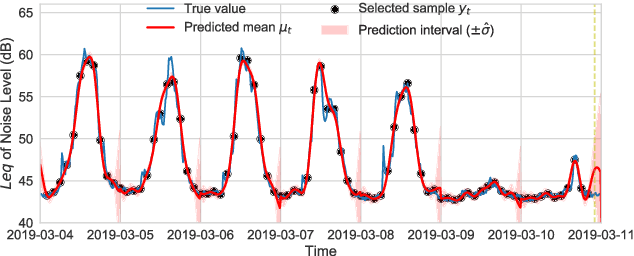
In order to make better use of deep reinforcement learning in the creation of sensing policies for resource-constrained IoT devices, we present and study a novel reward function based on the Fisher information value. This reward function enables IoT sensor devices to learn to spend available energy on measurements at otherwise unpredictable moments, while conserving energy at times when measurements would provide little new information. This is a highly general approach, which allows for a wide range of use cases without significant human design effort or hyper-parameter tuning. We illustrate the approach in a scenario of workplace noise monitoring, where results show that the learned behavior outperforms a uniform sampling strategy and comes close to a near-optimal oracle solution.
* 8 pages, 8 figures
Witches' Brew: Industrial Scale Data Poisoning via Gradient Matching
Sep 04, 2020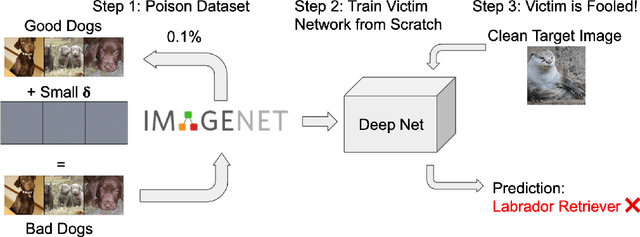
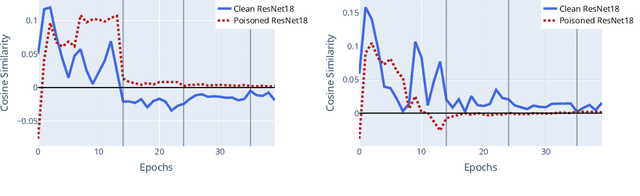
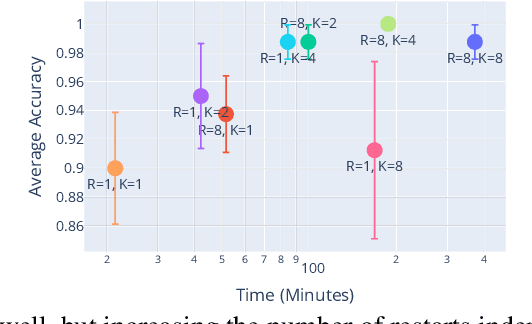

Data Poisoning attacks involve an attacker modifying training data to maliciouslycontrol a model trained on this data. Previous poisoning attacks against deep neural networks have been limited in scope and success, working only in simplified settings or being prohibitively expensive for large datasets. In this work, we focus on a particularly malicious poisoning attack that is both "from scratch" and"clean label", meaning we analyze an attack that successfully works against new, randomly initialized models, and is nearly imperceptible to humans, all while perturbing only a small fraction of the training data. The central mechanism of this attack is matching the gradient direction of malicious examples. We analyze why this works, supplement with practical considerations. and show its threat to real-world practitioners, finding that it is the first poisoning method to cause targeted misclassification in modern deep networks trained from scratch on a full-sized, poisoned ImageNet dataset. Finally we demonstrate the limitations of existing defensive strategies against such an attack, concluding that data poisoning is a credible threat, even for large-scale deep learning systems.
MetaPoison: Practical General-purpose Clean-label Data Poisoning
Apr 01, 2020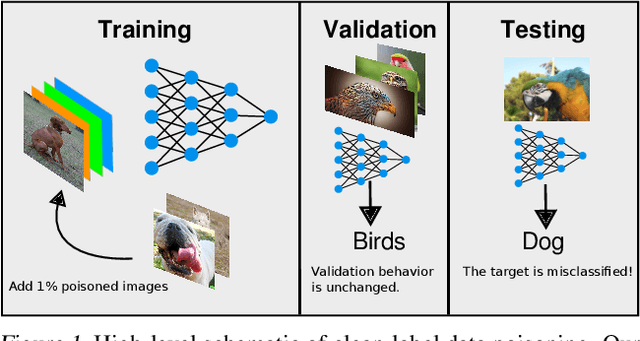
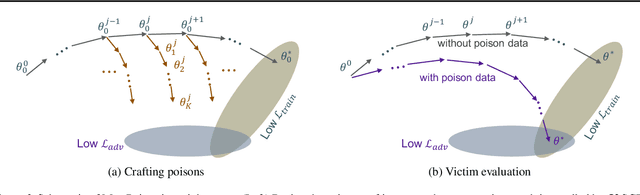
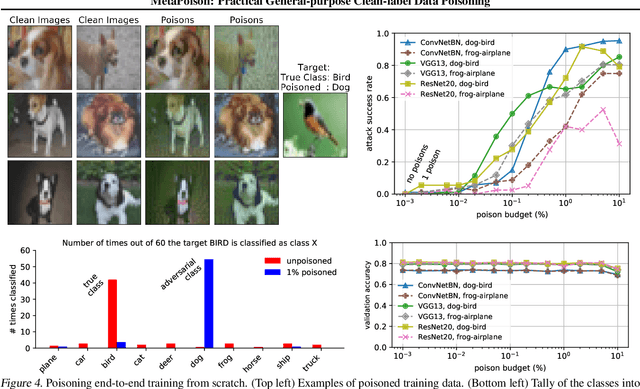
Data poisoning--the process by which an attacker takes control of a model by making imperceptible changes to a subset of the training data--is an emerging threat in the context of neural networks. Existing attacks for data poisoning have relied on hand-crafted heuristics. Instead, we pose crafting poisons more generally as a bi-level optimization problem, where the inner level corresponds to training a network on a poisoned dataset and the outer level corresponds to updating those poisons to achieve a desired behavior on the trained model. We then propose MetaPoison, a first-order method to solve this optimization quickly. MetaPoison is effective: it outperforms previous clean-label poisoning methods by a large margin under the same setting. MetaPoison is robust: its poisons transfer to a variety of victims with unknown hyperparameters and architectures. MetaPoison is also general-purpose, working not only in fine-tuning scenarios, but also for end-to-end training from scratch with remarkable success, e.g. causing a target image to be misclassified 90% of the time via manipulating just 1% of the dataset. Additionally, MetaPoison can achieve arbitrary adversary goals not previously possible--like using poisons of one class to make a target image don the label of another arbitrarily chosen class. Finally, MetaPoison works in the real-world. We demonstrate successful data poisoning of models trained on Google Cloud AutoML Vision. Code and premade poisons are provided at https://github.com/wronnyhuang/metapoison
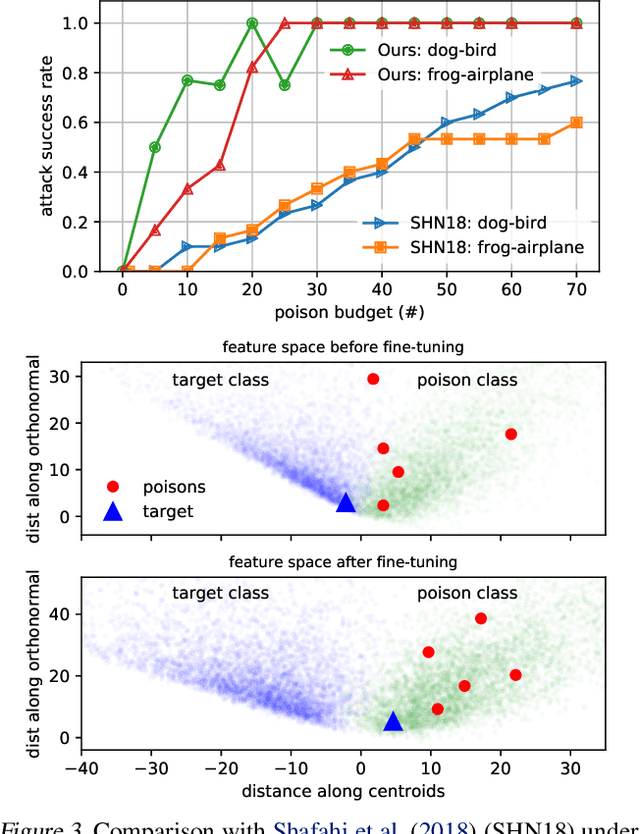
Transferable Clean-Label Poisoning Attacks on Deep Neural Nets
May 16, 2019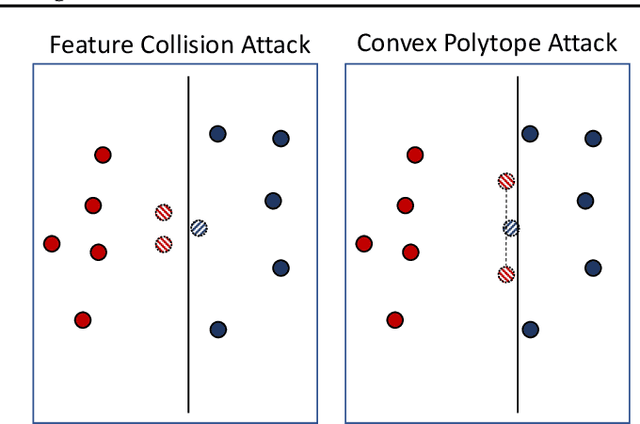

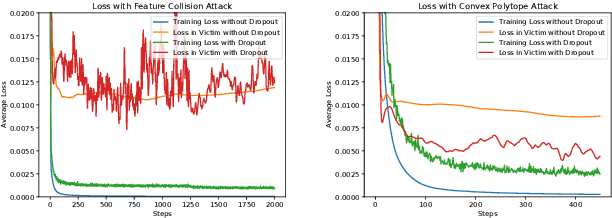

Clean-label poisoning attacks inject innocuous looking (and "correctly" labeled) poison images into training data, causing a model to misclassify a targeted image after being trained on this data. We consider transferable poisoning attacks that succeed without access to the victim network's outputs, architecture, or (in some cases) training data. To achieve this, we propose a new "polytope attack" in which poison images are designed to surround the targeted image in feature space. We also demonstrate that using Dropout during poison creation helps to enhance transferability of this attack. We achieve transferable attack success rates of over 50% while poisoning only 1% of the training set.
Autonomous Management of Energy-Harvesting IoT Nodes Using Deep Reinforcement Learning
May 10, 2019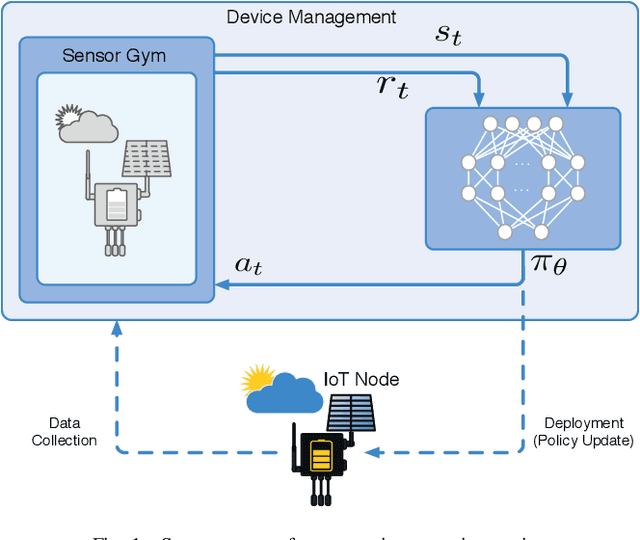
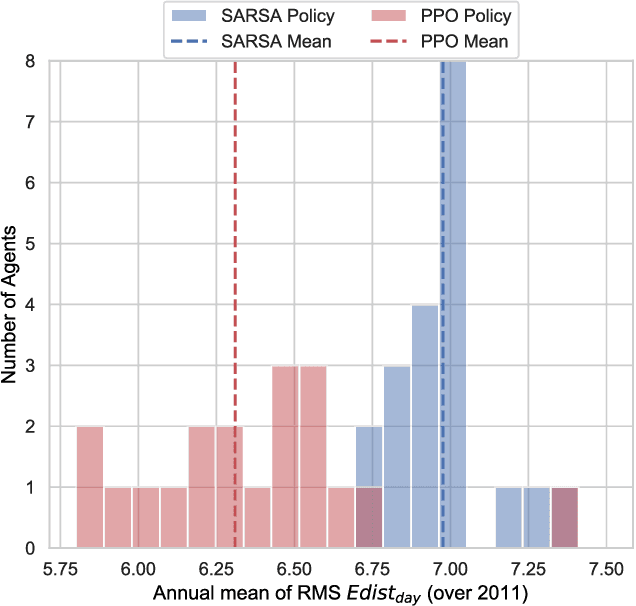
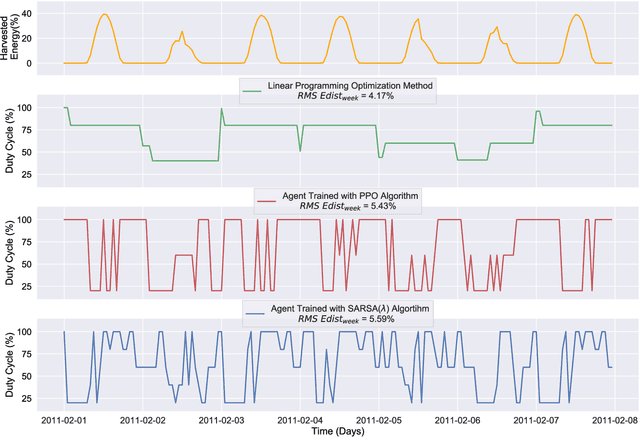
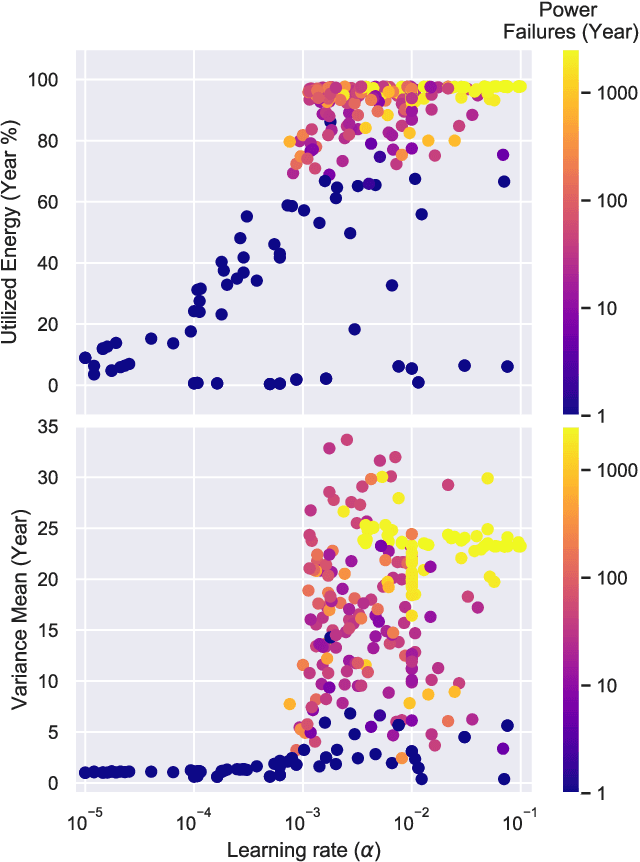
Reinforcement learning (RL) is capable of managing wireless, energy-harvesting IoT nodes by solving the problem of autonomous management in non-stationary, resource-constrained settings. We show that the state-of-the-art policy-gradient approaches to RL are appropriate for the IoT domain and that they outperform previous approaches. Due to the ability to model continuous observation and action spaces, as well as improved function approximation capability, the new approaches are able to solve harder problems, permitting reward functions that are better aligned with the actual application goals. We show such a reward function and use policy-gradient approaches to learn capable policies, leading to behavior more appropriate for IoT nodes with less manual design effort, increasing the level of autonomy in IoT.