 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Contrastive Learning for Time Series Representation
Oct 20, 2024



Understanding events in time series is an important task in a variety of contexts. However, human analysis and labeling are expensive and time-consuming. Therefore, it is advantageous to learn embeddings for moments in time series in an unsupervised way, which allows for good performance in classification or detection tasks after later minimal human labeling. In this paper, we propose dynamic contrastive learning (DynaCL), an unsupervised contrastive representation learning framework for time series that uses temporal adjacent steps to define positive pairs. DynaCL adopts N-pair loss to dynamically treat all samples in a batch as positive or negative pairs, enabling efficient training and addressing the challenges of complicated sampling of positives. We demonstrate that DynaCL embeds instances from time series into semantically meaningful clusters, which allows superior performance on downstream tasks on a variety of public time series datasets. Our findings also reveal that high scores on unsupervised clustering metrics do not guarantee that the representations are useful in downstream tasks.
Probabilistic Deep Learning to Quantify Uncertainty in Air Quality Forecasting
Dec 05, 2021
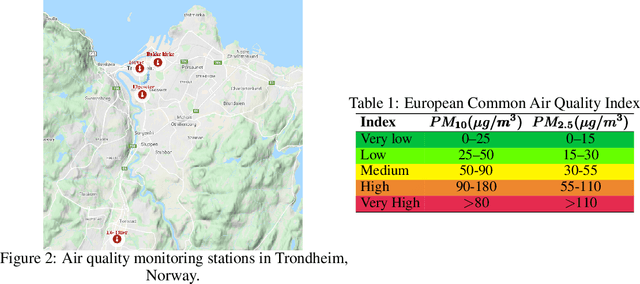
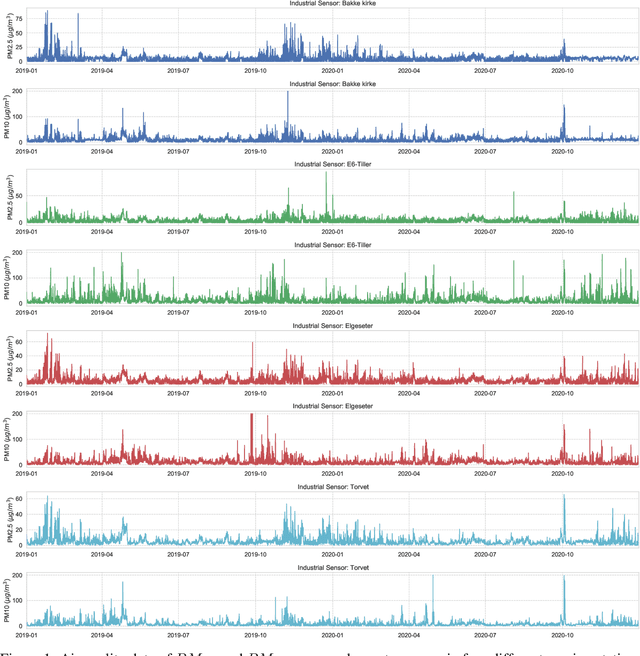
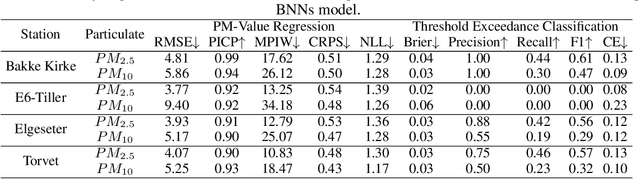
Data-driven forecasts of air quality have recently achieved more accurate short-term predictions. Despite their success, most of the current data-driven solutions lack proper quantifications of model uncertainty that communicate how much to trust the forecasts. Recently, several practical tools to estimate uncertainty have been developed in probabilistic deep learning. However, there have not been empirical applications and extensive comparisons of these tools in the domain of air quality forecasts. Therefore, this work applies state-of-the-art techniques of uncertainty quantification in a real-world setting of air quality forecasts. Through extensive experiments, we describe training probabilistic models and evaluate their predictive uncertainties based on empirical performance, reliability of confidence estimate, and practical applicability. We also propose improving these models using "free" adversarial training and exploiting temporal and spatial correlation inherent in air quality data. Our experiments demonstrate that the proposed models perform better than previous works in quantifying uncertainty in data-driven air quality forecasts. Overall, Bayesian neural networks provide a more reliable uncertainty estimate but can be challenging to implement and scale. Other scalable methods, such as deep ensemble, Monte Carlo (MC) dropout, and stochastic weight averaging-Gaussian (SWAG), can perform well if applied correctly but with different tradeoffs and slight variations in performance metrics. Finally, our results show the practical impact of uncertainty estimation and demonstrate that, indeed, probabilistic models are more suitable for making informed decisions. Code and dataset are available at \url{https://github.com/Abdulmajid-Murad/deep_probabilistic_forecast}
FishNet: A Unified Embedding for Salmon Recognition
Oct 20, 2020

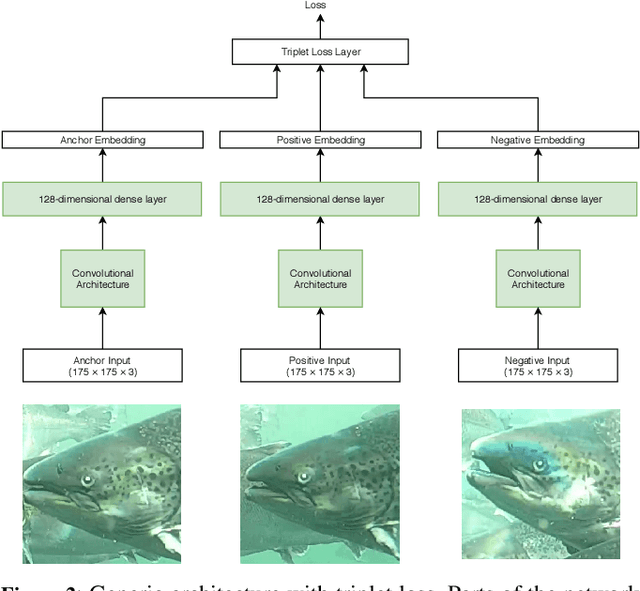

Identifying individual salmon can be very beneficial for the aquaculture industry as it enables monitoring and analyzing fish behavior and welfare. For aquaculture researchers identifying individual salmon is imperative to their research. The current methods of individual salmon tagging and tracking rely on physical interaction with the fish. This process is inefficient and can cause physical harm and stress for the salmon. In this paper we propose FishNet, based on a deep learning technique that has been successfully used for identifying humans, to identify salmon.We create a dataset of labeled fish images and then test the performance of the FishNet architecture. Our experiments show that this architecture learns a useful representation based on images of salmon heads. Further, we show that good performance can be achieved with relatively small neural network models: FishNet achieves a false positive rate of 1\% and a true positive rate of 96\%.
Information-Driven Adaptive Sensing Based on Deep Reinforcement Learning
Oct 08, 2020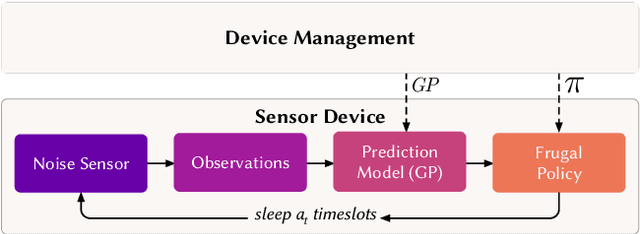
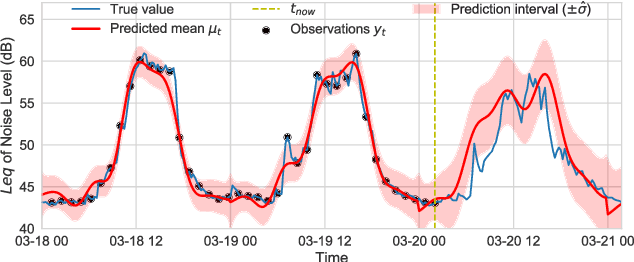
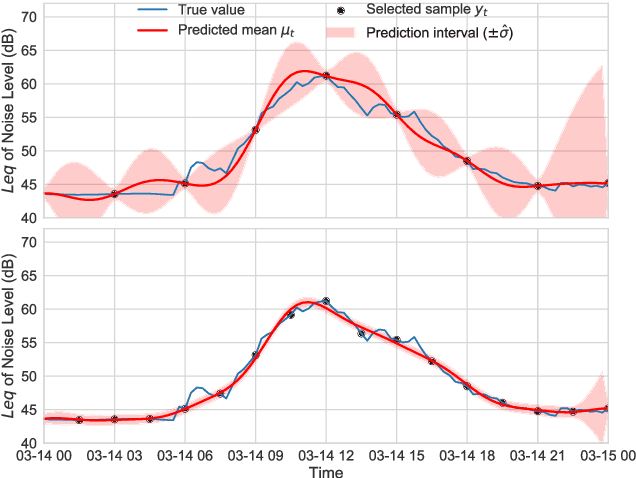
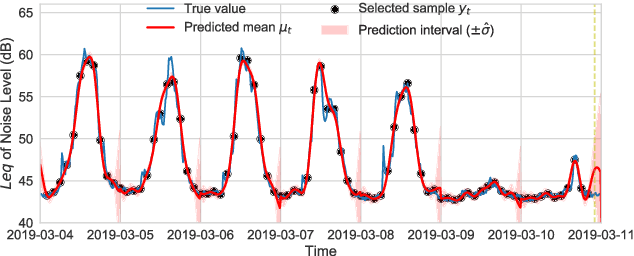
In order to make better use of deep reinforcement learning in the creation of sensing policies for resource-constrained IoT devices, we present and study a novel reward function based on the Fisher information value. This reward function enables IoT sensor devices to learn to spend available energy on measurements at otherwise unpredictable moments, while conserving energy at times when measurements would provide little new information. This is a highly general approach, which allows for a wide range of use cases without significant human design effort or hyper-parameter tuning. We illustrate the approach in a scenario of workplace noise monitoring, where results show that the learned behavior outperforms a uniform sampling strategy and comes close to a near-optimal oracle solution.
* 8 pages, 8 figures
Learning similarity measures from data
Jan 15, 2020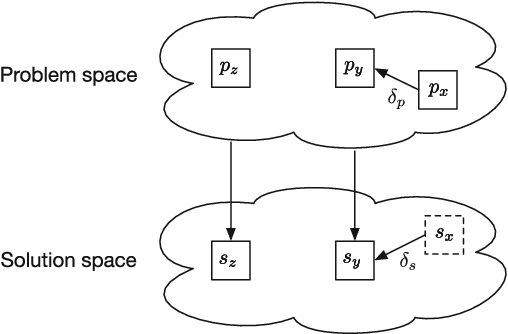

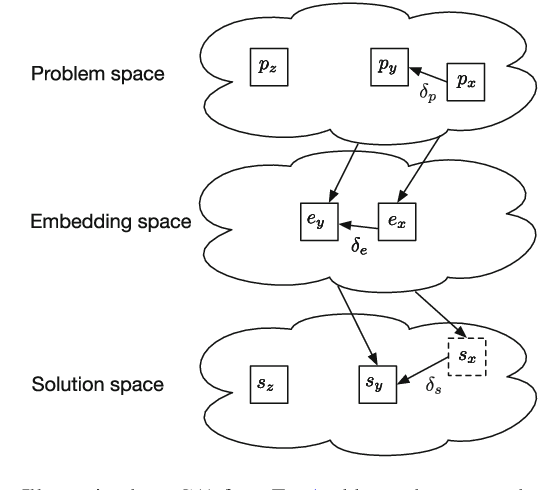
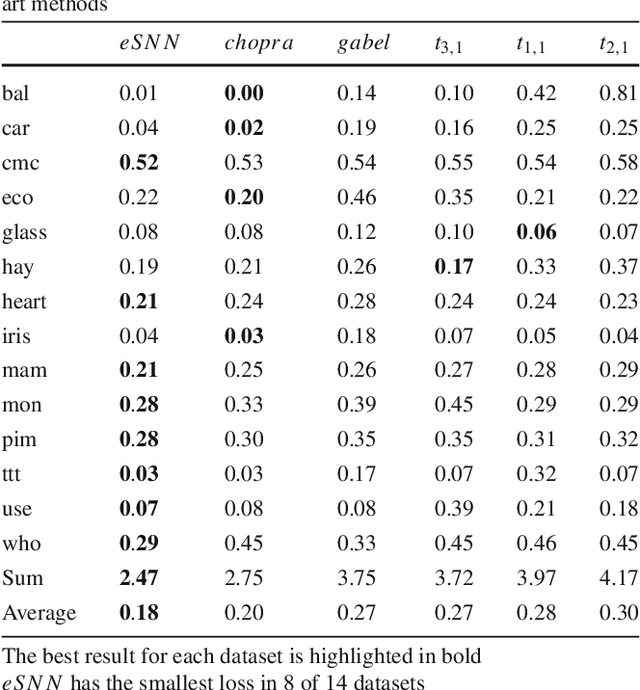
Defining similarity measures is a requirement for some machine learning methods. One such method is case-based reasoning (CBR) where the similarity measure is used to retrieve the stored case or set of cases most similar to the query case. Describing a similarity measure analytically is challenging, even for domain experts working with CBR experts. However, data sets are typically gathered as part of constructing a CBR or machine learning system. These datasets are assumed to contain the features that correctly identify the solution from the problem features, thus they may also contain the knowledge to construct or learn such a similarity measure. The main motivation for this work is to automate the construction of similarity measures using machine learning, while keeping training time as low as possible. Our objective is to investigate how to apply machine learning to effectively learn a similarity measure. Such a learned similarity measure could be used for CBR systems, but also for clustering data in semi-supervised learning, or one-shot learning tasks. Recent work has advanced towards this goal, relies on either very long training times or manually modeling parts of the similarity measure. We created a framework to help us analyze current methods for learning similarity measures. This analysis resulted in two novel similarity measure designs. One design using a pre-trained classifier as basis for a similarity measure. The second design uses as little modeling as possible while learning the similarity measure from data and keeping training time low. Both similarity measures were evaluated on 14 different datasets. The evaluation shows that using a classifier as basis for a similarity measure gives state of the art performance. Finally the evaluation shows that our fully data-driven similarity measure design outperforms state of the art methods while keeping training time low.
Similarity Measure Development for Case-Based Reasoning- A Data-driven Approach
May 21, 2019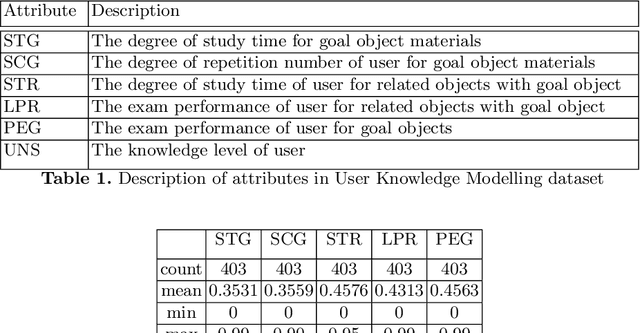
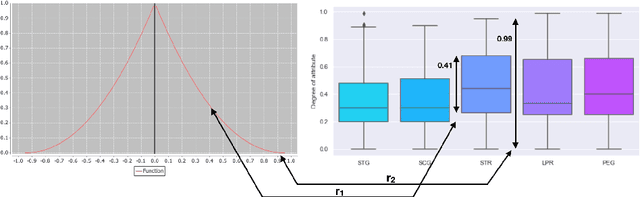
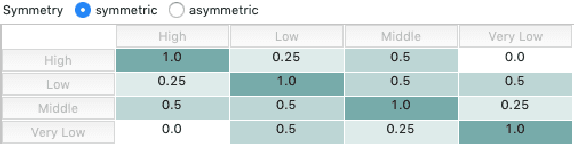
In this paper, we demonstrate a data-driven methodology for modelling the local similarity measures of various attributes in a dataset. We analyse the spread in the numerical attributes and estimate their distribution using polynomial function to showcase an approach for deriving strong initial value ranges of numerical attributes and use a non-overlapping distribution for categorical attributes such that the entire similarity range [0,1] is utilized. We use an open source dataset for demonstrating modelling and development of the similarity measures and will present a case-based reasoning (CBR) system that can be used to search for the most relevant similar cases.
Autonomous Management of Energy-Harvesting IoT Nodes Using Deep Reinforcement Learning
May 10, 2019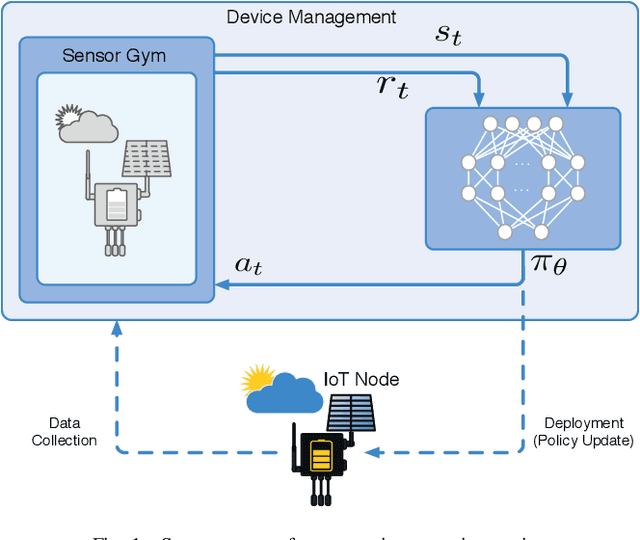
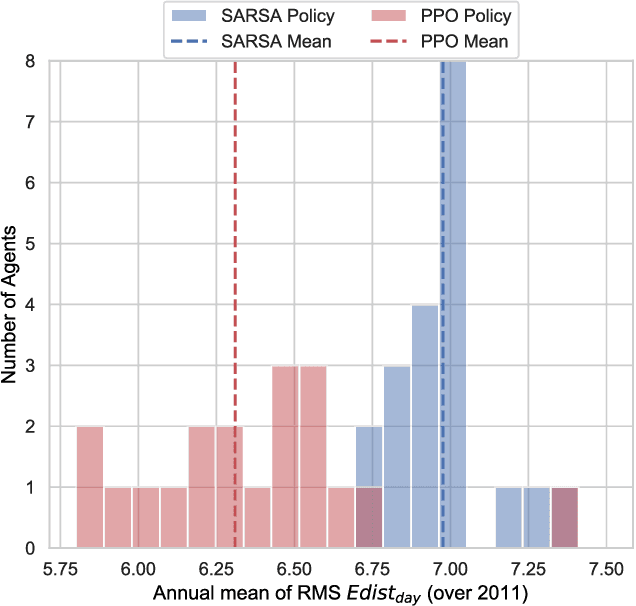
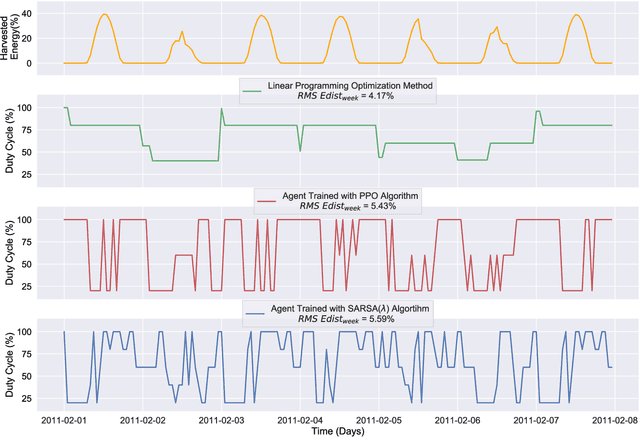
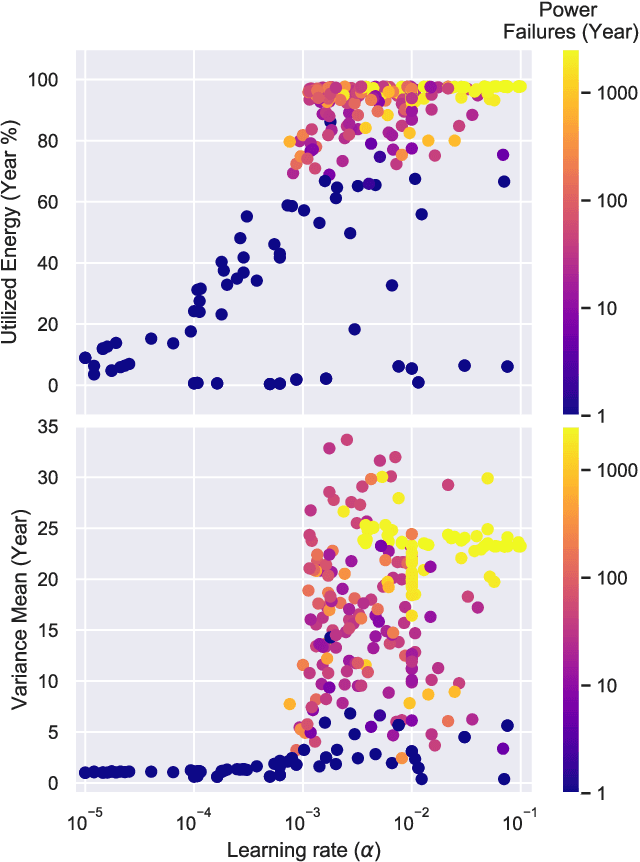
Reinforcement learning (RL) is capable of managing wireless, energy-harvesting IoT nodes by solving the problem of autonomous management in non-stationary, resource-constrained settings. We show that the state-of-the-art policy-gradient approaches to RL are appropriate for the IoT domain and that they outperform previous approaches. Due to the ability to model continuous observation and action spaces, as well as improved function approximation capability, the new approaches are able to solve harder problems, permitting reward functions that are better aligned with the actual application goals. We show such a reward function and use policy-gradient approaches to learn capable policies, leading to behavior more appropriate for IoT nodes with less manual design effort, increasing the level of autonomy in IoT.