 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFishNet: A Unified Embedding for Salmon Recognition
Oct 20, 2020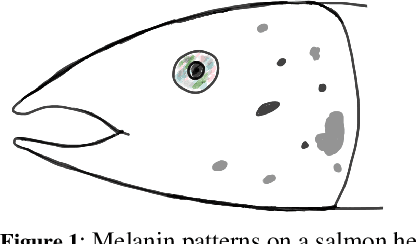

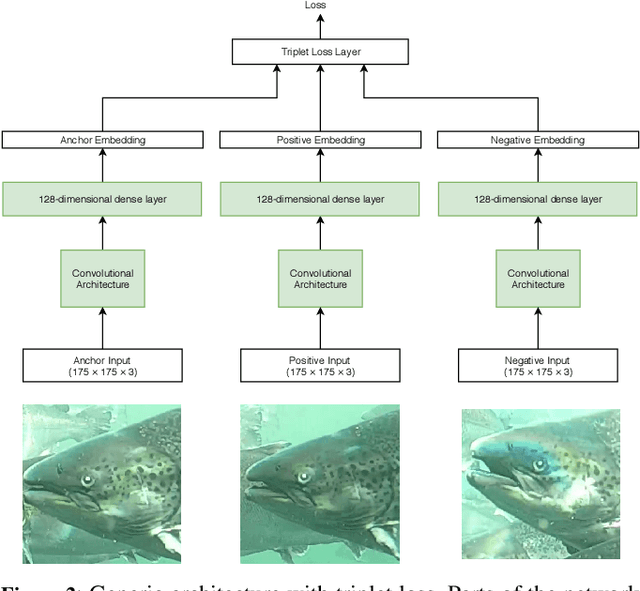

Identifying individual salmon can be very beneficial for the aquaculture industry as it enables monitoring and analyzing fish behavior and welfare. For aquaculture researchers identifying individual salmon is imperative to their research. The current methods of individual salmon tagging and tracking rely on physical interaction with the fish. This process is inefficient and can cause physical harm and stress for the salmon. In this paper we propose FishNet, based on a deep learning technique that has been successfully used for identifying humans, to identify salmon.We create a dataset of labeled fish images and then test the performance of the FishNet architecture. Our experiments show that this architecture learns a useful representation based on images of salmon heads. Further, we show that good performance can be achieved with relatively small neural network models: FishNet achieves a false positive rate of 1\% and a true positive rate of 96\%.
Learning similarity measures from data
Jan 15, 2020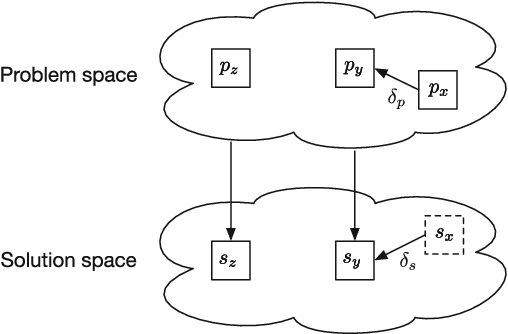

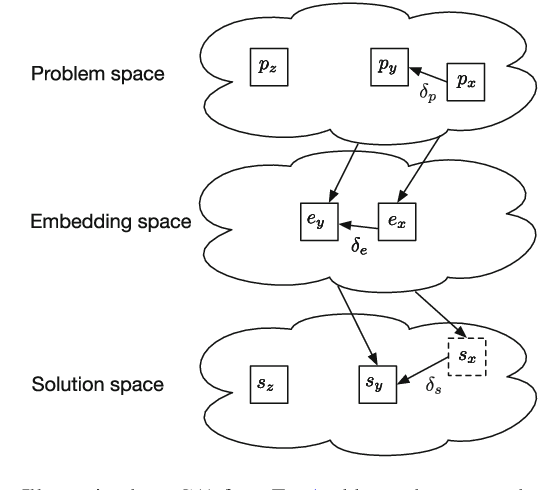
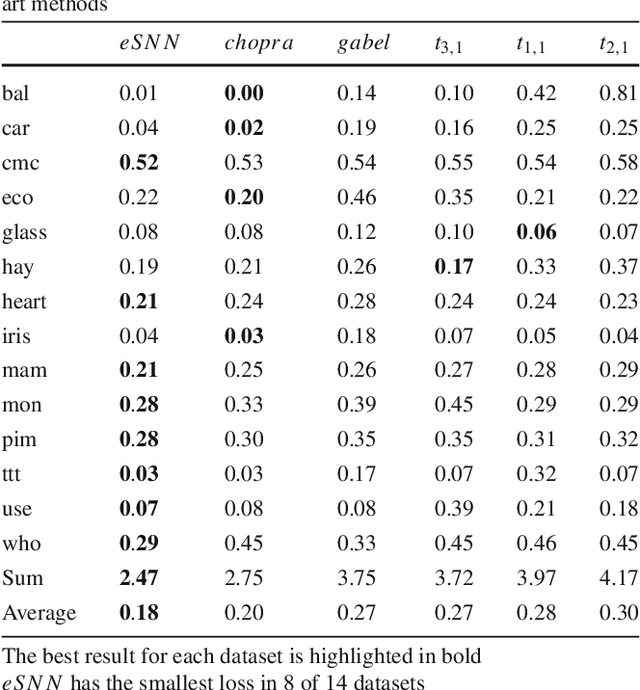
Defining similarity measures is a requirement for some machine learning methods. One such method is case-based reasoning (CBR) where the similarity measure is used to retrieve the stored case or set of cases most similar to the query case. Describing a similarity measure analytically is challenging, even for domain experts working with CBR experts. However, data sets are typically gathered as part of constructing a CBR or machine learning system. These datasets are assumed to contain the features that correctly identify the solution from the problem features, thus they may also contain the knowledge to construct or learn such a similarity measure. The main motivation for this work is to automate the construction of similarity measures using machine learning, while keeping training time as low as possible. Our objective is to investigate how to apply machine learning to effectively learn a similarity measure. Such a learned similarity measure could be used for CBR systems, but also for clustering data in semi-supervised learning, or one-shot learning tasks. Recent work has advanced towards this goal, relies on either very long training times or manually modeling parts of the similarity measure. We created a framework to help us analyze current methods for learning similarity measures. This analysis resulted in two novel similarity measure designs. One design using a pre-trained classifier as basis for a similarity measure. The second design uses as little modeling as possible while learning the similarity measure from data and keeping training time low. Both similarity measures were evaluated on 14 different datasets. The evaluation shows that using a classifier as basis for a similarity measure gives state of the art performance. Finally the evaluation shows that our fully data-driven similarity measure design outperforms state of the art methods while keeping training time low.
Decision Support Systems in Fisheries and Aquaculture: A systematic review
Nov 25, 2016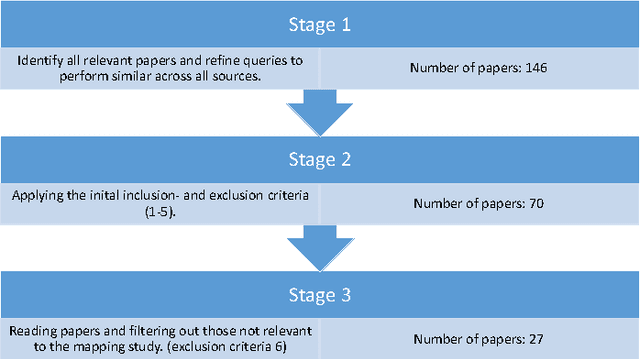



Decision support systems help decision makers make better decisions in the face of complex decision problems (e.g. investment or policy decisions). Fisheries and Aquaculture is a domain where decision makers face such decisions since they involve factors from many different scientific fields. No systematic overview of literature describing decision support systems and their application in fisheries and aquaculture has been conducted. This paper summarizes scientific literature that describes decision support systems applied to the domain of Fisheries and Aquaculture. We use an established systematic mapping survey method to conduct our literature mapping. Our research questions are: What decision support systems for fisheries and aquaculture exists? What are the most investigated fishery and aquaculture decision support systems topics and how have these changed over time? Do any current DSS for fisheries provide real- time analytics? Do DSSes in Fisheries and Aquaculture build their models using machine learning done on captured and grounded data? The paper then detail how we employ the systematic mapping method in answering these questions. This results in 27 papers being identified as relevant and gives an exposition on the primary methods concluded in the study for designing a decision support system. We provide an analysis of the research done in the studies collected. We discovered that most literature does not consider multiple aspects for multiple stakeholders in their work. In addition we observed that little or no work has been done with real-time analysis in these decision support systems.