 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning similarity measures from data
Paper and Code
Jan 15, 2020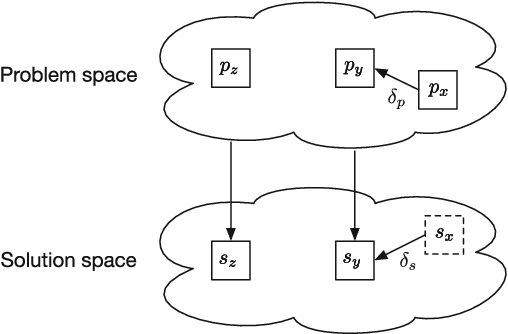

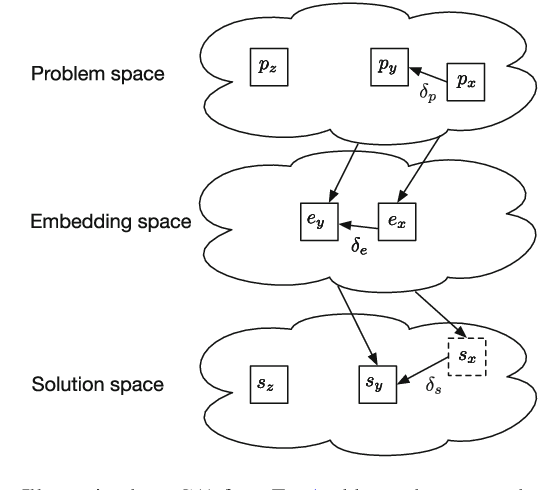
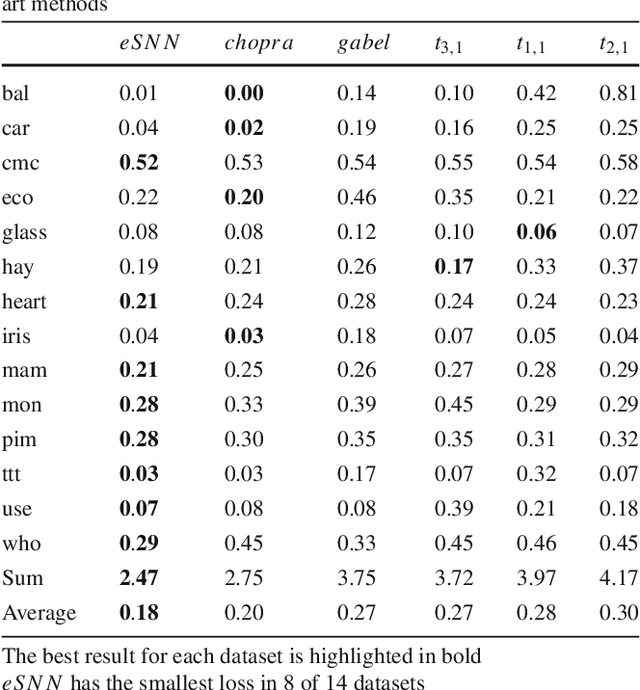
Defining similarity measures is a requirement for some machine learning methods. One such method is case-based reasoning (CBR) where the similarity measure is used to retrieve the stored case or set of cases most similar to the query case. Describing a similarity measure analytically is challenging, even for domain experts working with CBR experts. However, data sets are typically gathered as part of constructing a CBR or machine learning system. These datasets are assumed to contain the features that correctly identify the solution from the problem features, thus they may also contain the knowledge to construct or learn such a similarity measure. The main motivation for this work is to automate the construction of similarity measures using machine learning, while keeping training time as low as possible. Our objective is to investigate how to apply machine learning to effectively learn a similarity measure. Such a learned similarity measure could be used for CBR systems, but also for clustering data in semi-supervised learning, or one-shot learning tasks. Recent work has advanced towards this goal, relies on either very long training times or manually modeling parts of the similarity measure. We created a framework to help us analyze current methods for learning similarity measures. This analysis resulted in two novel similarity measure designs. One design using a pre-trained classifier as basis for a similarity measure. The second design uses as little modeling as possible while learning the similarity measure from data and keeping training time low. Both similarity measures were evaluated on 14 different datasets. The evaluation shows that using a classifier as basis for a similarity measure gives state of the art performance. Finally the evaluation shows that our fully data-driven similarity measure design outperforms state of the art methods while keeping training time low.