 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-Driven Adaptive Sensing Based on Deep Reinforcement Learning
Paper and Code
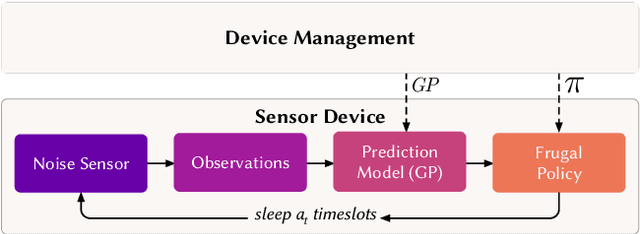
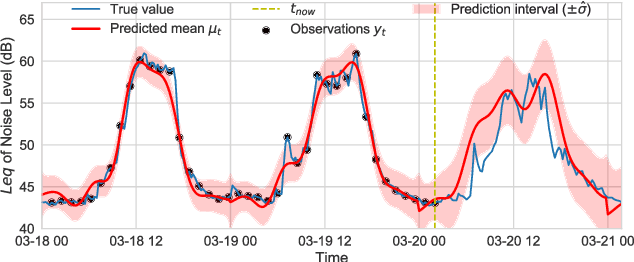
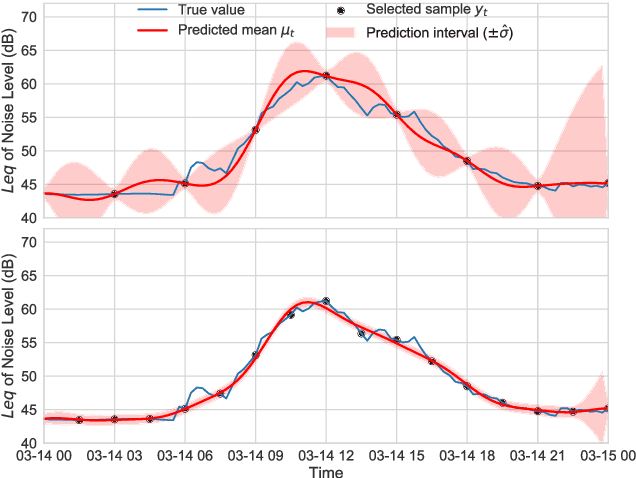
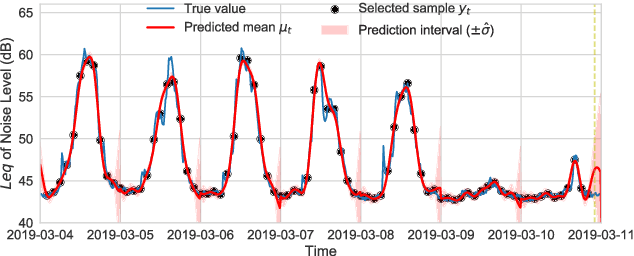
In order to make better use of deep reinforcement learning in the creation of sensing policies for resource-constrained IoT devices, we present and study a novel reward function based on the Fisher information value. This reward function enables IoT sensor devices to learn to spend available energy on measurements at otherwise unpredictable moments, while conserving energy at times when measurements would provide little new information. This is a highly general approach, which allows for a wide range of use cases without significant human design effort or hyper-parameter tuning. We illustrate the approach in a scenario of workplace noise monitoring, where results show that the learned behavior outperforms a uniform sampling strategy and comes close to a near-optimal oracle solution.