 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Management of Energy-Harvesting IoT Nodes Using Deep Reinforcement Learning
Paper and Code
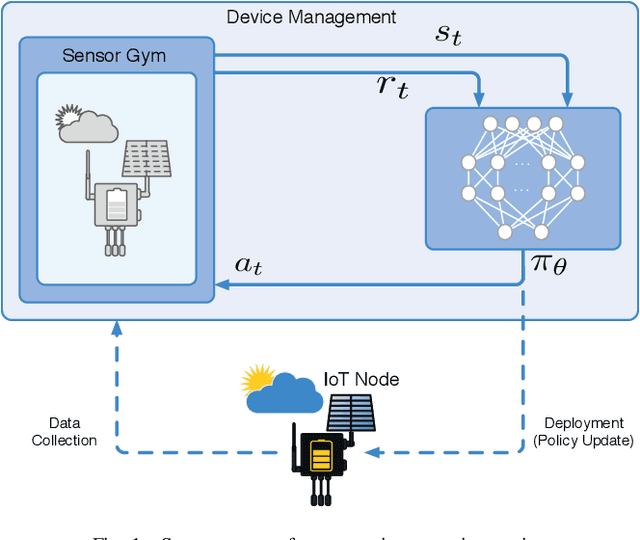
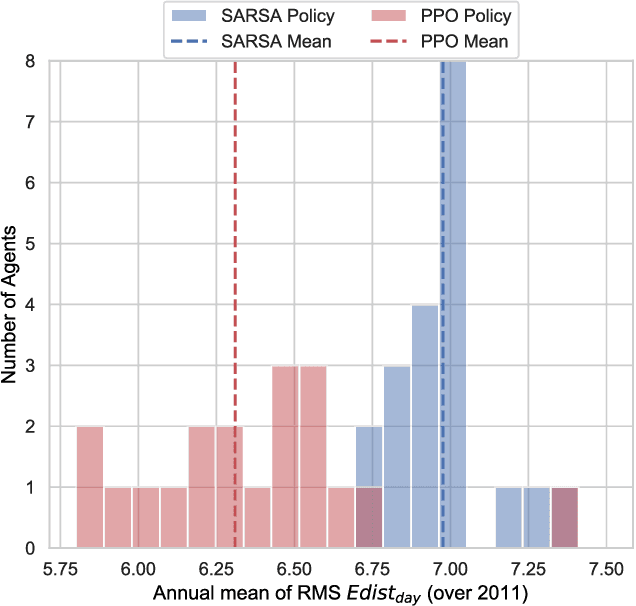
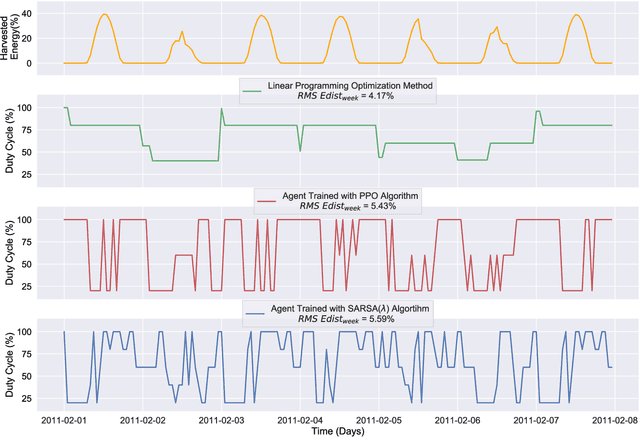
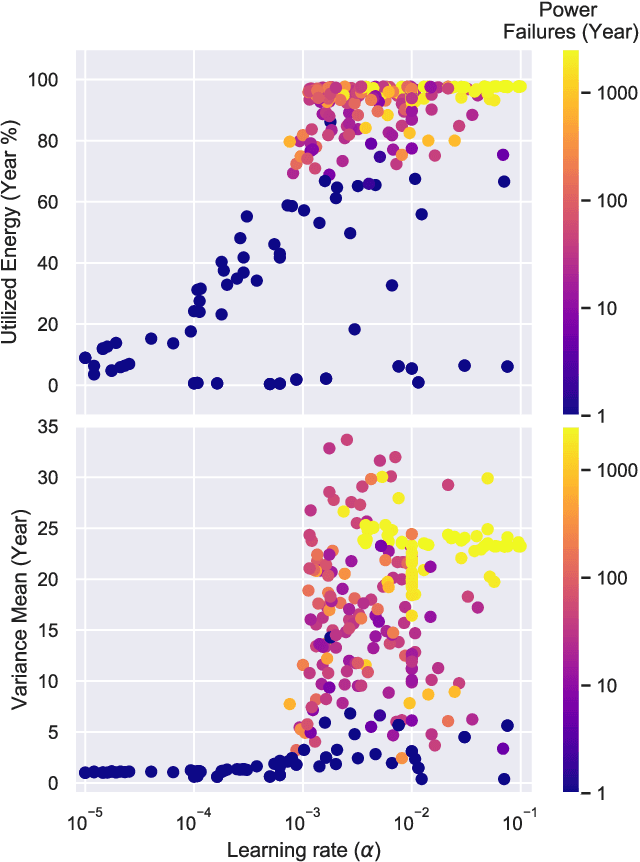
Reinforcement learning (RL) is capable of managing wireless, energy-harvesting IoT nodes by solving the problem of autonomous management in non-stationary, resource-constrained settings. We show that the state-of-the-art policy-gradient approaches to RL are appropriate for the IoT domain and that they outperform previous approaches. Due to the ability to model continuous observation and action spaces, as well as improved function approximation capability, the new approaches are able to solve harder problems, permitting reward functions that are better aligned with the actual application goals. We show such a reward function and use policy-gradient approaches to learn capable policies, leading to behavior more appropriate for IoT nodes with less manual design effort, increasing the level of autonomy in IoT.