 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Catastrophic Forgetting and Remembering in Continual Learning with Optimal Relevance Mapping
Feb 22, 2021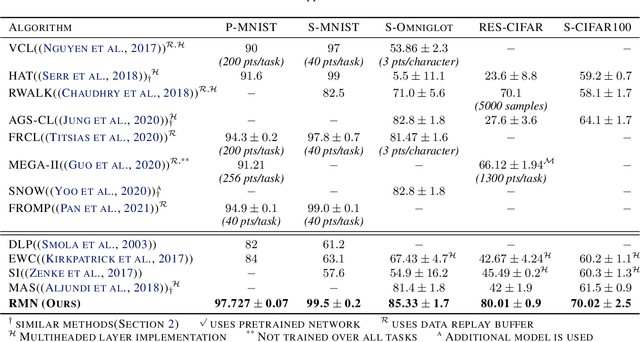
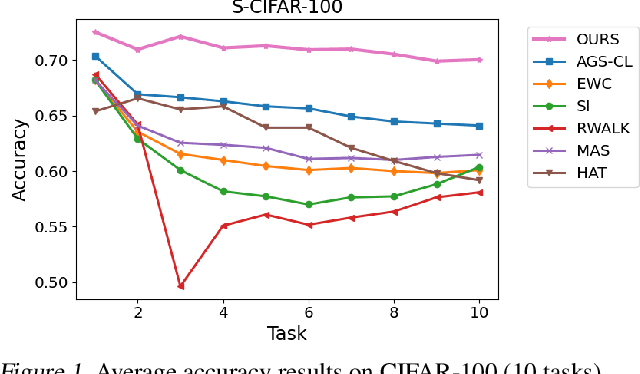

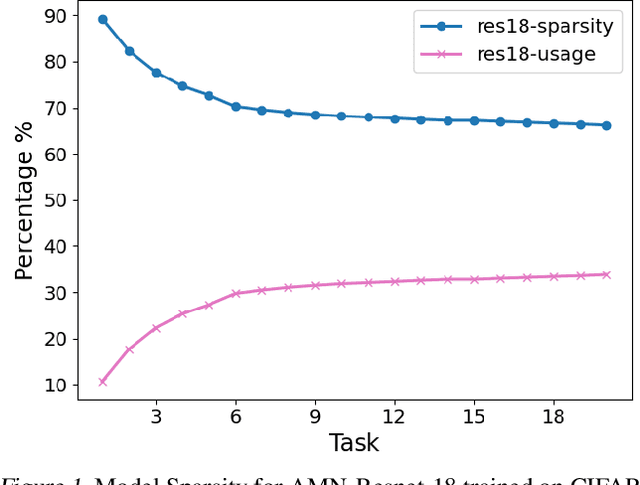
Catastrophic forgetting in neural networks is a significant problem for continual learning. A majority of the current methods replay previous data during training, which violates the constraints of an ideal continual learning system. Additionally, current approaches that deal with forgetting ignore the problem of catastrophic remembering, i.e. the worsening ability to discriminate between data from different tasks. In our work, we introduce Relevance Mapping Networks (RMNs) which are inspired by the Optimal Overlap Hypothesis. The mappings reflects the relevance of the weights for the task at hand by assigning large weights to essential parameters. We show that RMNs learn an optimized representational overlap that overcomes the twin problem of catastrophic forgetting and remembering. Our approach achieves state-of-the-art performance across all common continual learning datasets, even significantly outperforming data replay methods while not violating the constraints for an ideal continual learning system. Moreover, RMNs retain the ability to detect data from new tasks in an unsupervised manner, thus proving their resilience against catastrophic remembering.
Deep Neural Networks Abstract Like Humans
May 27, 2019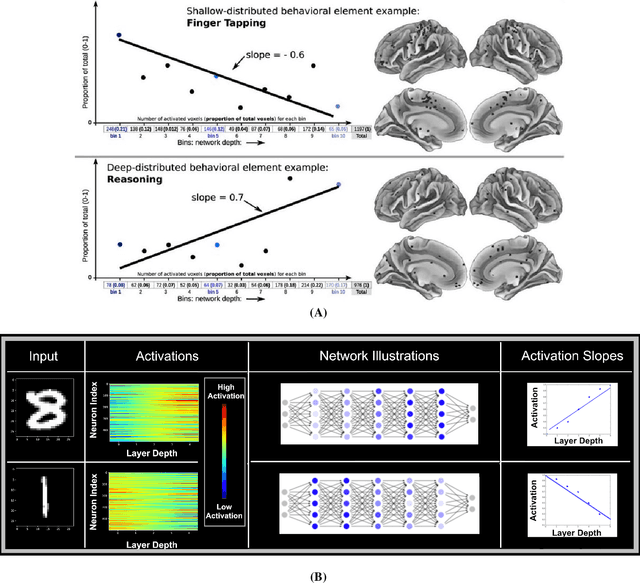
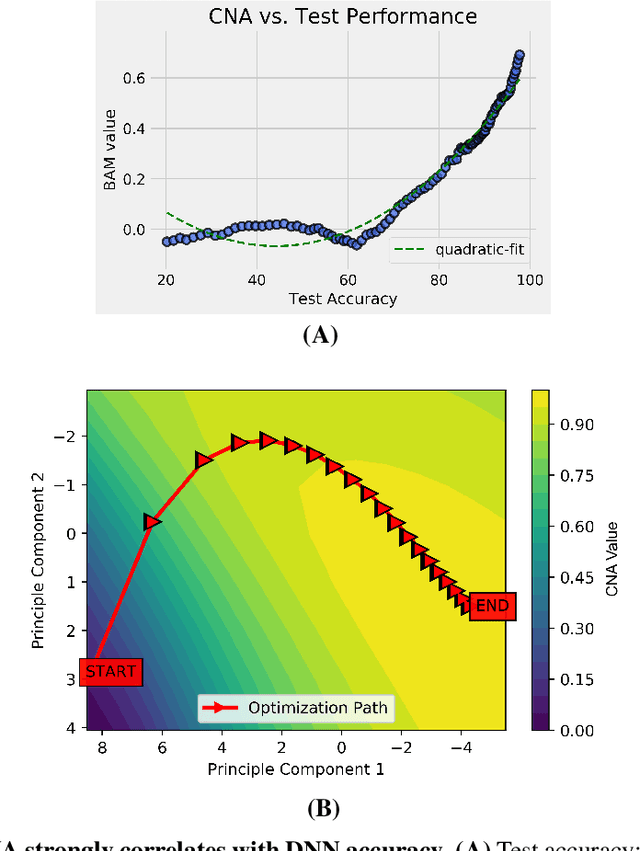
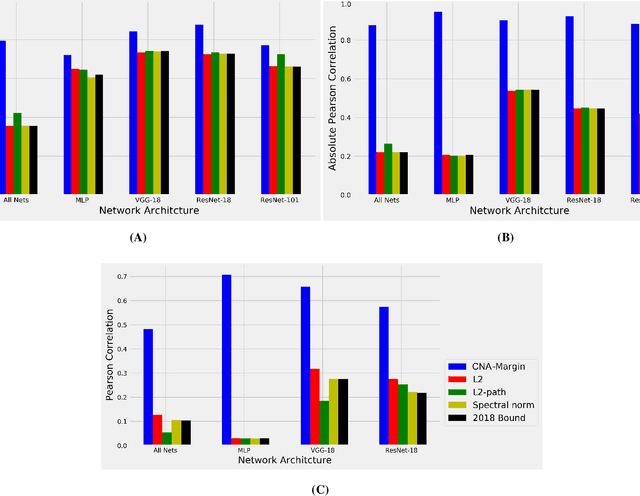
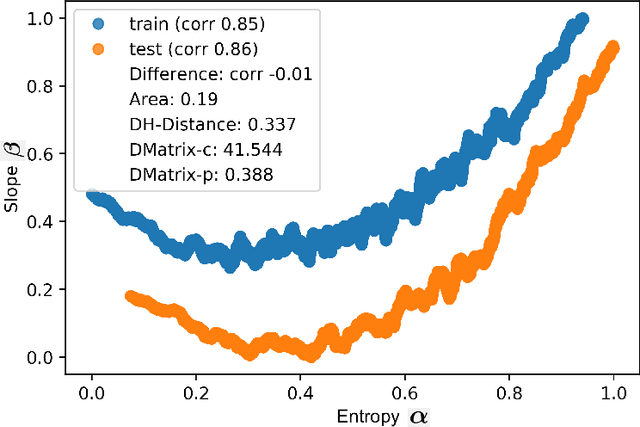
Deep neural networks (DNNs) have revolutionized AI due to their remarkable performance in pattern recognition, comprising of both memorizing complex training sets and demonstrating intelligence by generalizing to previously unseen data (test sets). The high generalization performance in DNNs has been explained by several mathematical tools, including optimization, information theory, and resilience analysis. In humans, it is the ability to abstract concepts from examples that facilitates generalization; this paper thus researches DNN generalization from that perspective. A recent computational neuroscience study revealed a correlation between abstraction and particular neural firing patterns. We express these brain patterns in a closed-form mathematical expression, termed the `Cognitive Neural Activation metric' (CNA) and apply it to DNNs. Our findings reveal parallels in the mechanism underlying abstraction in DNNs and those in the human brain. Beyond simply measuring similarity to human abstraction, the CNA is able to predict and rate how well a DNN will perform on test sets, and determines the best network architectures for a given task in a manner not possible with extant tools. These results were validated on a broad range of datasets (including ImageNet and random labeled datasets) and neural architectures.
Compressing GANs using Knowledge Distillation
Feb 01, 2019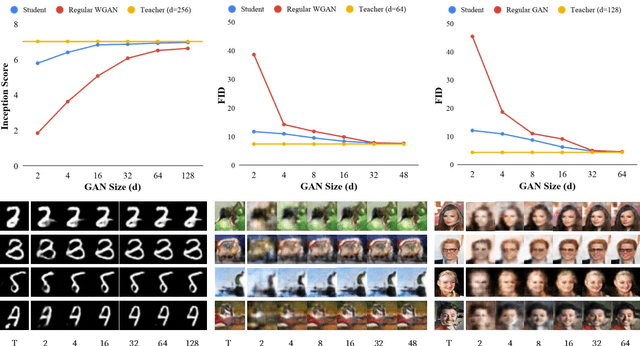
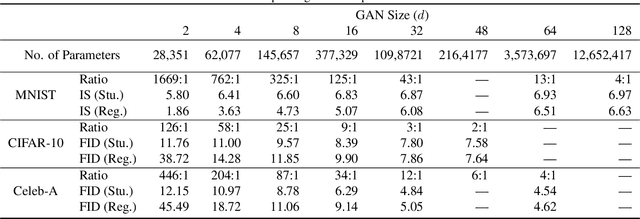
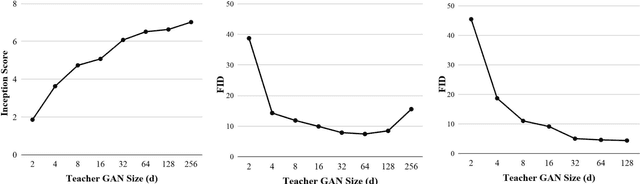
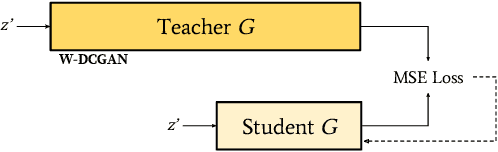
Generative Adversarial Networks (GANs) have been used in several machine learning tasks such as domain transfer, super resolution, and synthetic data generation. State-of-the-art GANs often use tens of millions of parameters, making them expensive to deploy for applications in low SWAP (size, weight, and power) hardware, such as mobile devices, and for applications with real time capabilities. There has been no work found to reduce the number of parameters used in GANs. Therefore, we propose a method to compress GANs using knowledge distillation techniques, in which a smaller "student" GAN learns to mimic a larger "teacher" GAN. We show that the distillation methods used on MNIST, CIFAR-10, and Celeb-A datasets can compress teacher GANs at ratios of 1669:1, 58:1, and 87:1, respectively, while retaining the quality of the generated image. From our experiments, we observe a qualitative limit for GAN's compression. Moreover, we observe that, with a fixed parameter budget, compressed GANs outperform GANs trained using standard training methods. We conjecture that this is partially owing to the optimization landscape of over-parameterized GANs which allows efficient training using alternating gradient descent. Thus, training an over-parameterized GAN followed by our proposed compression scheme provides a high quality generative model with a small number of parameters.