 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Vulnerability Transcends Computational Paradigms: Feature Engineering Provides No Defense Against Neural Adversarial Transfer
Jan 29, 2026Deep neural networks are vulnerable to adversarial examples--inputs with imperceptible perturbations causing misclassification. While adversarial transfer within neural networks is well-documented, whether classical ML pipelines using handcrafted features inherit this vulnerability when attacked via neural surrogates remains unexplored. Feature engineering creates information bottlenecks through gradient quantization and spatial binning, potentially filtering high-frequency adversarial signals. We evaluate this hypothesis through the first comprehensive study of adversarial transfer from DNNs to HOG-based classifiers. Using VGG16 as a surrogate, we generate FGSM and PGD adversarial examples and test transfer to four classical classifiers (KNN, Decision Tree, Linear SVM, Kernel SVM) and a shallow neural network across eight HOG configurations on CIFAR-10. Our results strongly refute the protective hypothesis: all classifiers suffer 16.6%-59.1% relative accuracy drops, comparable to neural-to-neural transfer. More surprisingly, we discover attack hierarchy reversal--contrary to patterns where iterative PGD dominates FGSM within neural networks, FGSM causes greater degradation than PGD in 100% of classical ML cases, suggesting iterative attacks overfit to surrogate-specific features that don't survive feature extraction. Block normalization provides partial but insufficient mitigation. These findings demonstrate that adversarial vulnerability is not an artifact of end-to-end differentiability but a fundamental property of image classification systems, with implications for security-critical deployments across computational paradigms.
Mull-Tokens: Modality-Agnostic Latent Thinking
Dec 11, 2025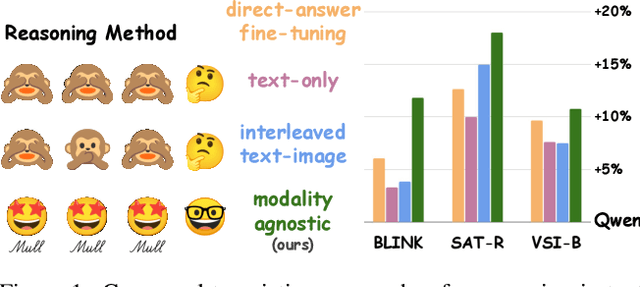
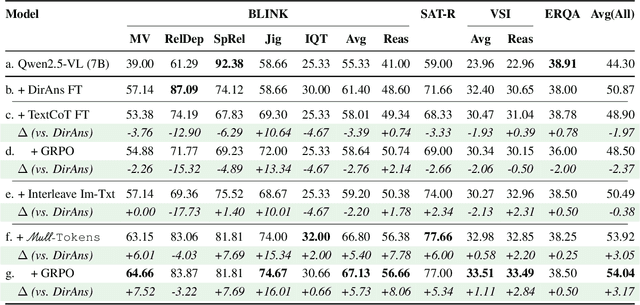
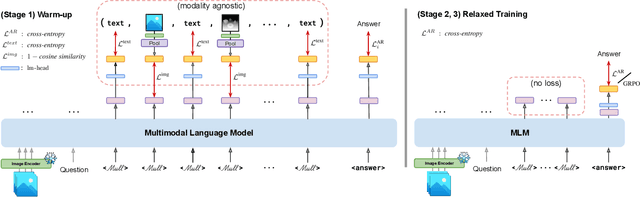
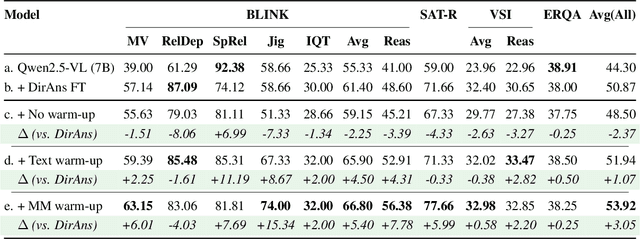
Reasoning goes beyond language; the real world requires reasoning about space, time, affordances, and much more that words alone cannot convey. Existing multimodal models exploring the potential of reasoning with images are brittle and do not scale. They rely on calling specialist tools, costly generation of images, or handcrafted reasoning data to switch between text and image thoughts. Instead, we offer a simpler alternative -- Mull-Tokens -- modality-agnostic latent tokens pre-trained to hold intermediate information in either image or text modalities to let the model think free-form towards the correct answer. We investigate best practices to train Mull-Tokens inspired by latent reasoning frameworks. We first train Mull-Tokens using supervision from interleaved text-image traces, and then fine-tune without any supervision by only using the final answers. Across four challenging spatial reasoning benchmarks involving tasks such as solving puzzles and taking different perspectives, we demonstrate that Mull-Tokens improve upon several baselines utilizing text-only reasoning or interleaved image-text reasoning, achieving a +3% average improvement and up to +16% on a puzzle solving reasoning-heavy split compared to our strongest baseline. Adding to conversations around challenges in grounding textual and visual reasoning, Mull-Tokens offers a simple solution to abstractly think in multiple modalities.
The Intrinsic Dimension of Images and Its Impact on Learning
Apr 18, 2021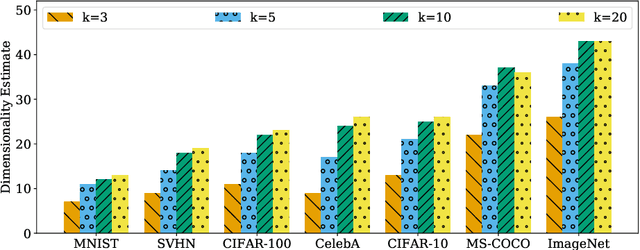



It is widely believed that natural image data exhibits low-dimensional structure despite the high dimensionality of conventional pixel representations. This idea underlies a common intuition for the remarkable success of deep learning in computer vision. In this work, we apply dimension estimation tools to popular datasets and investigate the role of low-dimensional structure in deep learning. We find that common natural image datasets indeed have very low intrinsic dimension relative to the high number of pixels in the images. Additionally, we find that low dimensional datasets are easier for neural networks to learn, and models solving these tasks generalize better from training to test data. Along the way, we develop a technique for validating our dimension estimation tools on synthetic data generated by GANs allowing us to actively manipulate the intrinsic dimension by controlling the image generation process. Code for our experiments may be found here https://github.com/ppope/dimensions.
Detection as Regression: Certified Object Detection by Median Smoothing
Jul 07, 2020
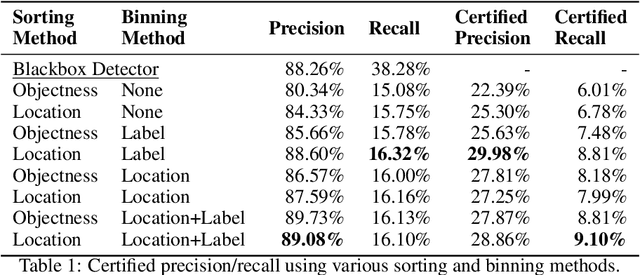

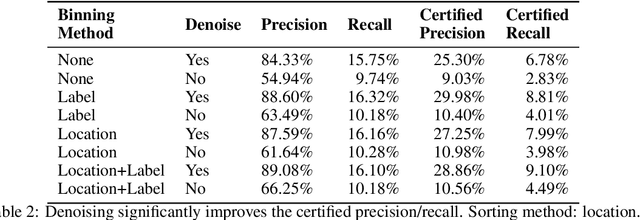
Despite the vulnerability of object detectors to adversarial attacks, very few defenses are known to date. While adversarial training can improve the empirical robustness of image classifiers, a direct extension to object detection is very expensive. This work is motivated by recent progress on certified classification by randomized smoothing. We start by presenting a reduction from object detection to a regression problem. Then, to enable certified regression, where standard mean smoothing fails, we propose median smoothing, which is of independent interest. We obtain the first model-agnostic, training-free, and certified defense for object detection against $\ell_2$-bounded attacks.
Headless Horseman: Adversarial Attacks on Transfer Learning Models
Apr 20, 2020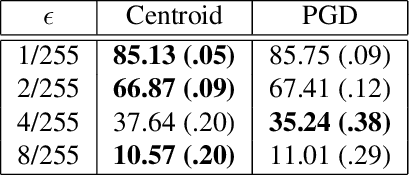
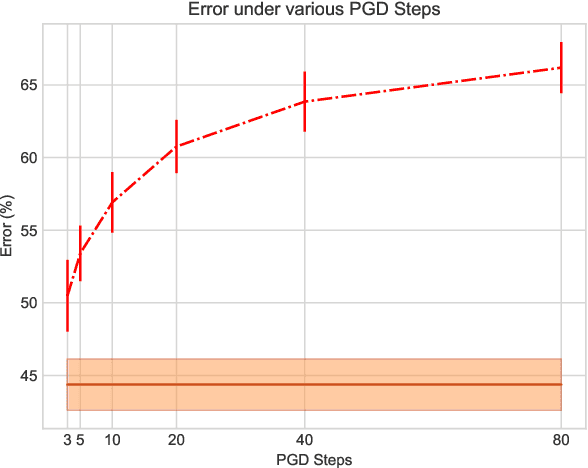
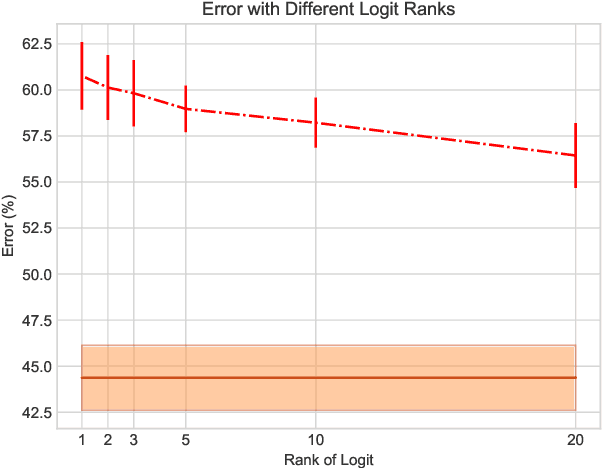
Transfer learning facilitates the training of task-specific classifiers using pre-trained models as feature extractors. We present a family of transferable adversarial attacks against such classifiers, generated without access to the classification head; we call these \emph{headless attacks}. We first demonstrate successful transfer attacks against a victim network using \textit{only} its feature extractor. This motivates the introduction of a label-blind adversarial attack. This transfer attack method does not require any information about the class-label space of the victim. Our attack lowers the accuracy of a ResNet18 trained on CIFAR10 by over 40\%.
Certified Defenses for Adversarial Patches
Mar 14, 2020

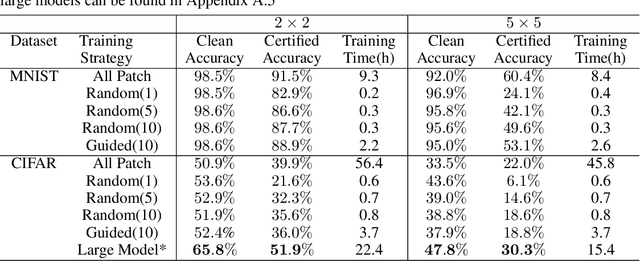
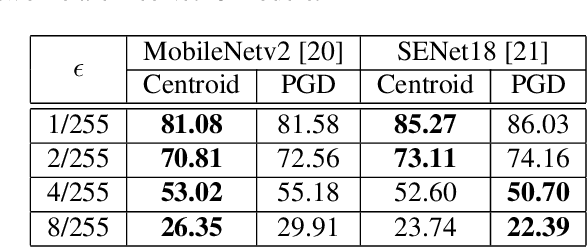
Adversarial patch attacks are among one of the most practical threat models against real-world computer vision systems. This paper studies certified and empirical defenses against patch attacks. We begin with a set of experiments showing that most existing defenses, which work by pre-processing input images to mitigate adversarial patches, are easily broken by simple white-box adversaries. Motivated by this finding, we propose the first certified defense against patch attacks, and propose faster methods for its training. Furthermore, we experiment with different patch shapes for testing, obtaining surprisingly good robustness transfer across shapes, and present preliminary results on certified defense against sparse attacks. Our complete implementation can be found on: https://github.com/Ping-C/certifiedpatchdefense.
On Realistic Target Coverage by Autonomous Drones
Sep 05, 2018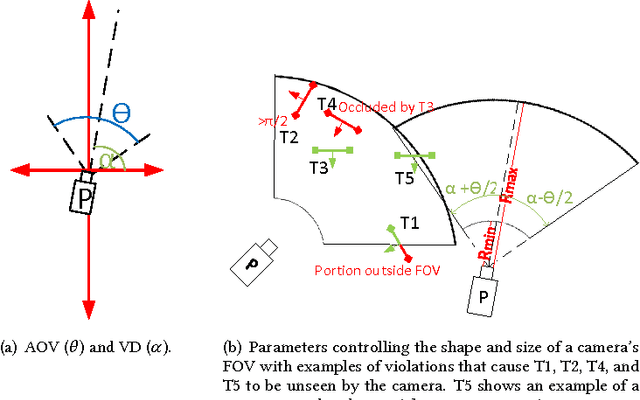
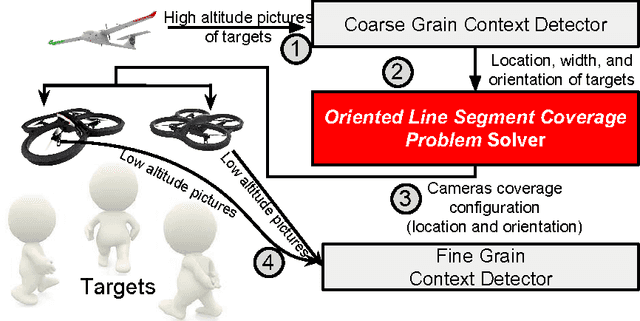
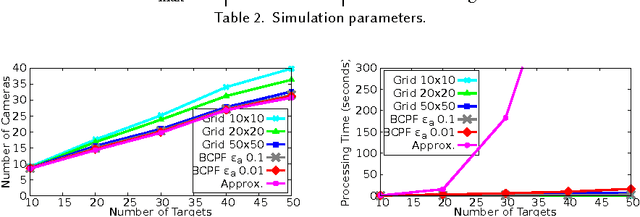
Low-cost mini-drones with advanced sensing and maneuverability enable a new class of intelligent sensing systems. To achieve the full potential of such drones, it is necessary to develop new enhanced formulations of both common and emerging sensing scenarios. Namely, several fundamental challenges in visual sensing remain unsolved including: 1) Fitting sizable targets in camera frames; 2) Effective viewpoints matching target poses; 3) Occlusion by elements in the environment, including other targets. In this paper, we introduce Argus: an autonomous system that utilizes drones to incrementally collect target information through a two-tier architecture. To tackle the stated challenges, Argus employs a novel geometric model that captures both target shapes and coverage constraints. Recognizing drones as the scarcest resource, Argus aims to minimize the number of drones required to cover a set of targets. We prove this problem is NP-hard, and even hard to approximate, before deriving a best-possible approximation algorithm along with a competitive sampling heuristic which runs up to 100x faster according to large-scale simulations. To test Argus in action, we demonstrate and analyze its performance on a prototype implementation. Finally, we present a number of extensions to accommodate more application requirements and highlight some open problems.